
Back


Anonymous 4
Hey I am on Medial • 1y
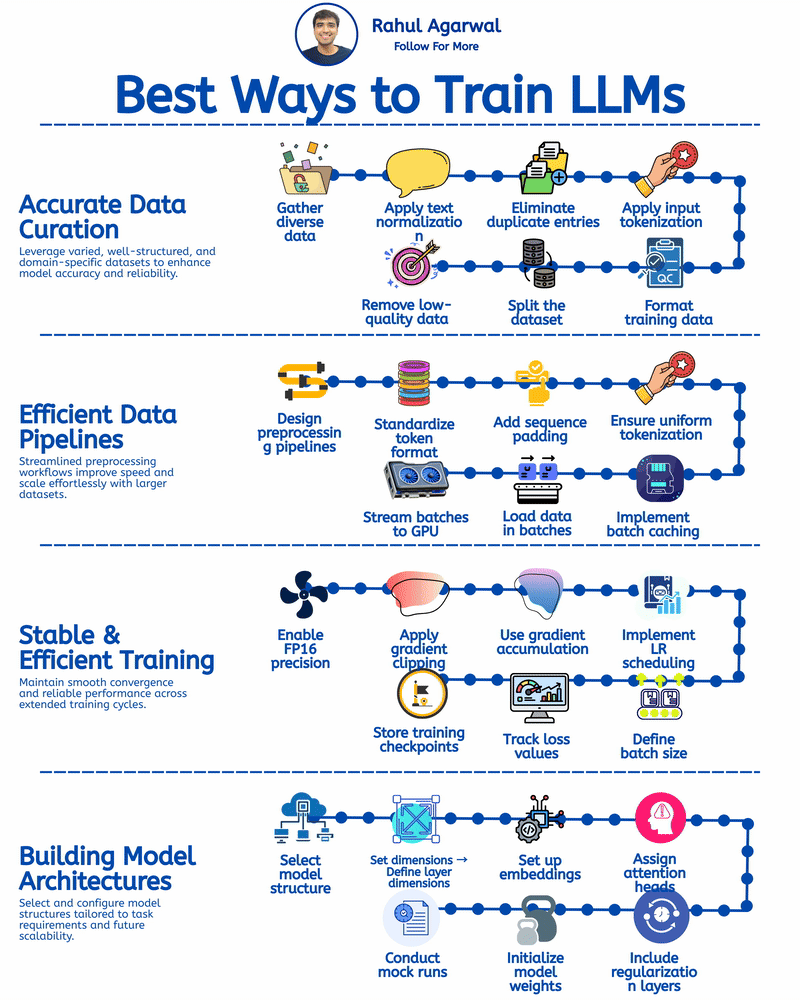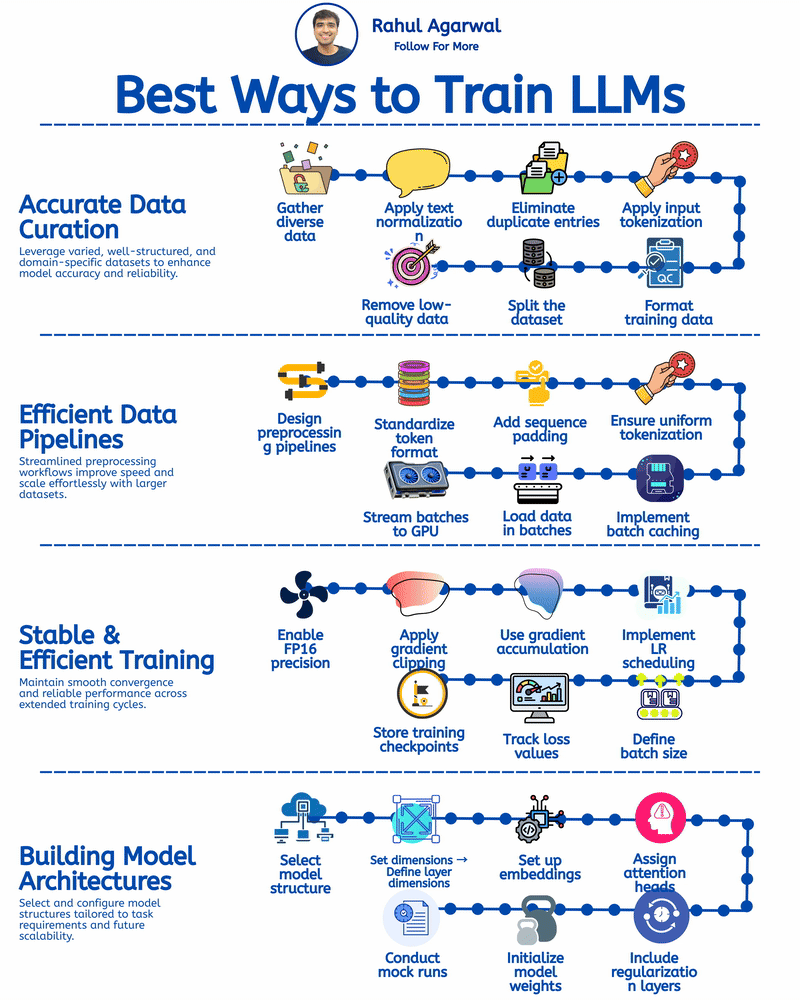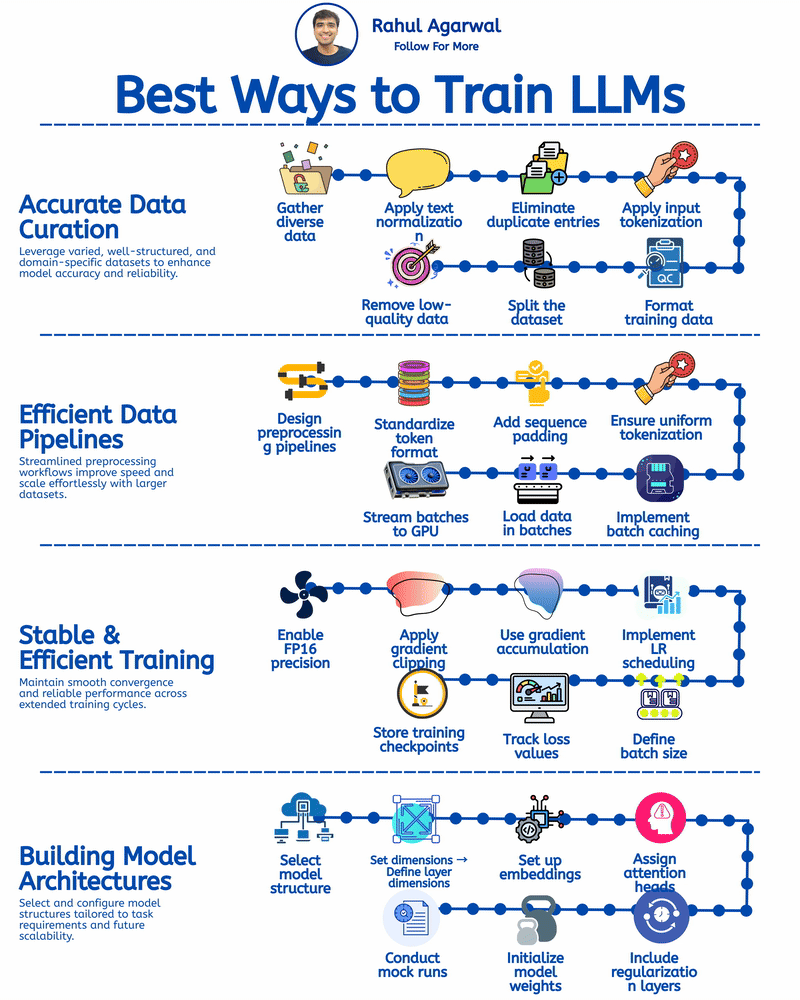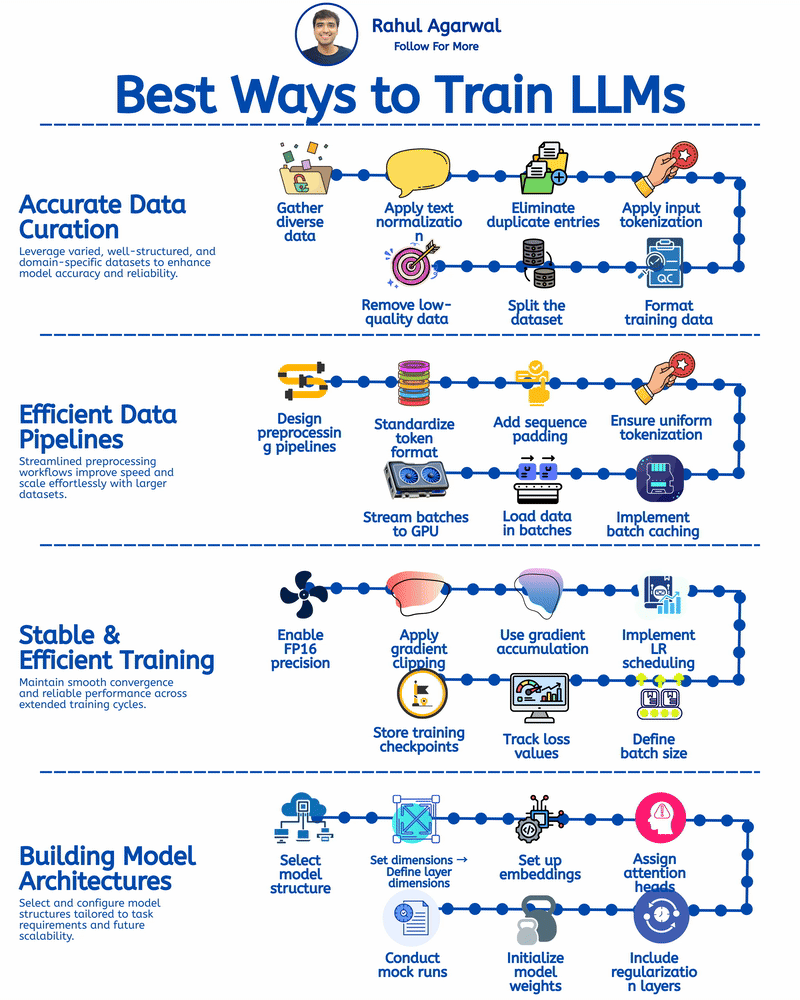
VLMs might be more efficient in the long run, but training them requires a lot of resources. The paper mentions various approaches to training, but without adequate computational power, it's challenging for smaller teams to implement these models. Anyone here with experience on this?
More like this
Recommendations from Medial

