
Back

Rahul Agarwal
Founder | Agentic AI... • 4m
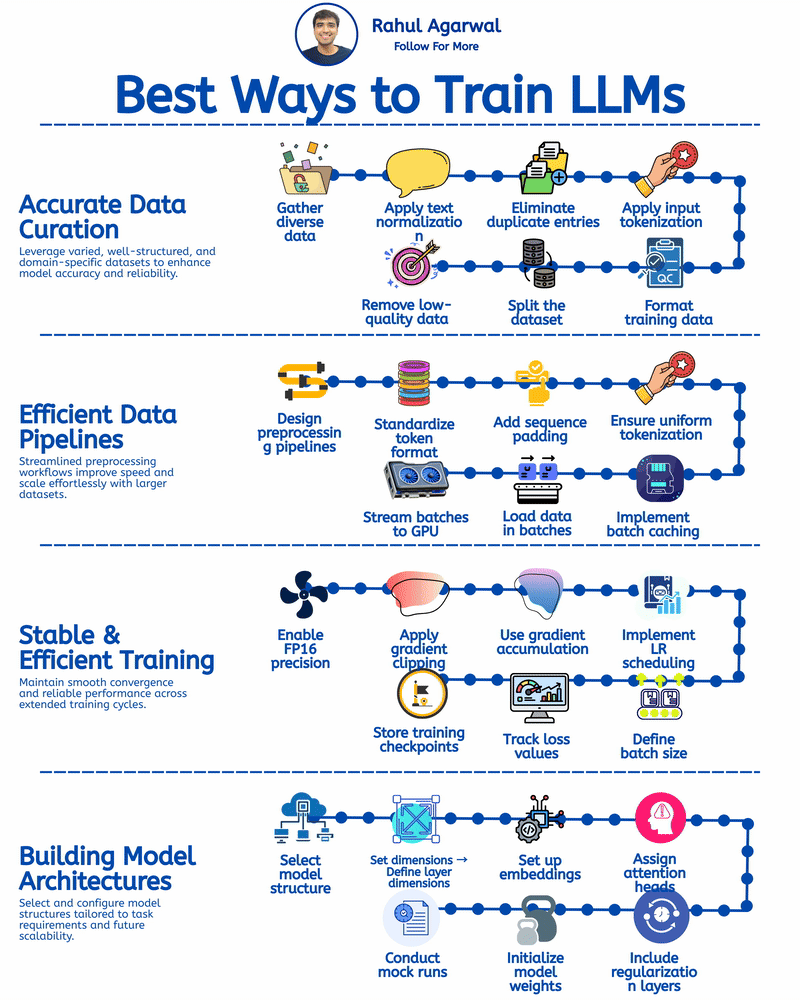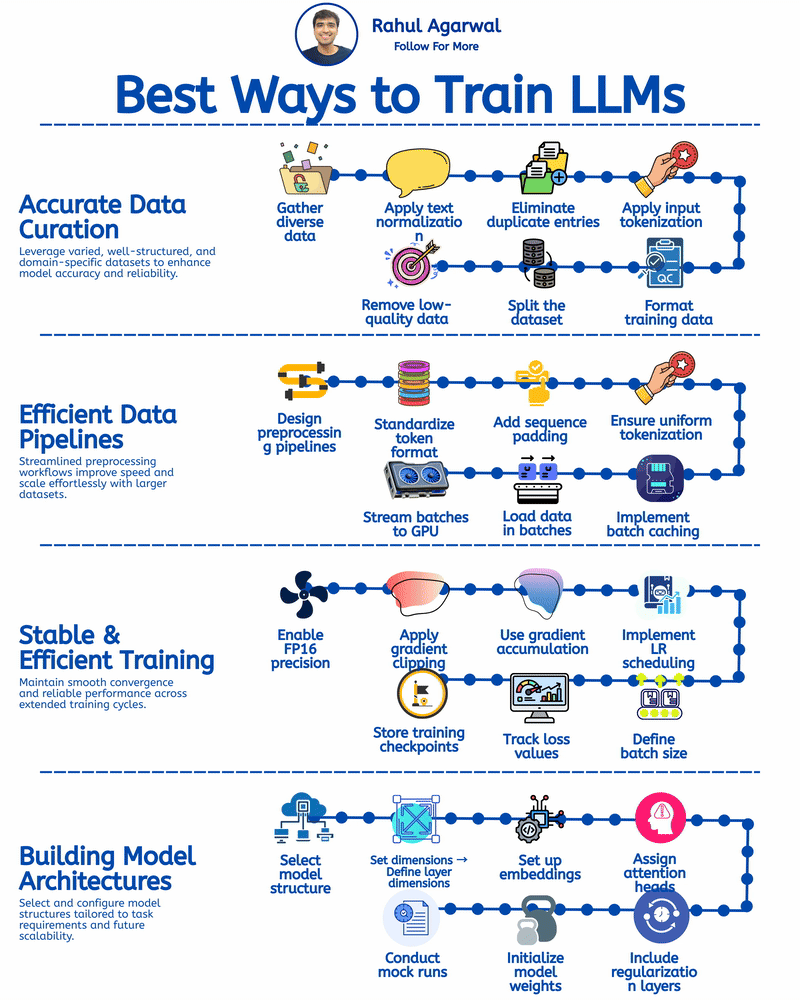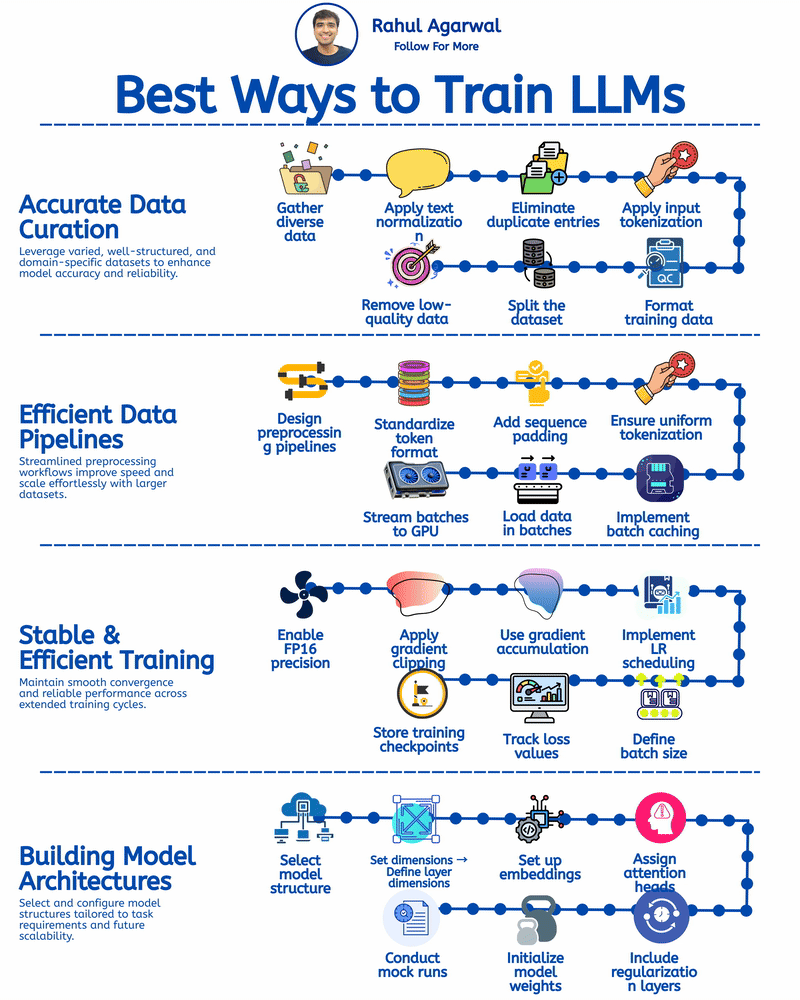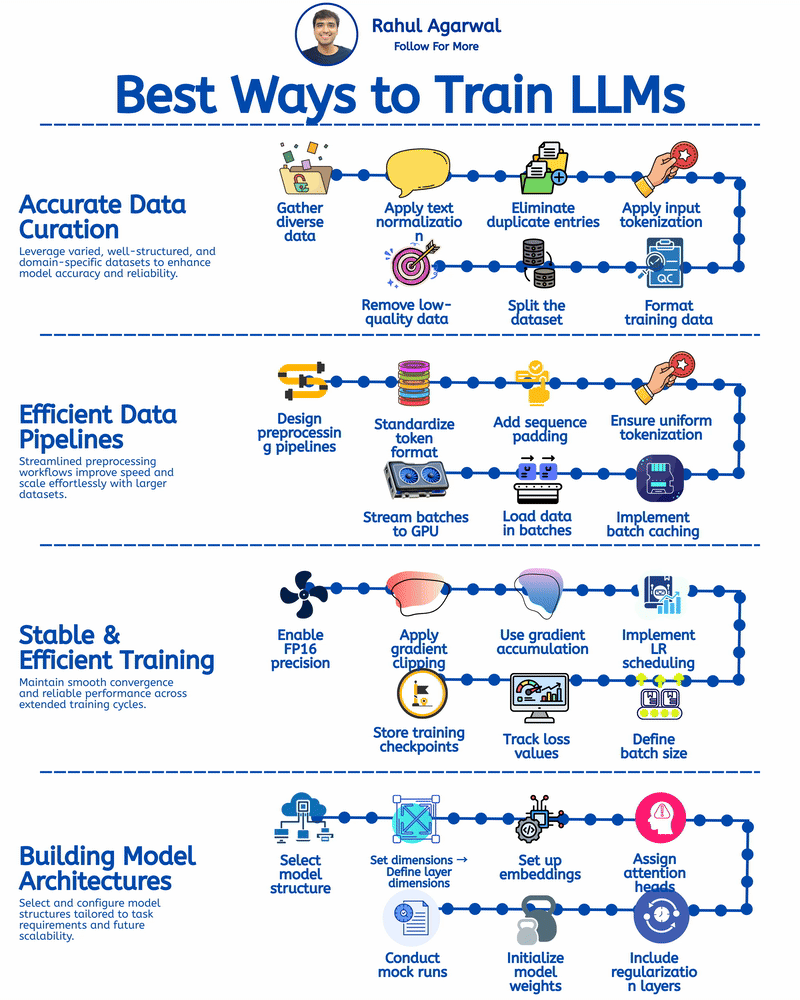
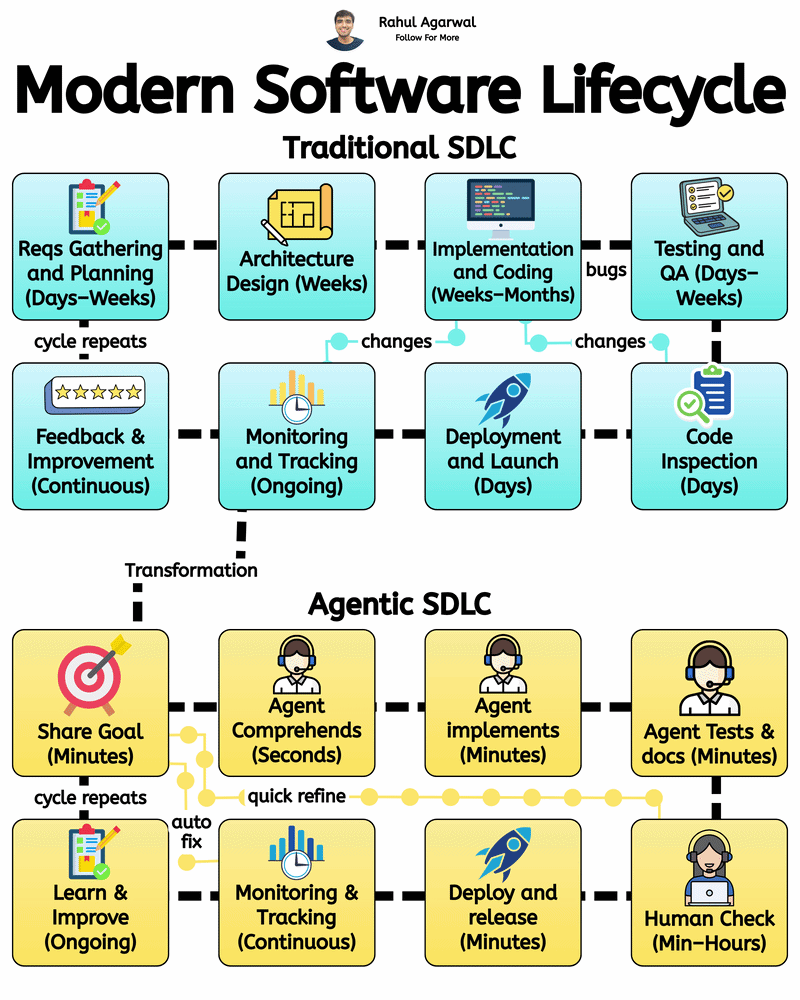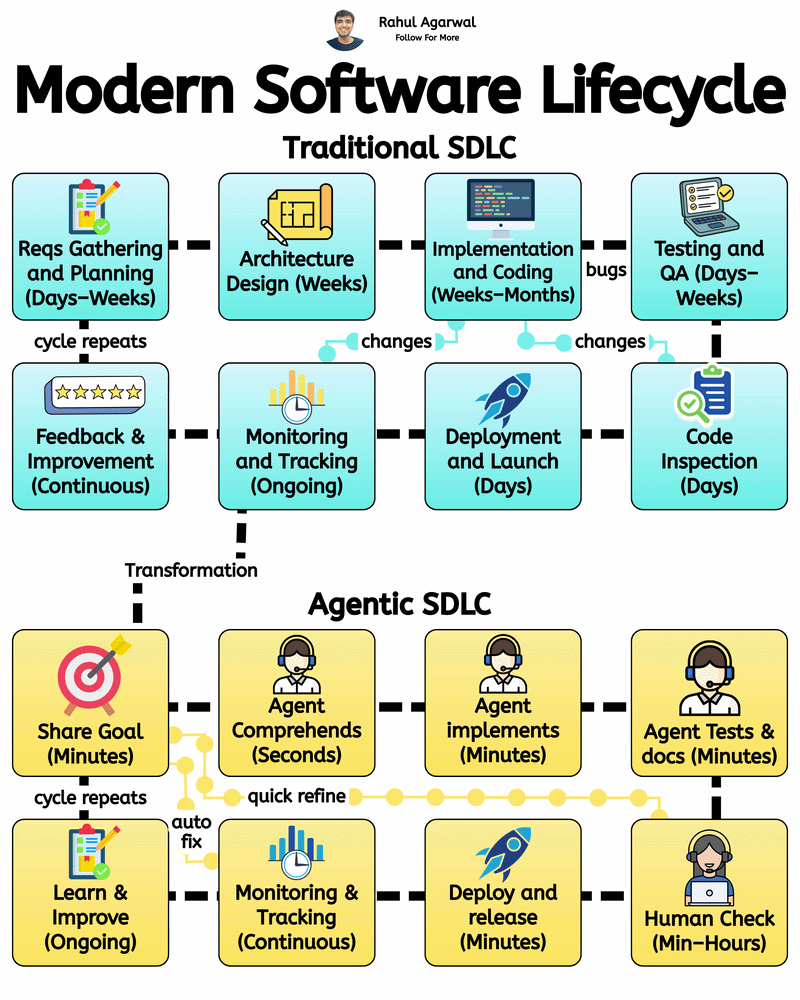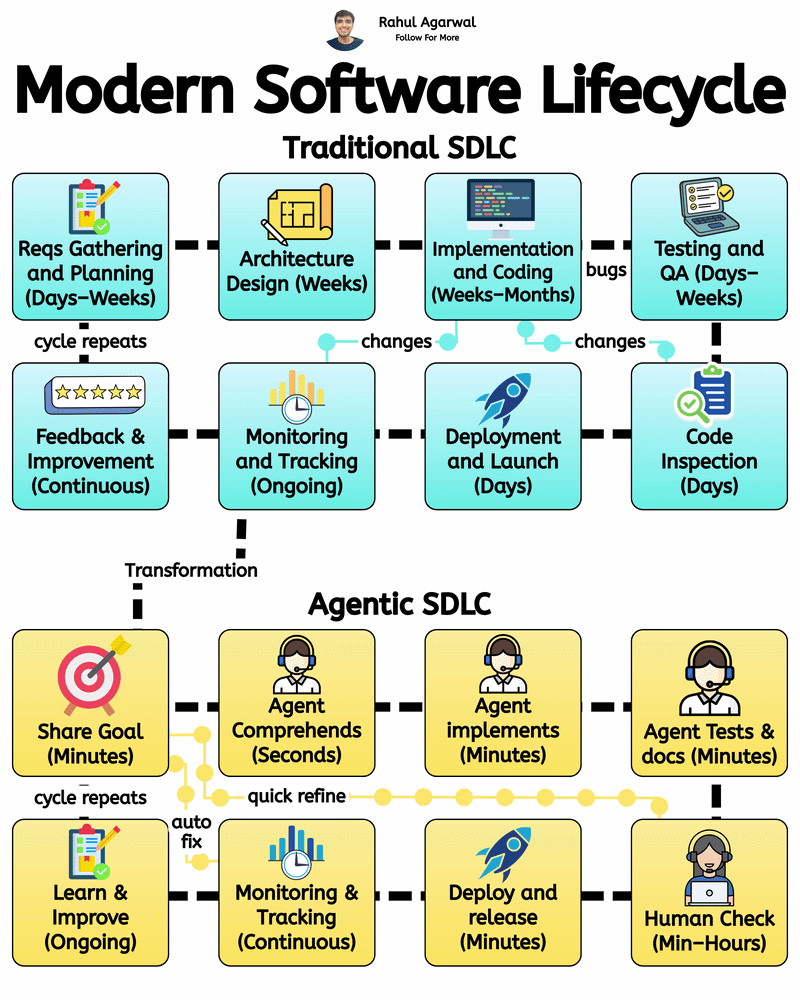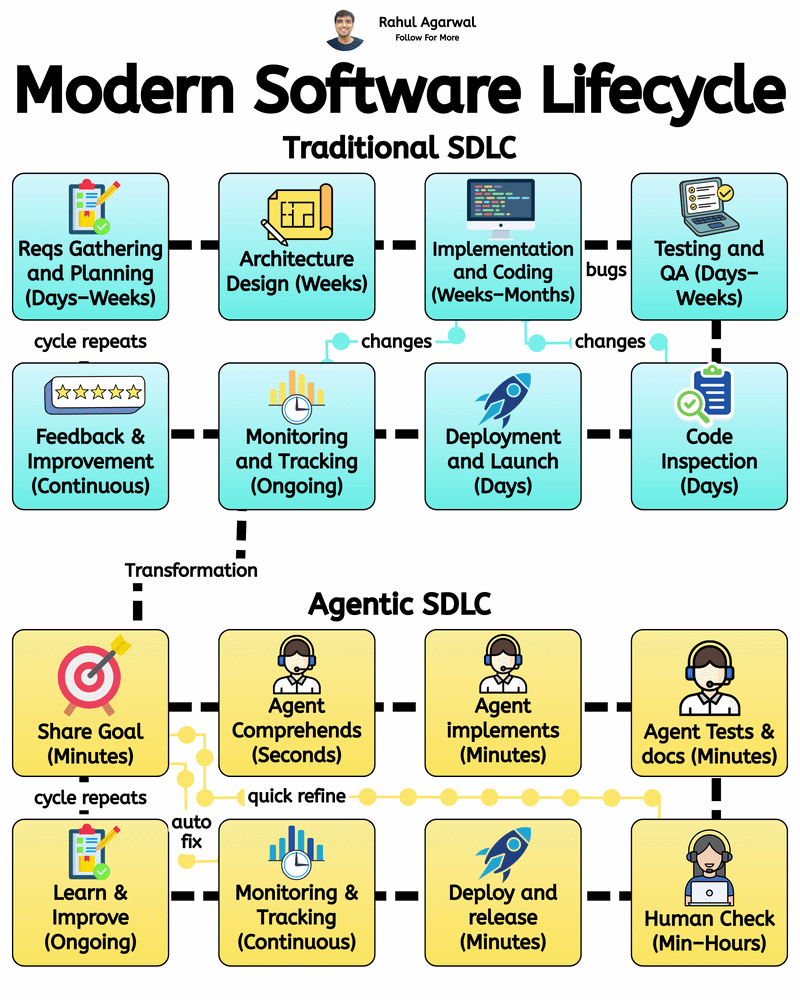
4 different ways of training LLM's. I've given a simple detailed explanation below. 1.) 