
Back

Sanskar
Keen Learner and Exp... • 6m
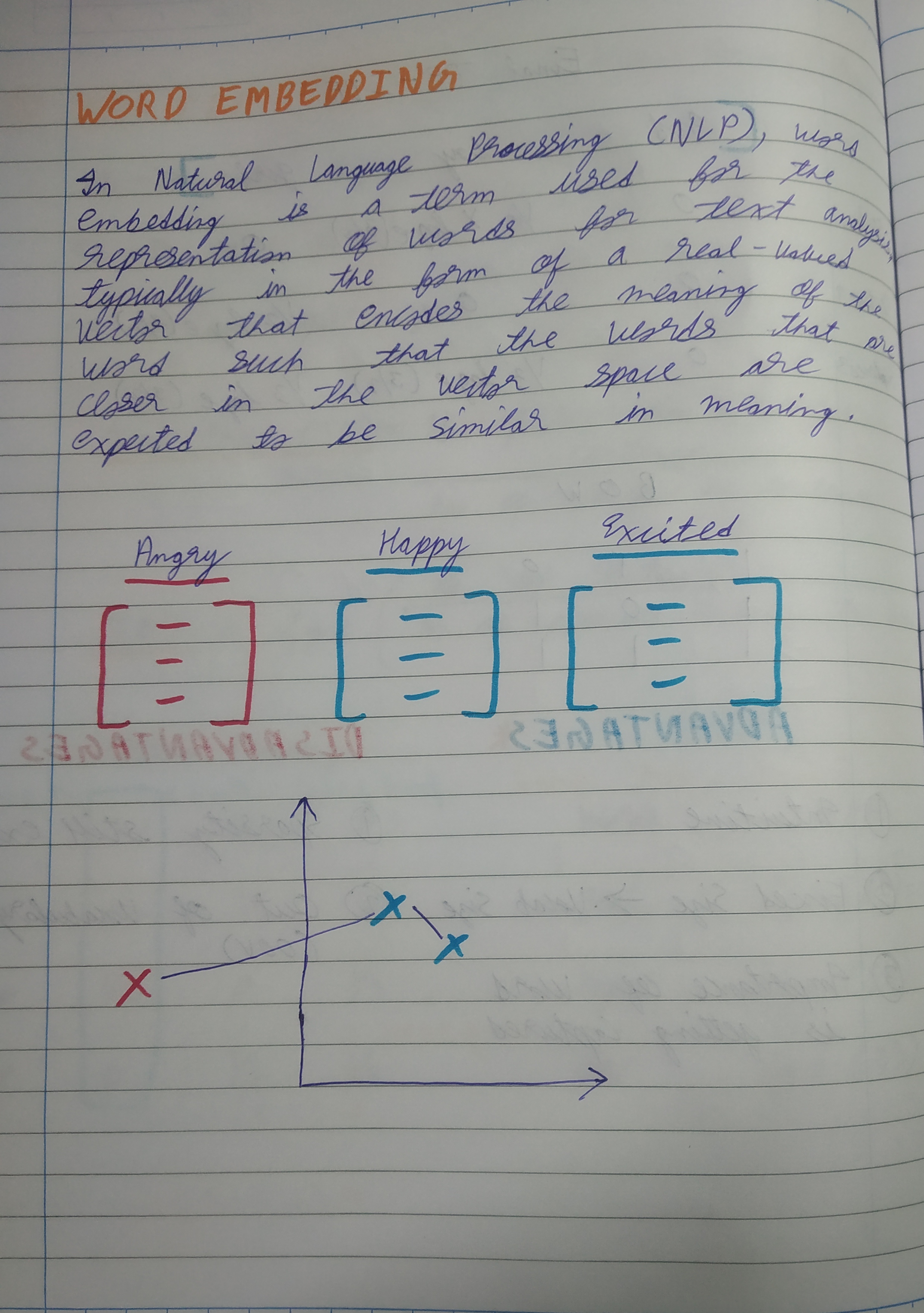
Day 11 of learning AI/ML as a beginner. Topic: TF-IDF (Term Frequency - Inverse Document Frequency). Yesterday I have talked about N-grams and how they are useful in Bag of Words (BOW) however it has some serious drawbacks and for that reason I am going to talk about TF-IDF. TF-IDF is a tool used to convert text into vectors. I determines how important a word is in a document i.e. it is capable of capturing word importance. Term Frequency as the name suggest means how many times a word is present in a document(sentence). It is calculated by: No. of repetition of words in sentence/No. of words in sentence. Then there is Inverse Document Frequency which assigns less weight to the terms which are used many times across many documents and more weightage to the one which is less used across documents. TF-IDF has some of the major benefits and advantages as compared to its previous tools like BOW, One Hot Encoding etc. Its advantages includes it is intuitive to use, it has fixed vocab size and most importantly it is capable of capturing word importance. Its disadvantages includes the usual Sparsity and the problem of out of vocabulary (OOV). Here are my notes.