Vedant SD
Finance Geek | Conte... • 1y
Day 72: The Art of Scaling: From Startup to Growth Stage Scaling a startup from a small team to a large organization requires careful planning and execution. Here's how Bengaluru entrepreneurs can navigate this growth phase: * Hire the Right People:
See More


Bhoop Singh Gurjar
AI Deep Explorer | f... • 11m
LLM Post-Training: A Deep Dive into Reasoning LLMs This survey paper provides an in-depth examination of post-training methodologies in Large Language Models (LLMs) focusing on improving reasoning capabilities. While LLMs achieve strong performance
See More
Vansh Khandelwal
Full Stack Web Devel... • 3m
Agentic AI—systems that act autonomously, are context-aware and learn in real time—paired with small language models (SLMs) enables efficient, specialized automation. SLMs are lightweight, fast, fine-tunable for niche domains and accessible to smalle
See MoreVansh Khandelwal
Full Stack Web Devel... • 1m
This blog traces Boeing’s decline from a product-first culture to profit-first after 1996 when leadership from McDonnell Douglas shifted priorities. Cost-cutting, stock buybacks, outsourcing and simplified procedures degraded manufacturing and oversi
See More

Farhan Raza
Founder And CEO Give... • 1y
Q: How are you going to implement it in Jhansi? And what about the plans of other cities? Ans: We will implement GiveAt in Jhansi by onboarding local restaurants with eco-friendly packaging materials and providing training for seamless adoption. A d
See MoreBhoop Singh Gurjar
AI Deep Explorer | f... • 1y
"A Survey on Post-Training of Large Language Models" This paper systematically categorizes post-training into five major paradigms: 1. Fine-Tuning 2. Alignment 3. Reasoning Enhancement 4. Efficiency Optimization 5. Integration & Adaptation 1️⃣ Fin
See More
Anonymous
Hey I am on Medial • 1y
One Nation, One Election sounds efficient on paper, but in reality, it undermines democracy and the voice of the people. Combining state and national elections shifts focus away from local issues, allowing national parties to dominate the narrative w
See More
/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)

























Download the medial app to read full posts, comements and news.