𝗔𝗰𝗰𝘂𝗿𝗮𝘁𝗲 𝗗𝗮𝘁𝗮 𝗖𝘂𝗿𝗮𝘁𝗶𝗼𝗻 (𝘀𝘁𝗲𝗽-𝗯𝘆-𝘀𝘁𝗲𝗽) Prepares clean, consistent, and useful data so the model learns effectively. 1. Collect text from diverse and reliable domains. 2. Clean and format all text consistently. 3. Remove repeated or identical samples. 4. Convert text into machine-readable tokens. 5. Structure input-output data for training. 6. Split into training, validation, and test sets. 7. Filter out low-quality or irrelevant content. _____________________________________________ 2.) 𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝗗𝗮𝘁𝗮 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 (𝘀𝘁𝗲𝗽-𝗯𝘆-𝘀𝘁𝗲𝗽) Ensures smooth, consistent, and scalable data flow for training. 1. Automate cleaning, tokenizing, and batching. 2. Use one tokenizer setup for all data. 3. Make input lengths consistent for GPU efficiency. 4. Keep tokenization consistent across inputs. 5. Reuse preprocessed data to save time. 6. Feed data into the model in chunks. 7. Send batches directly to GPU for fast training. _____________________________________________ 3.) 𝗦𝘁𝗮𝗯𝗹𝗲 & 𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 (𝘀𝘁𝗲𝗽-𝗯𝘆-𝘀𝘁𝗲𝗽) Keeps training smooth, efficient, and prevents crashes or divergence. 1. Save GPU memory and boost training speed. 2. Prevent exploding gradients during back propagation. 3. Combine updates from smaller batch steps. 4. Adjust the learning rate progressively over epochs. 5. Choose optimal size for memory and performance. 6. Monitor both training and validation loss trends. 