More like this
Recommendations from Medial

Sanskar
Keen Learner and Exp... • 6m
Day 8 of learning AI/ML as a beginner. Topic: Bag of Words (BOW) Yesterday I told you guys about One Hot Encoding which is one way to convert text into vector however with serious disadvantages and to cater to those disadvantages there's another on
See More





Sanskar
Keen Learner and Exp... • 6m
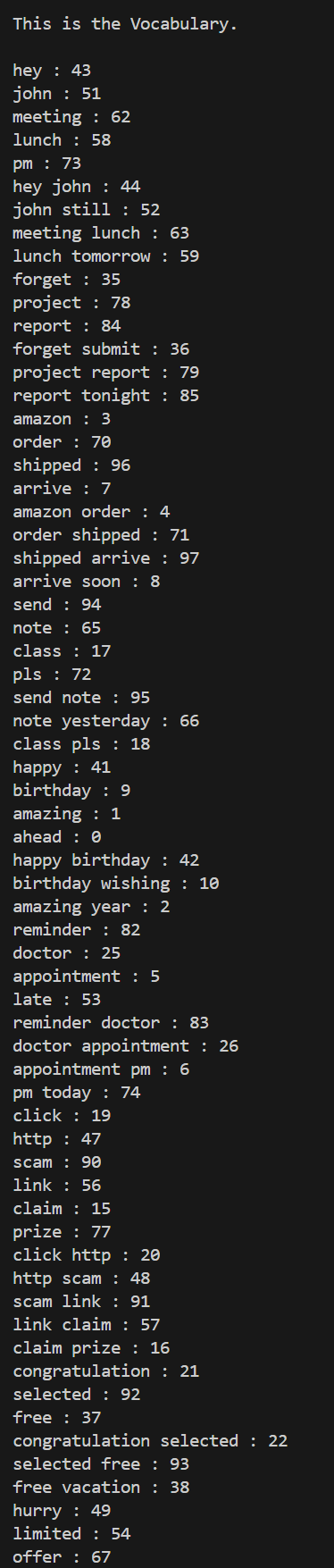
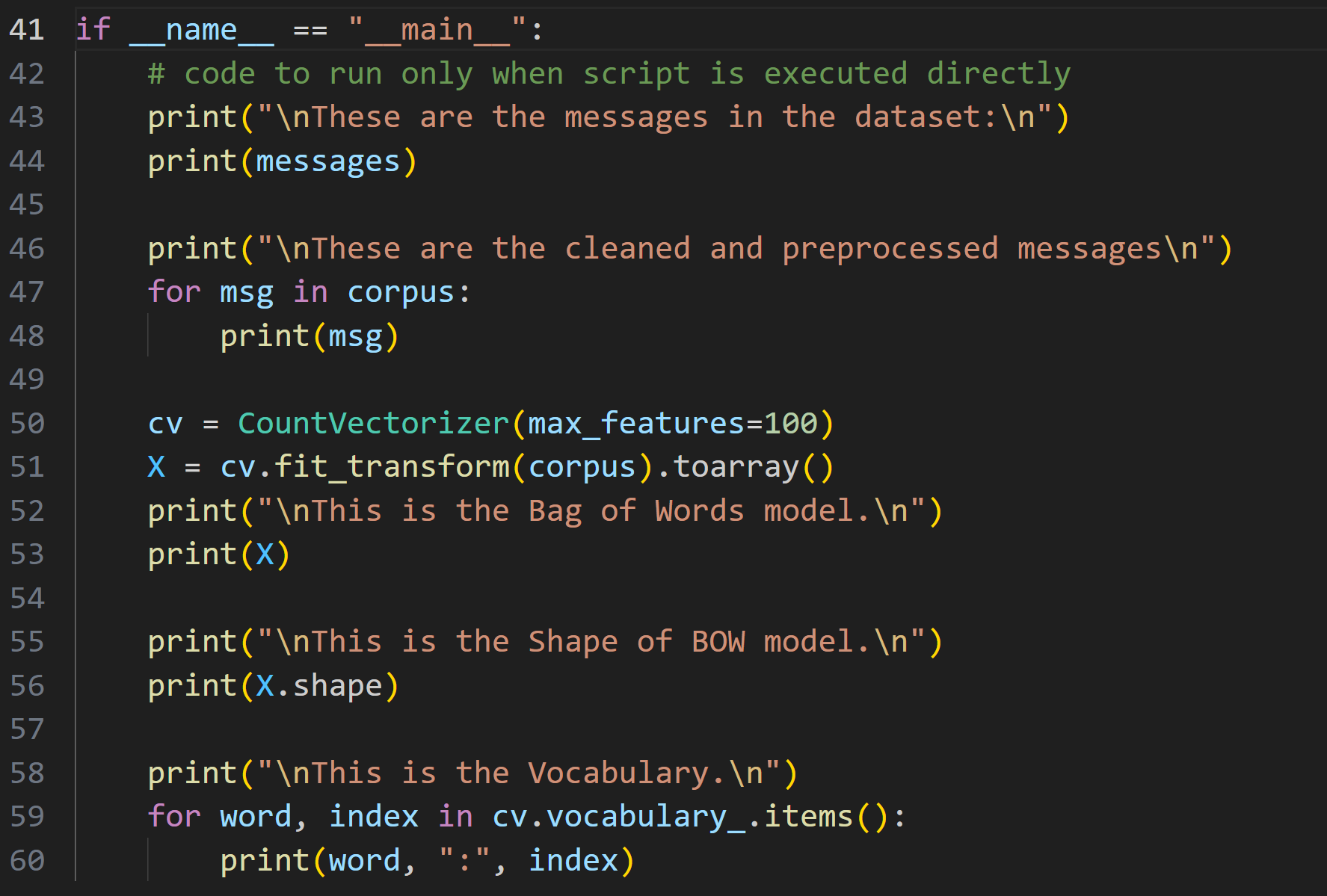