7. Save model state regularly to prevent loss. _____________________________________________ 4.) 𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲𝘀 (𝘀𝘁𝗲𝗽-𝗯𝘆-𝘀𝘁𝗲𝗽) Defines the structure and setup of the model for optimal performance. 1. Pick a base architecture (e.g., GPT, Transformer, LLaMA). 2. Set depth, width, and attention sizes. 3. Map tokens into high-dimensional vectors. 4. Specify number for multi-head attention. 5. Add dropout or weight decay modules. 6. Use methods for stable weight starting. 7. Run test passes to validate setup. You can apply these training approaches to build robust, efficient, and scalable LLMs to enable your company to develop powerful AI solutions. ✅ Repost for others in your network who can benefit from this.
More like this
Recommendations from Medial


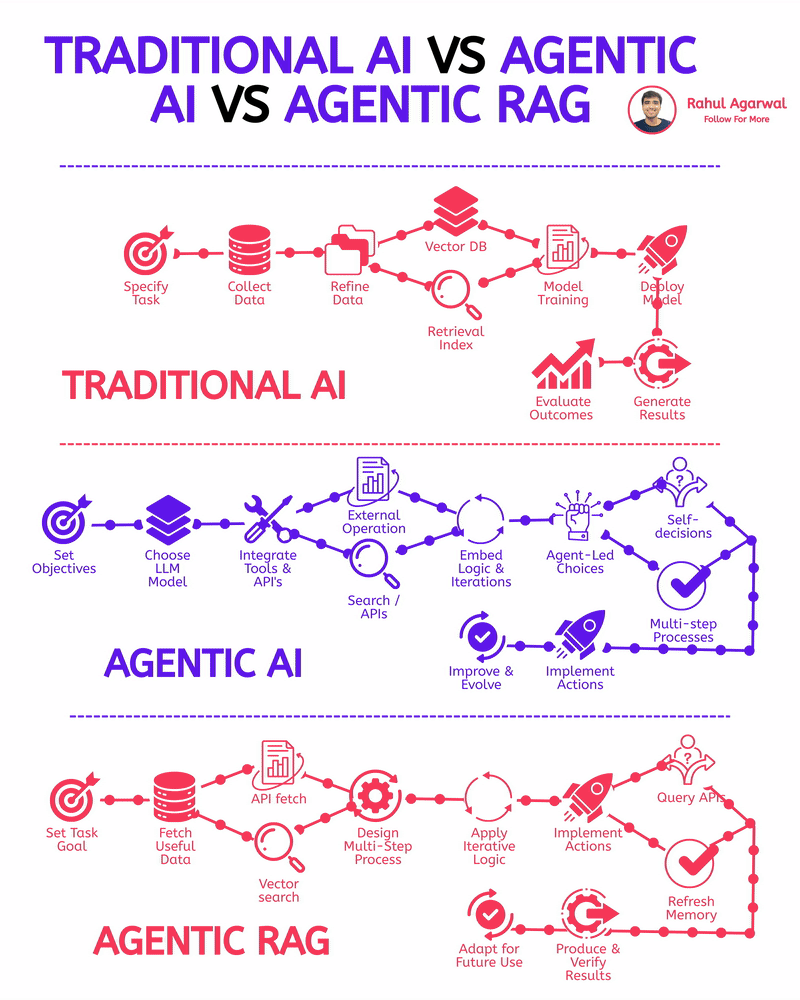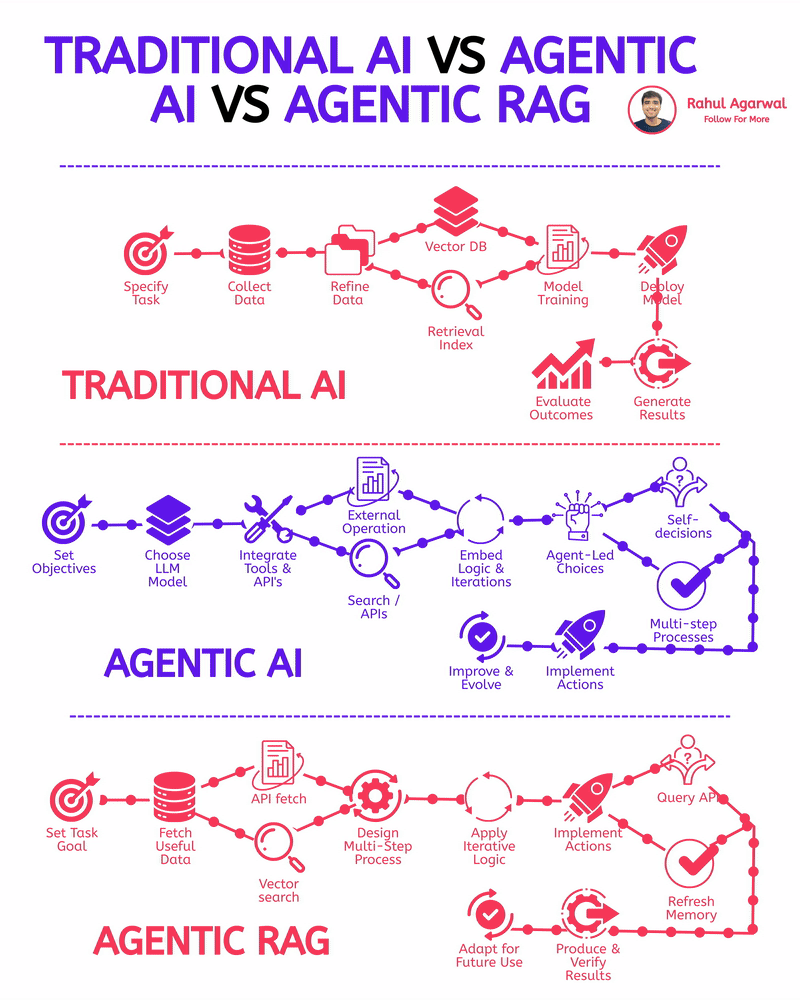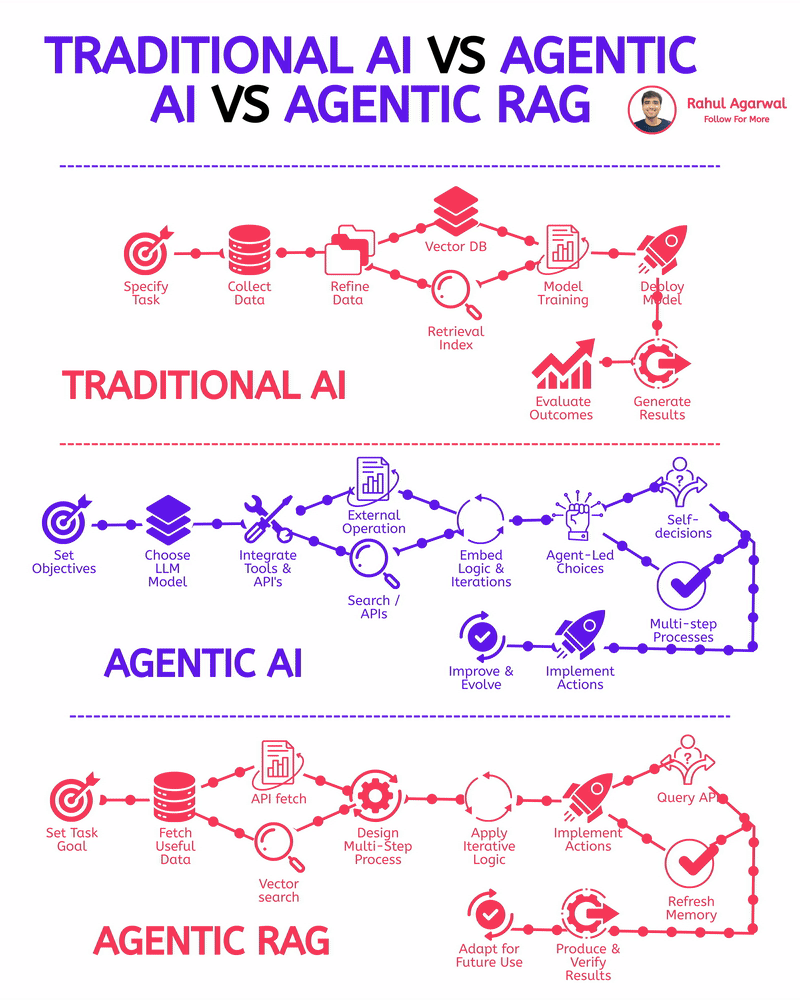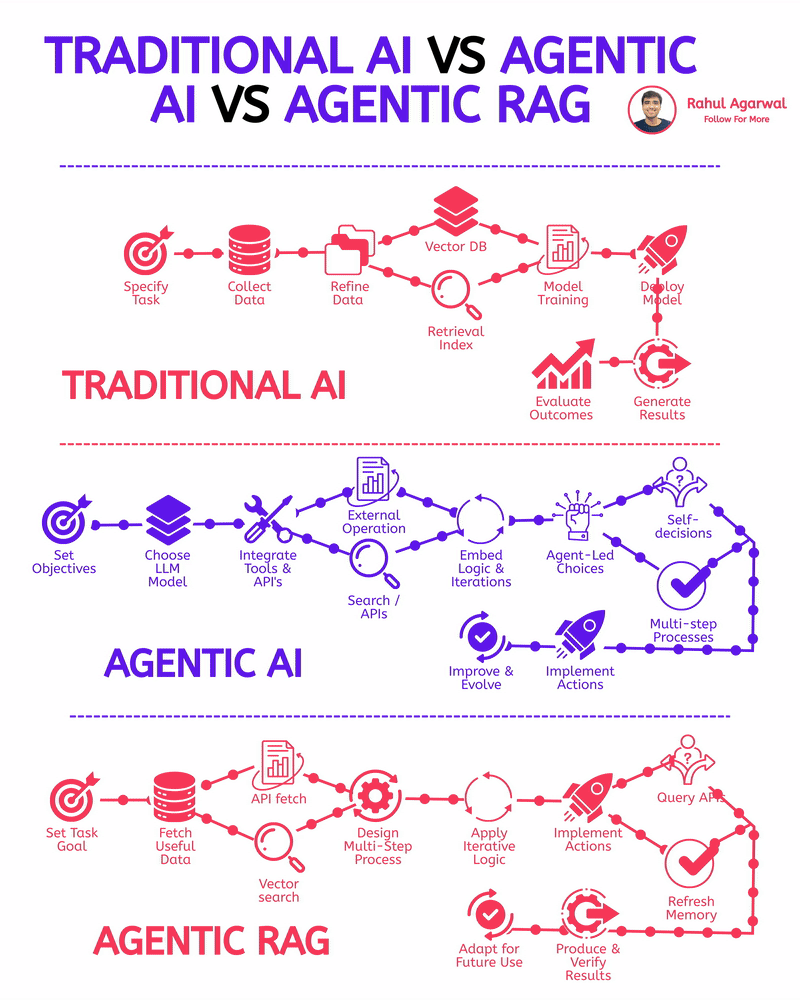



Rahul Agarwal
Founder | Agentic AI... • 2m