Day 10 of learning AI/ML as a beginner. Topic: N-Grams in Bag of Words (BOW). Yesterday I have talked about an amazing text to vector converter in machine learning i.e. Bag of Words (BOW). N-Gram is just a part of BOW. In BOW the program sees sente
See More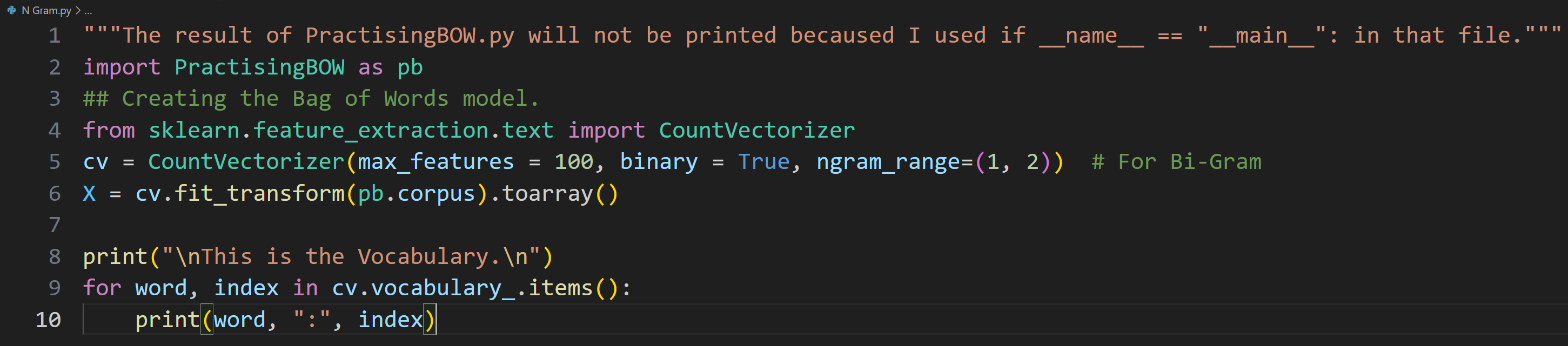


Sanskar
Keen Learner and Exp... • 6m
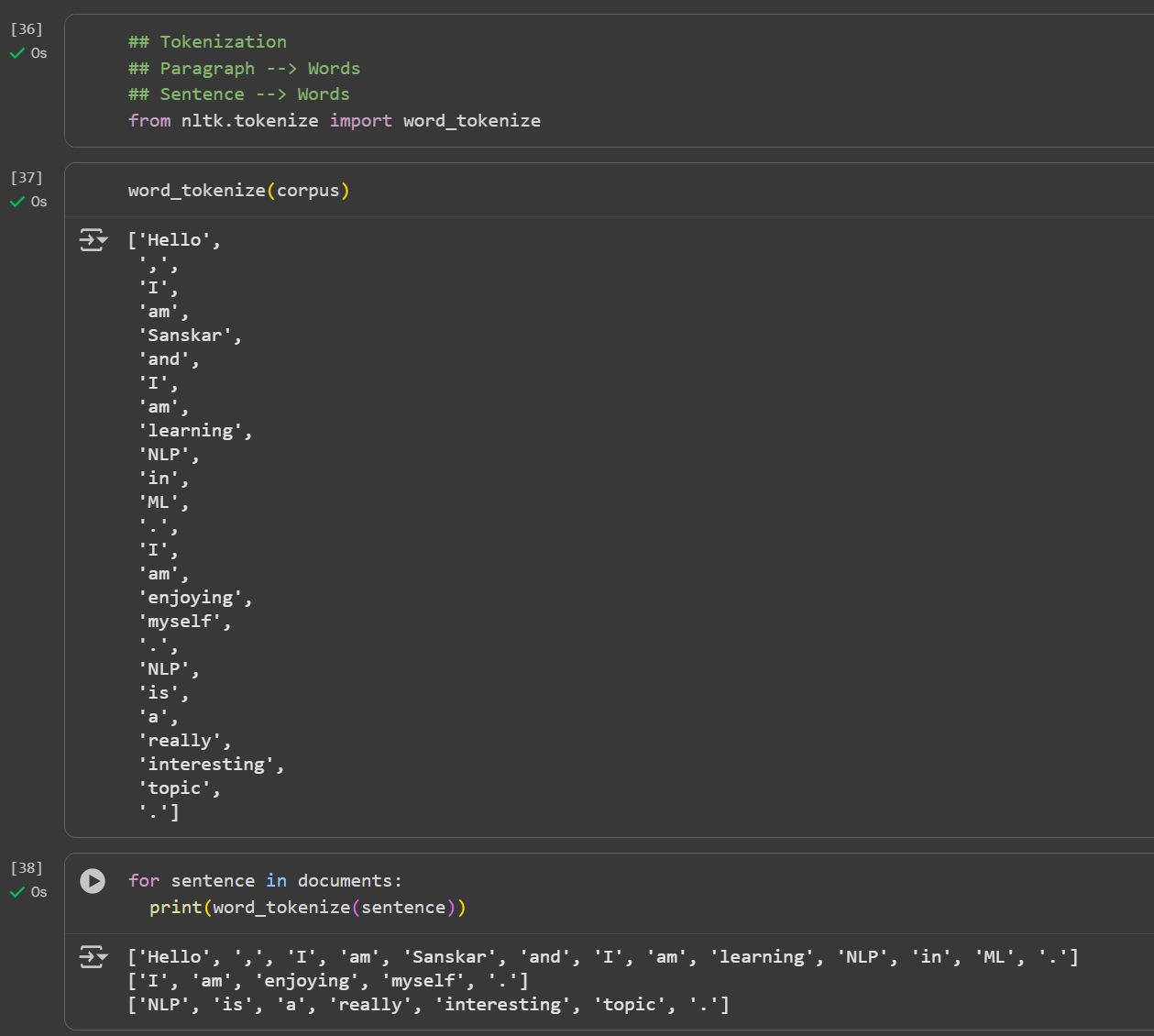
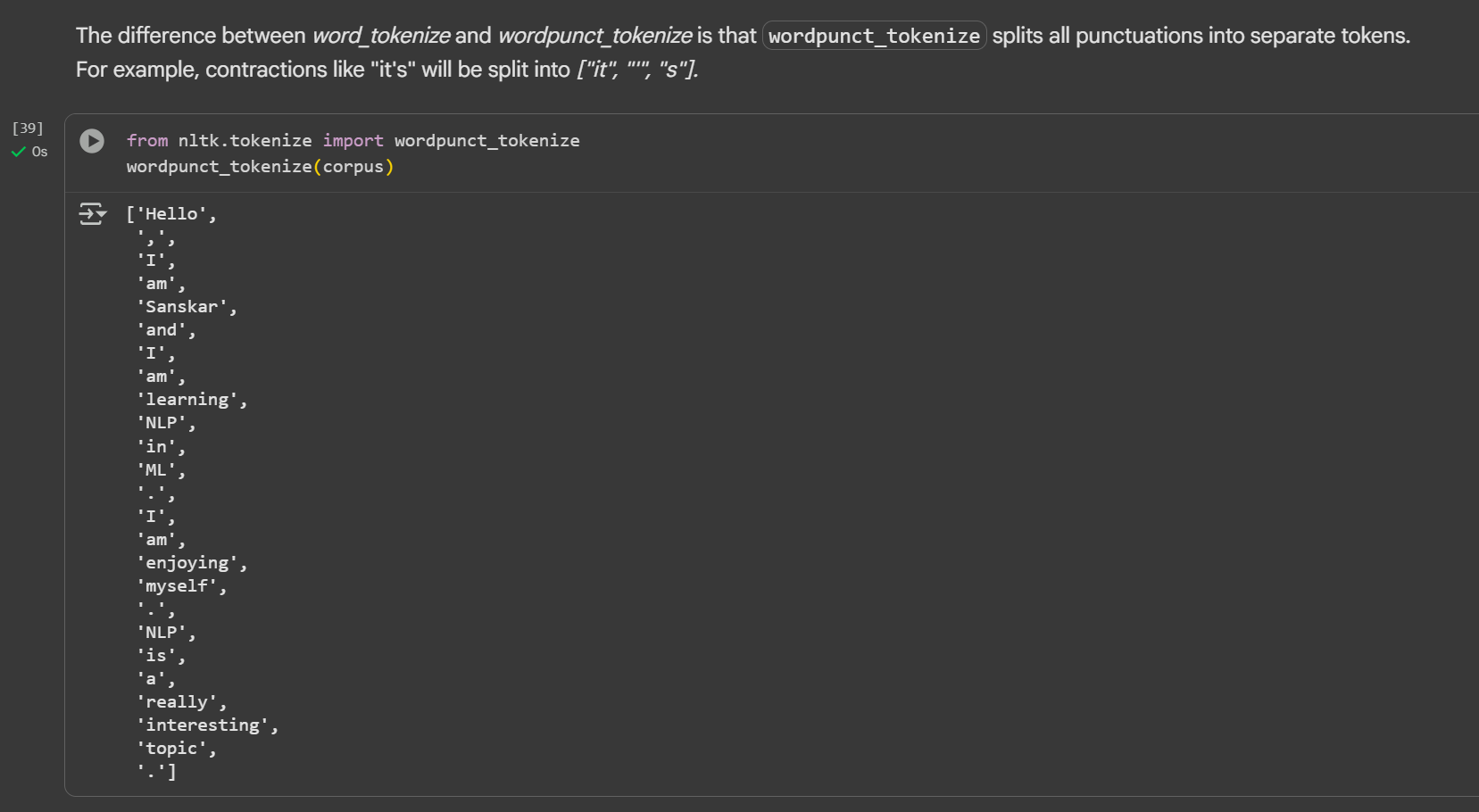
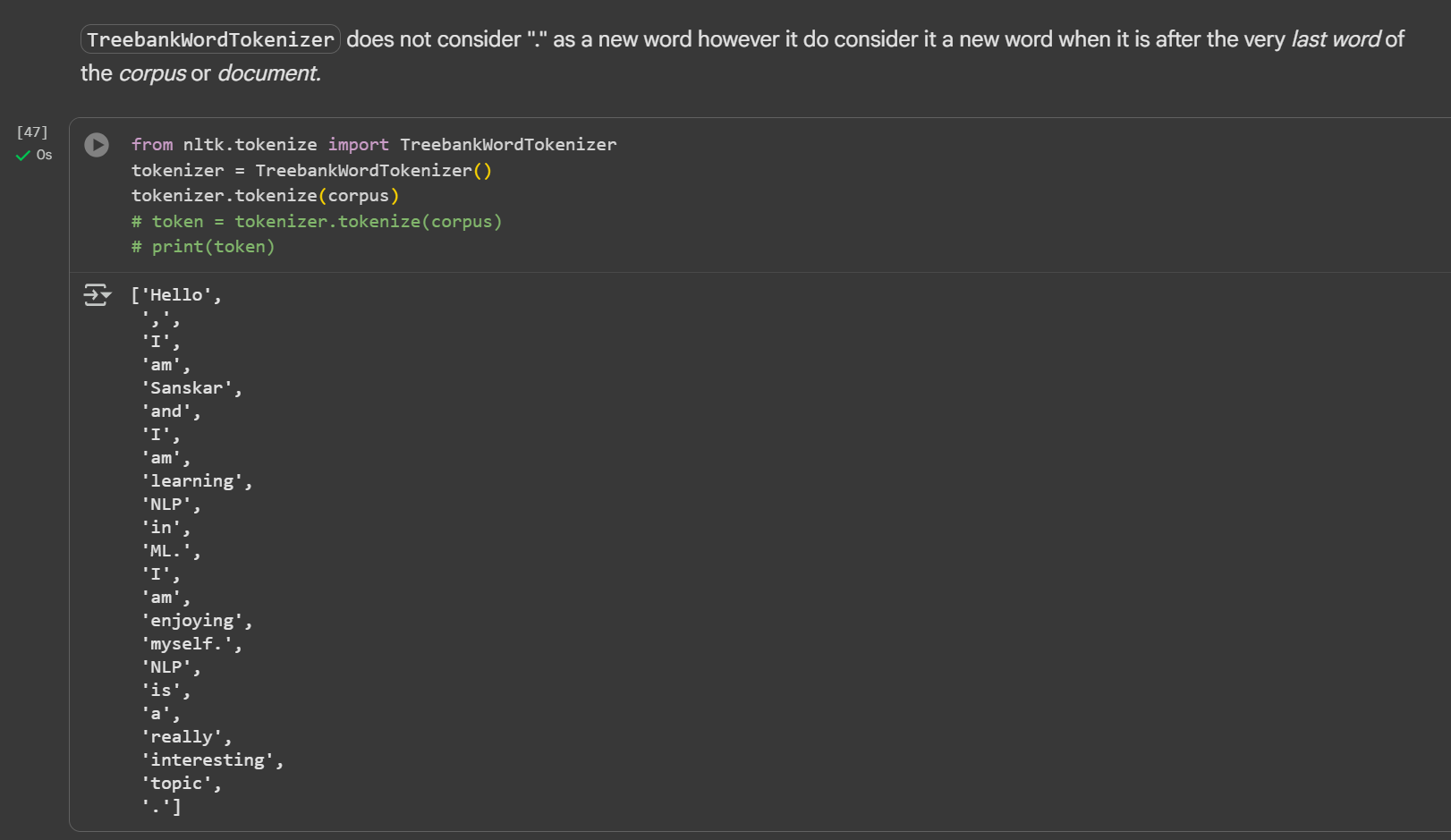
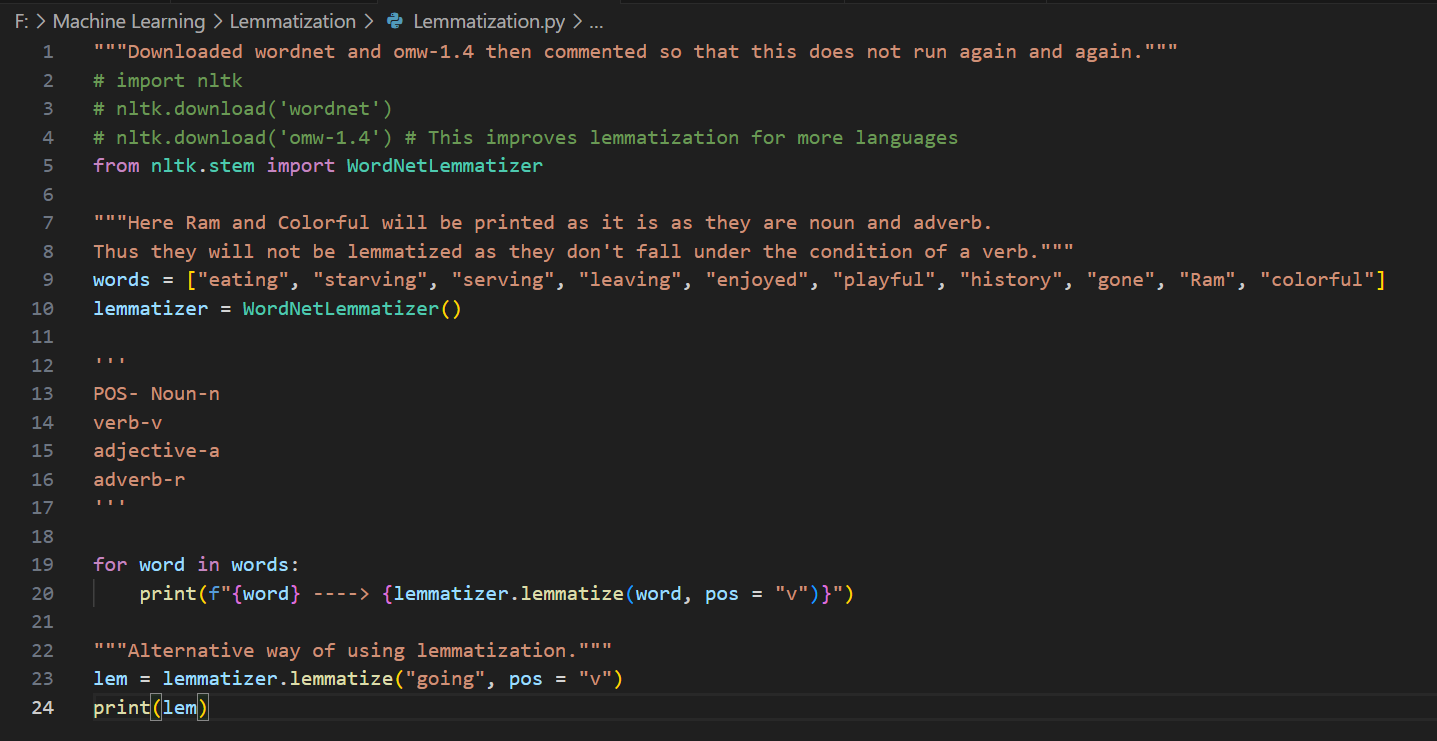