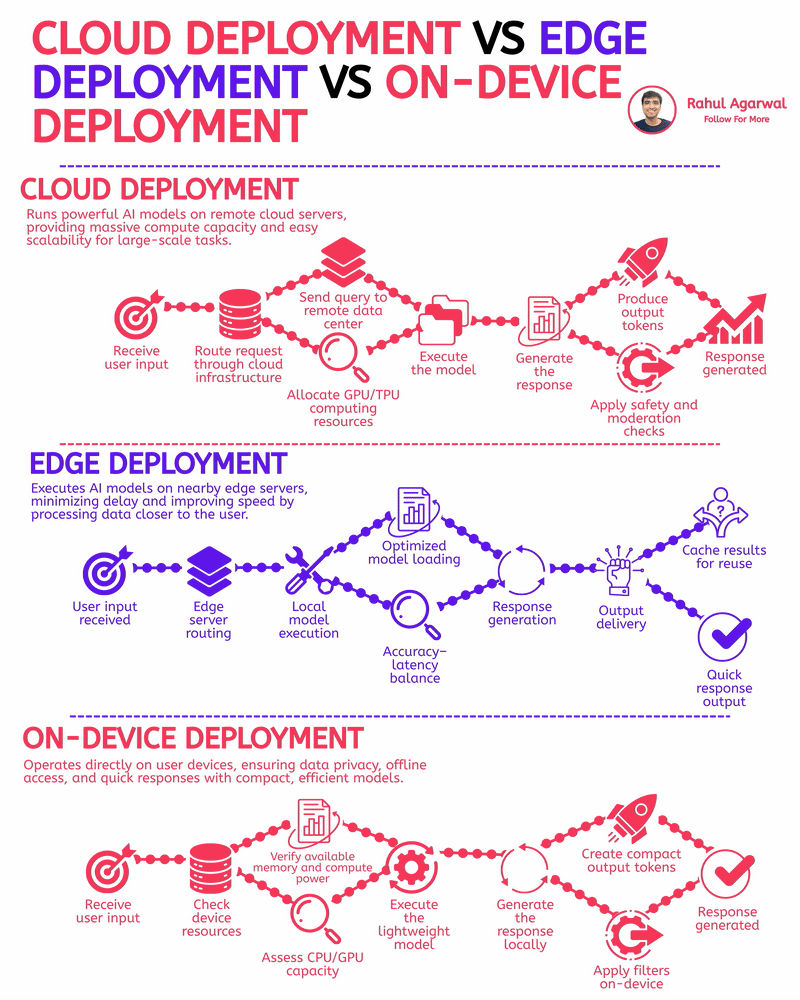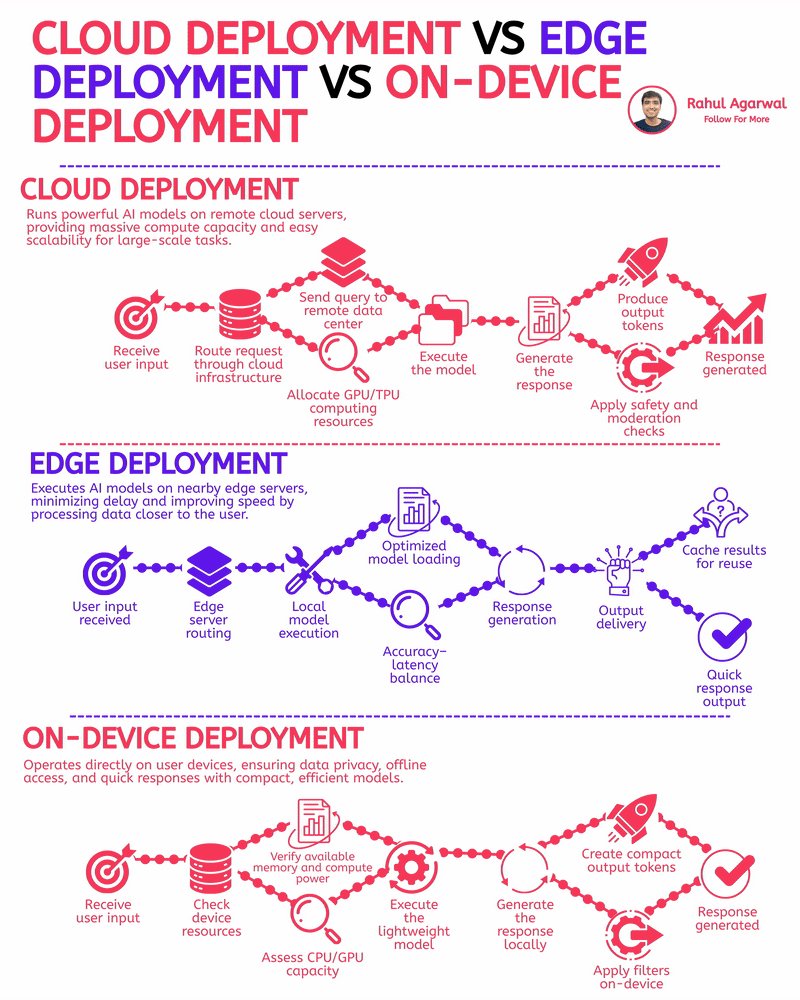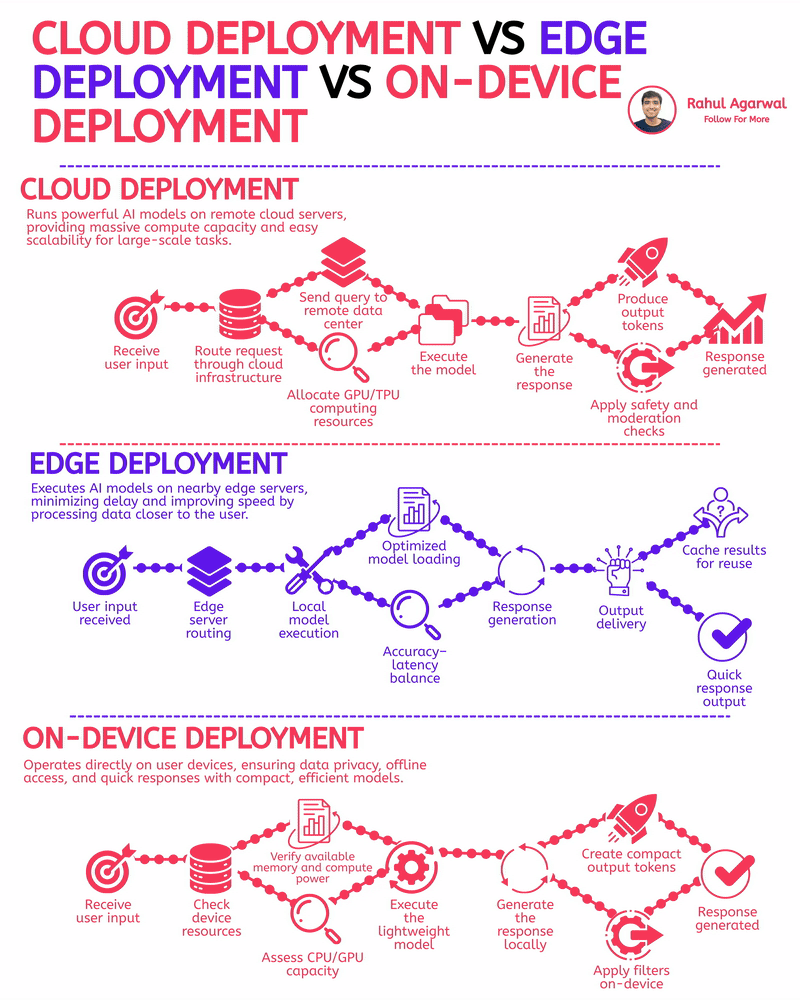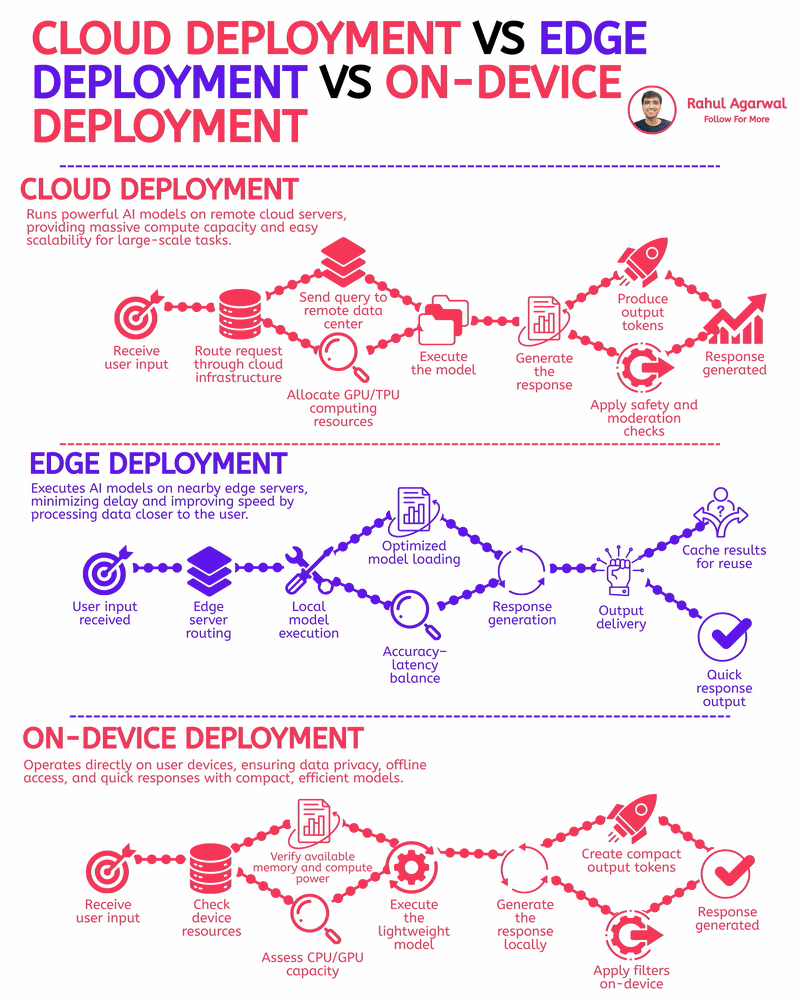
The fastest AI apps aren’t using the cloud. I've explained the reason for this below. Most people think the cloud is the go-to solution for AI, but when speed and real-time results are a must, other deployment options outperform it. 1.) 𝗖𝗹𝗼𝘂𝗱
See More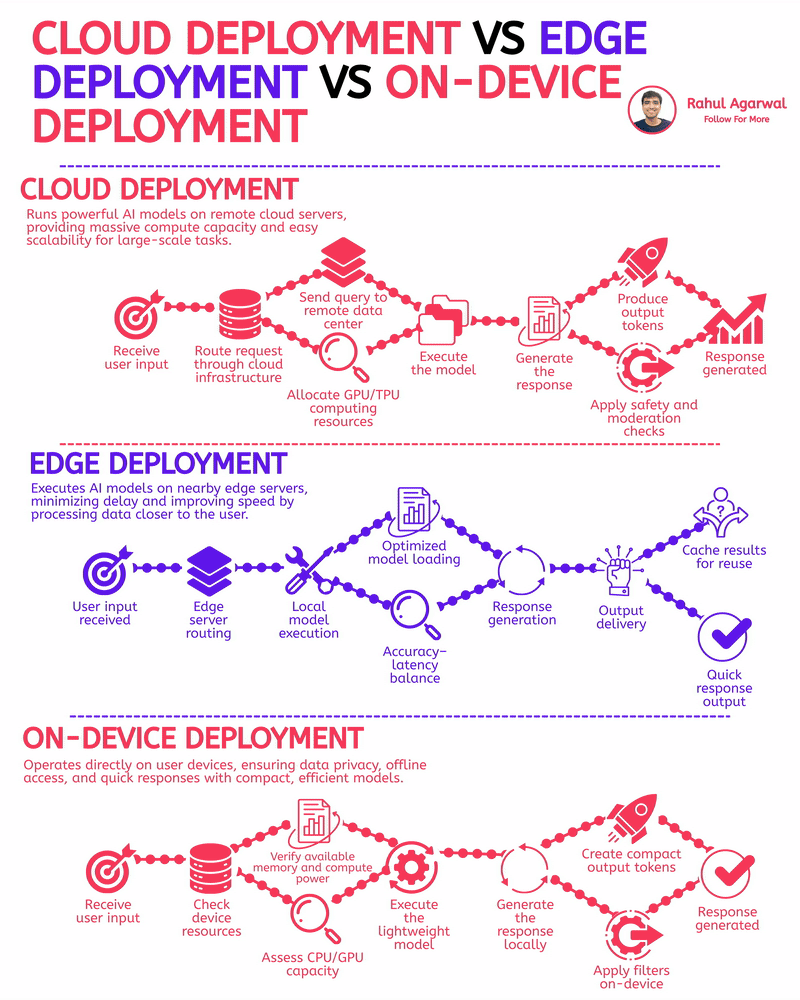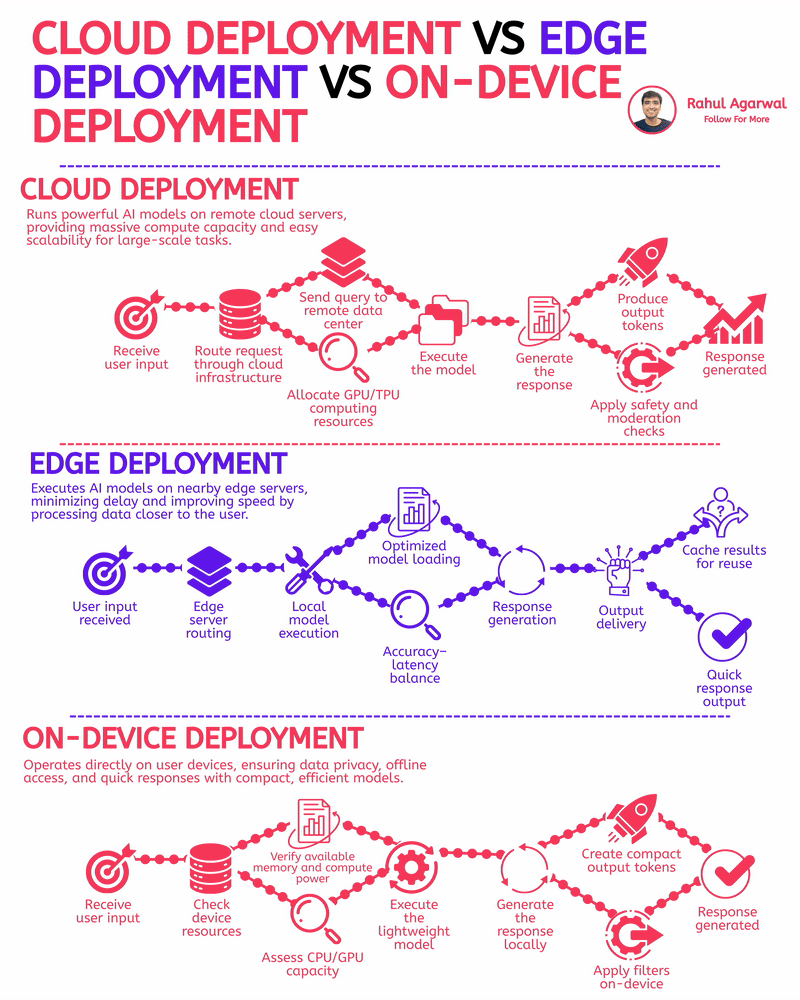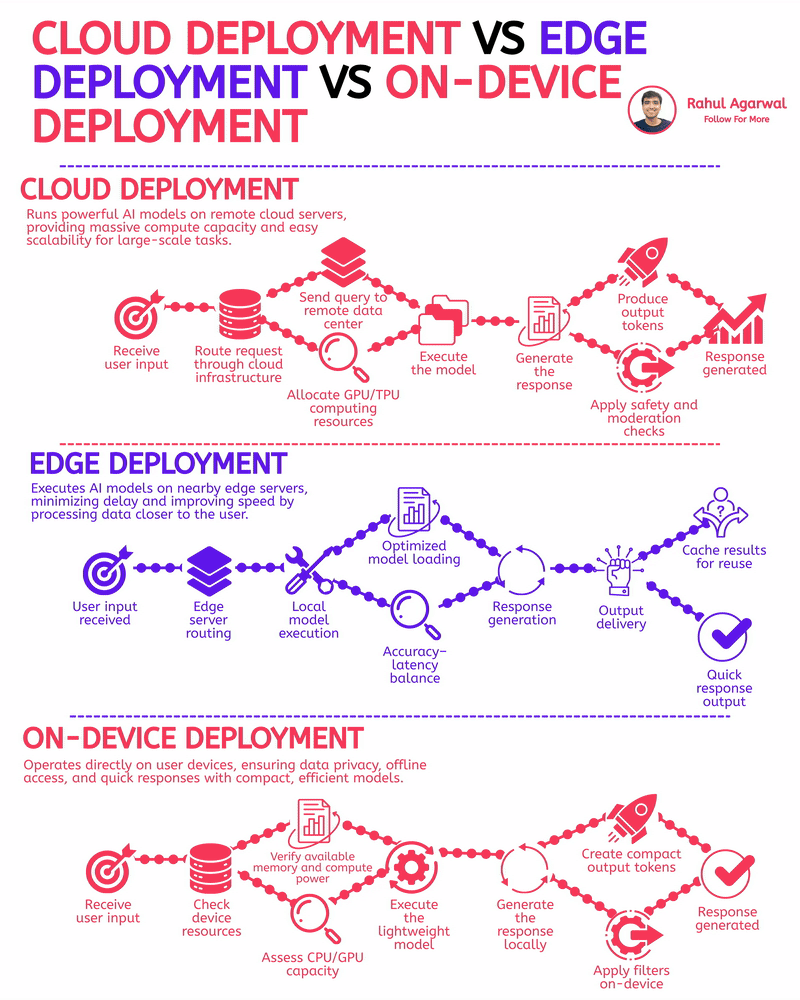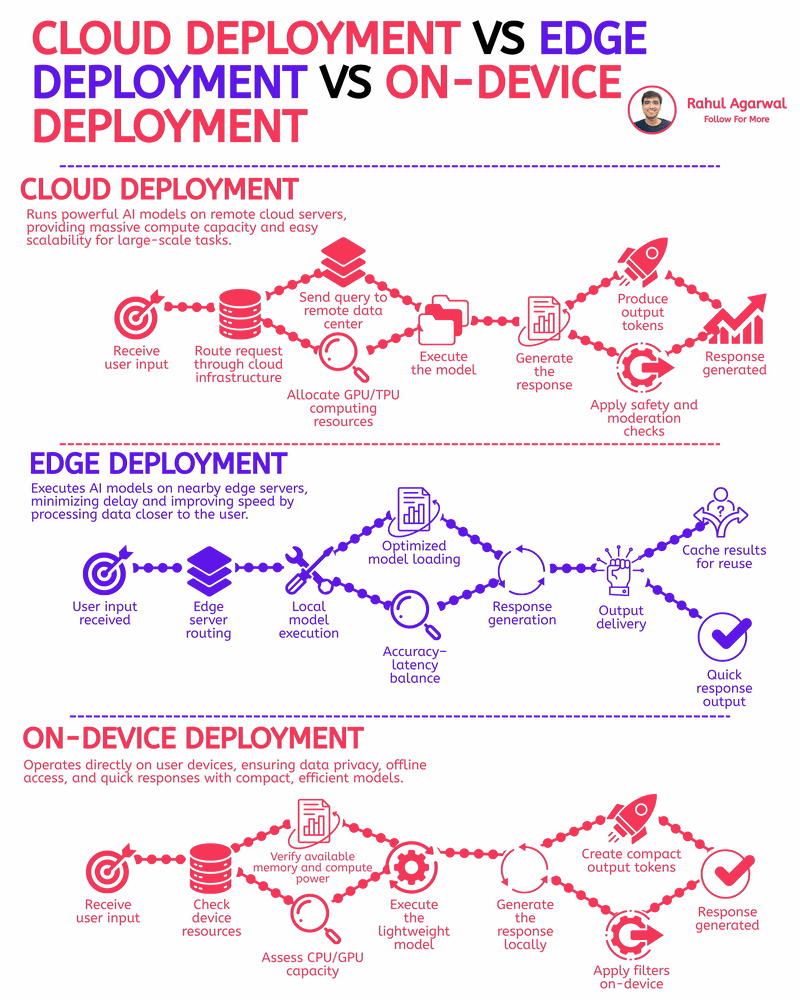




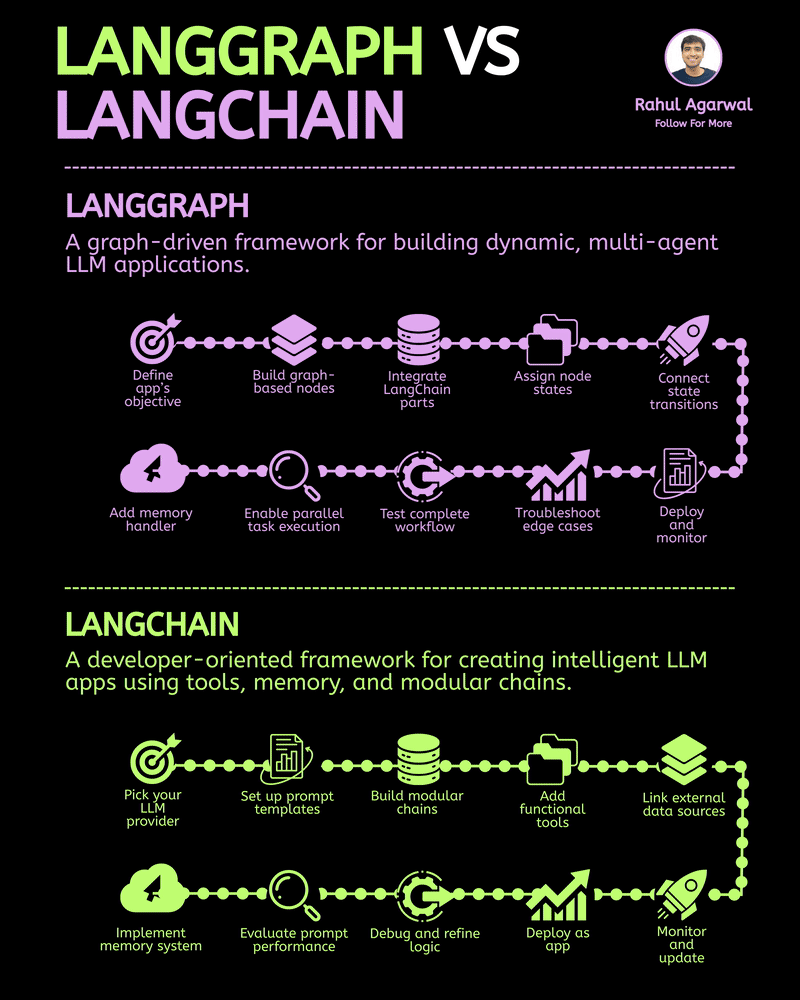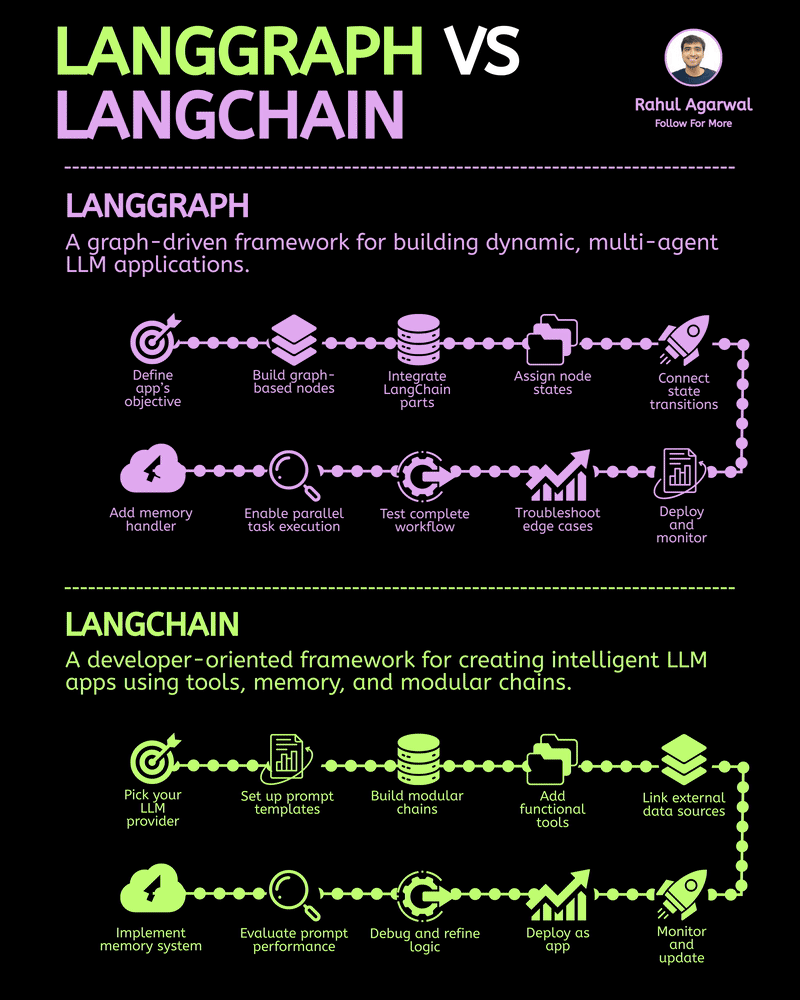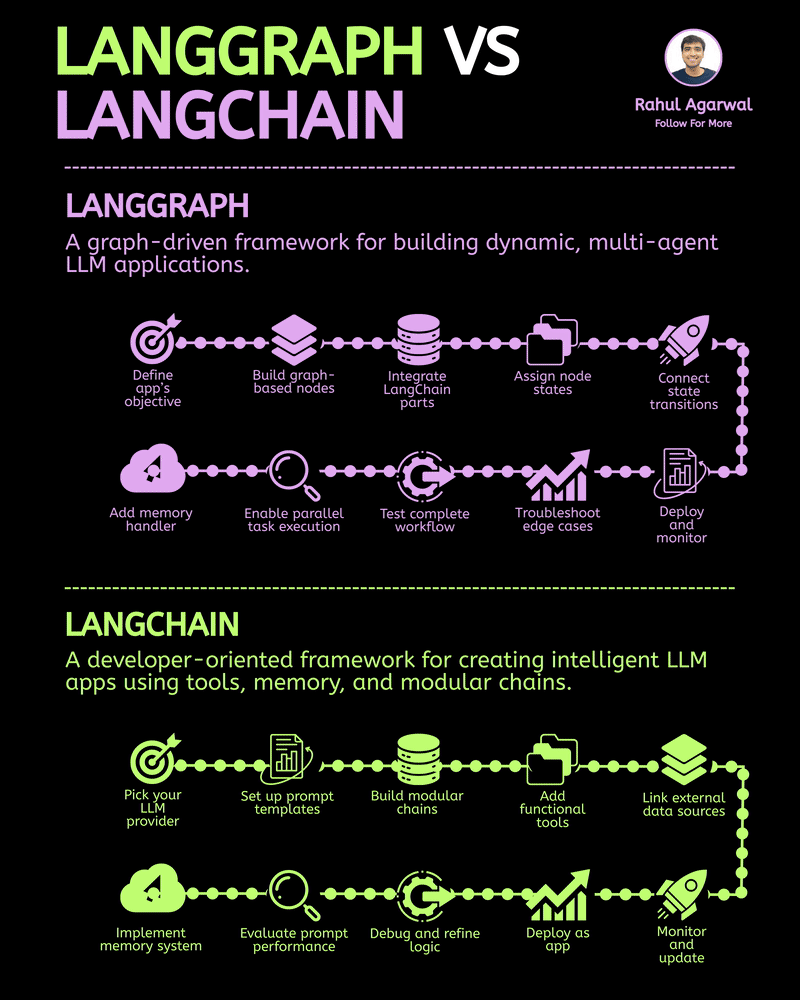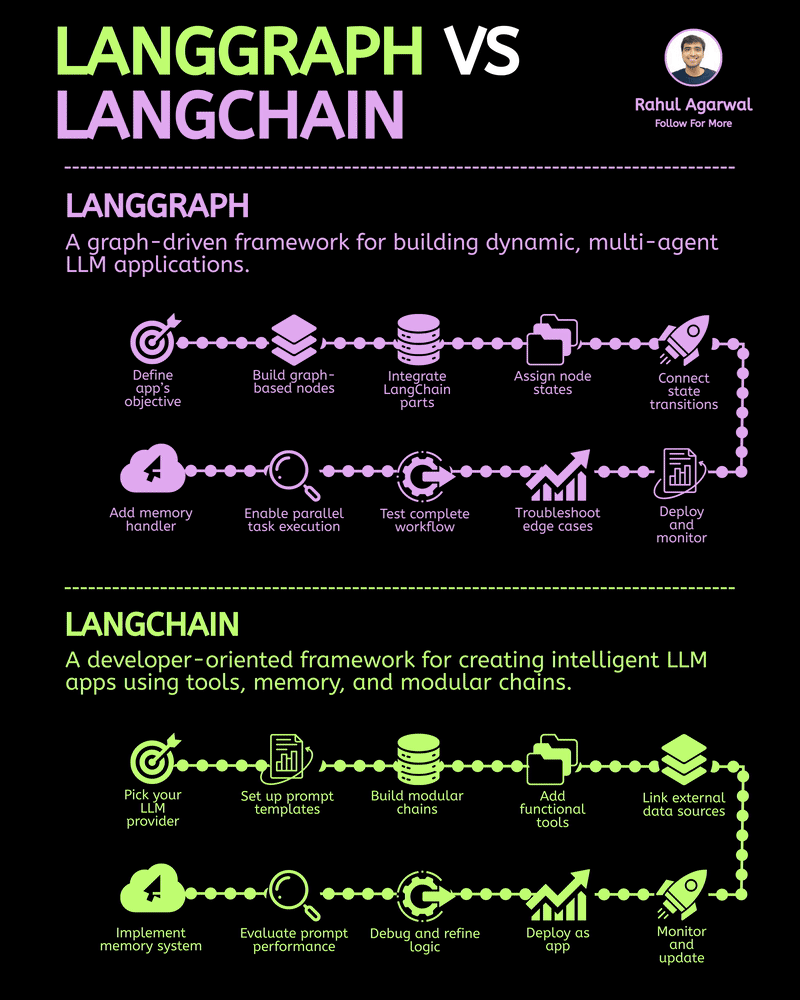
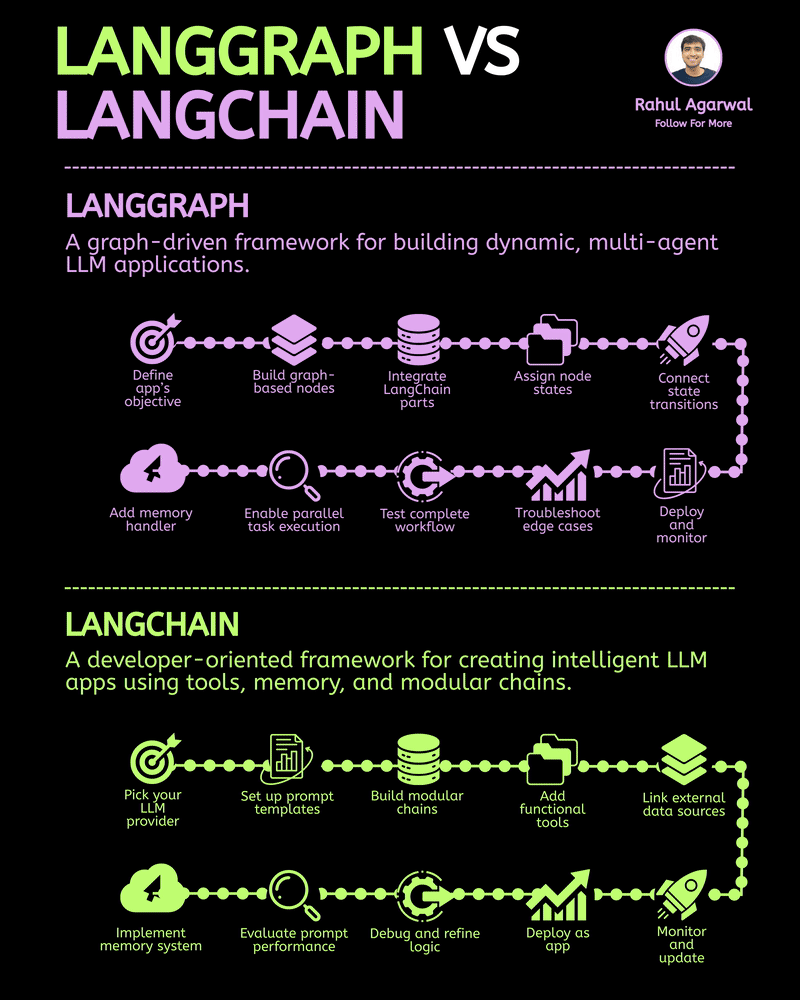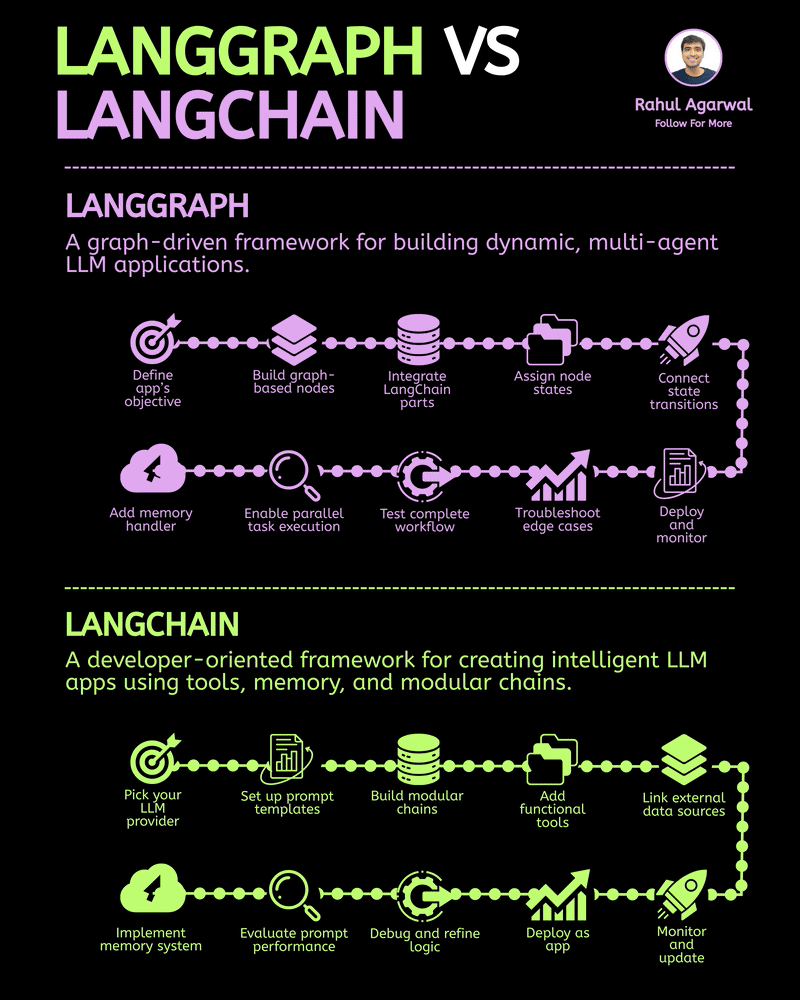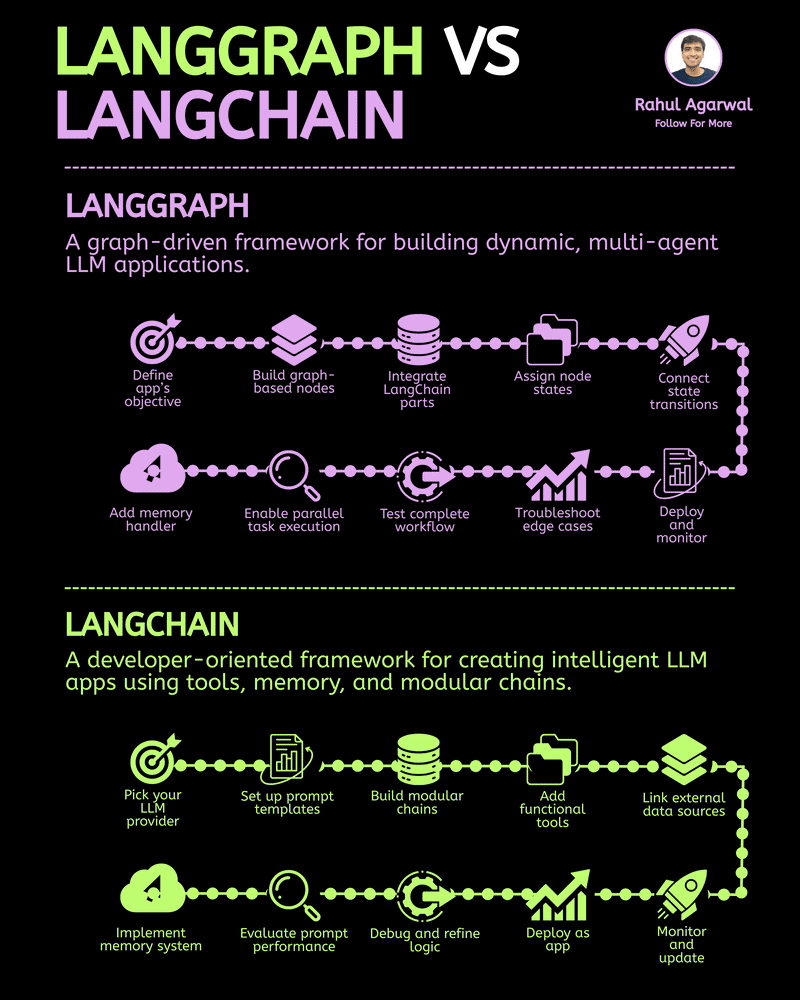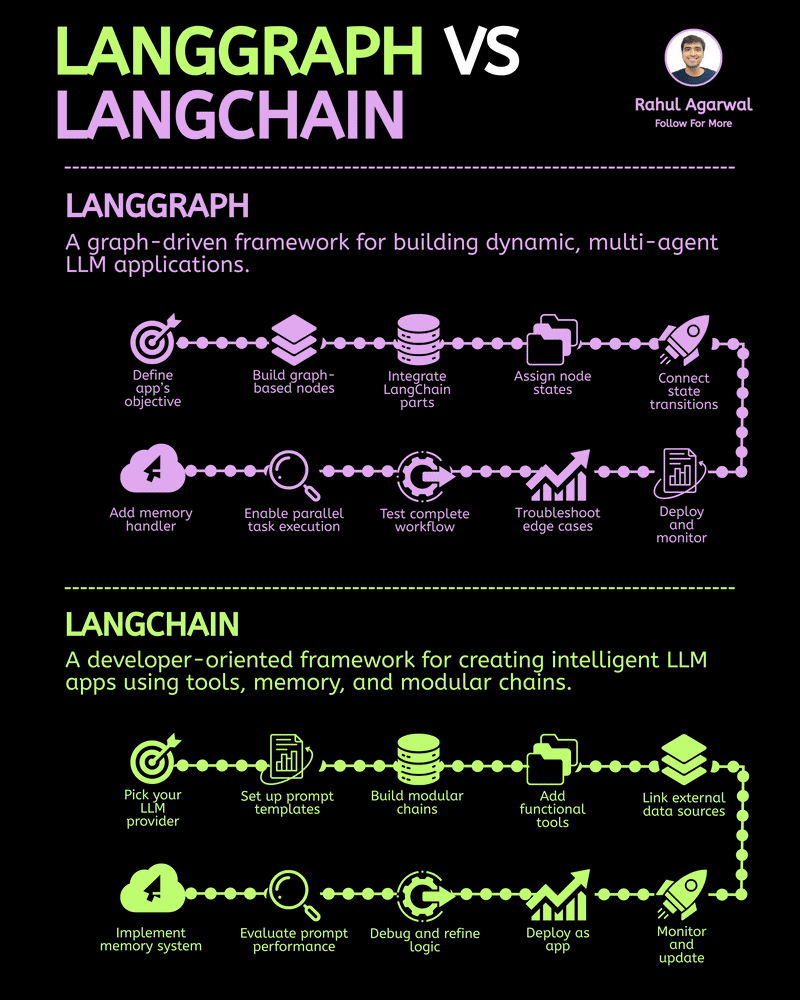

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)

























Download the medial app to read full posts, comements and news.