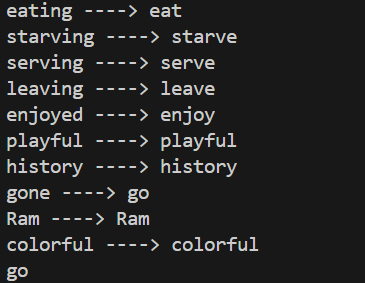
Day 3 of learning AI/ML as a beginner. Topic: NLP (Tokenization) Tokenization is breaking paragraph (corpus) or sentence (document) into smaller units called tokens. In order to perform tokenization we use nltk (natural language toolkit) python li
See More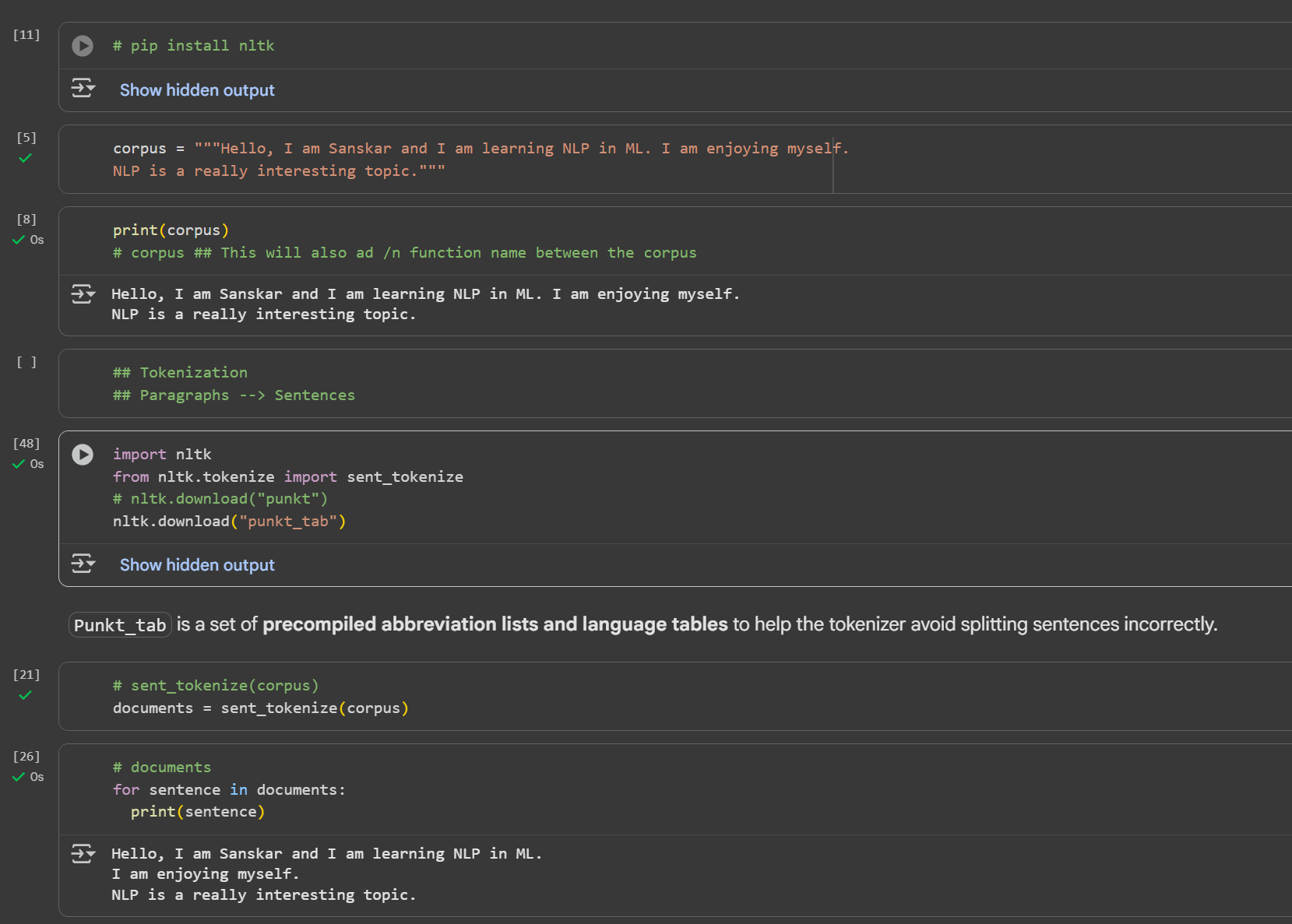

Sanskar
Keen Learner and Exp... • 6m
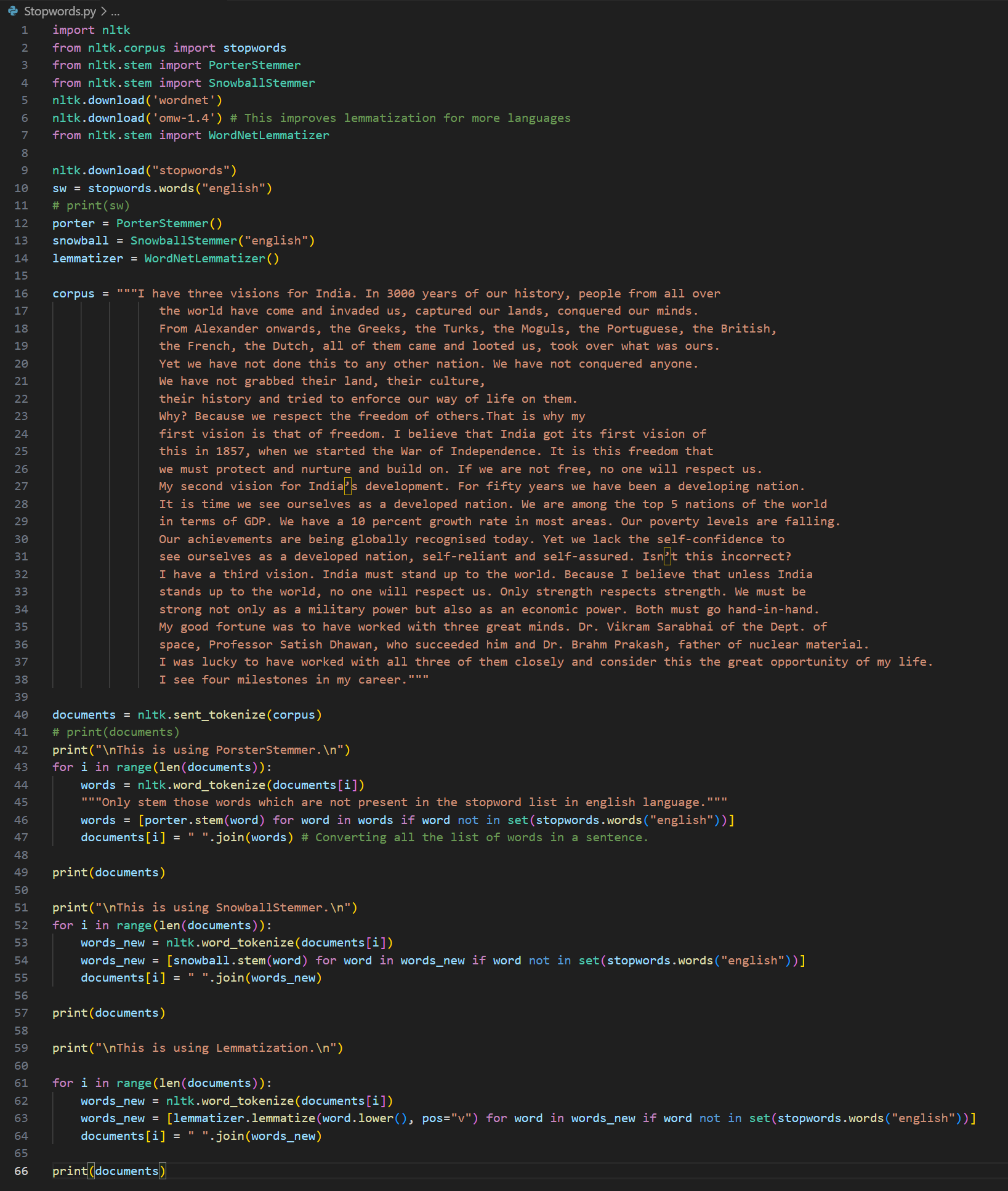
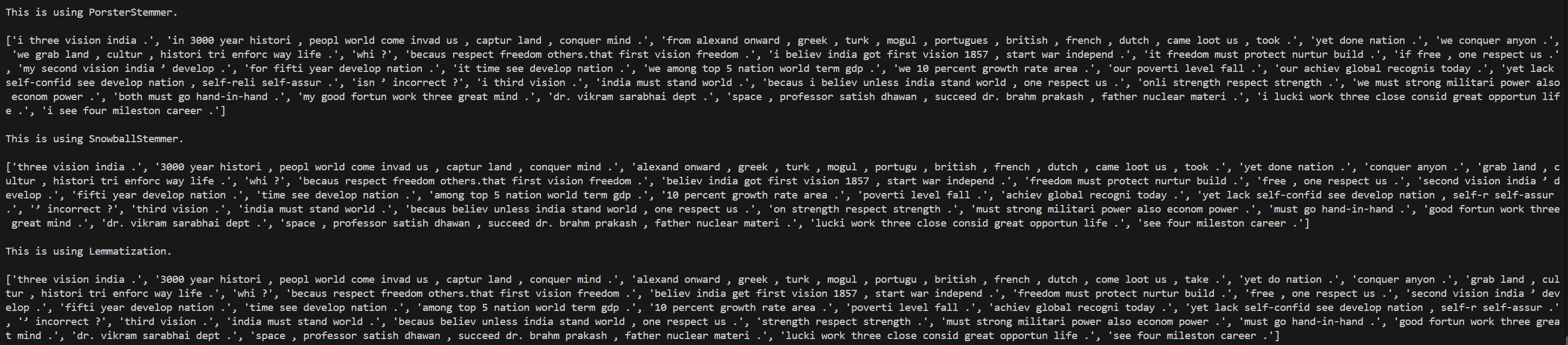
Day 12 of learning AI/ML as a beginner. Topic: TF-IDF practical. Yesterday I shared my theory notes and today I have done the practical of TF-IDF. For the practical I reused my spam classifier code and for TF-IDF I first imported it from the sklear
See More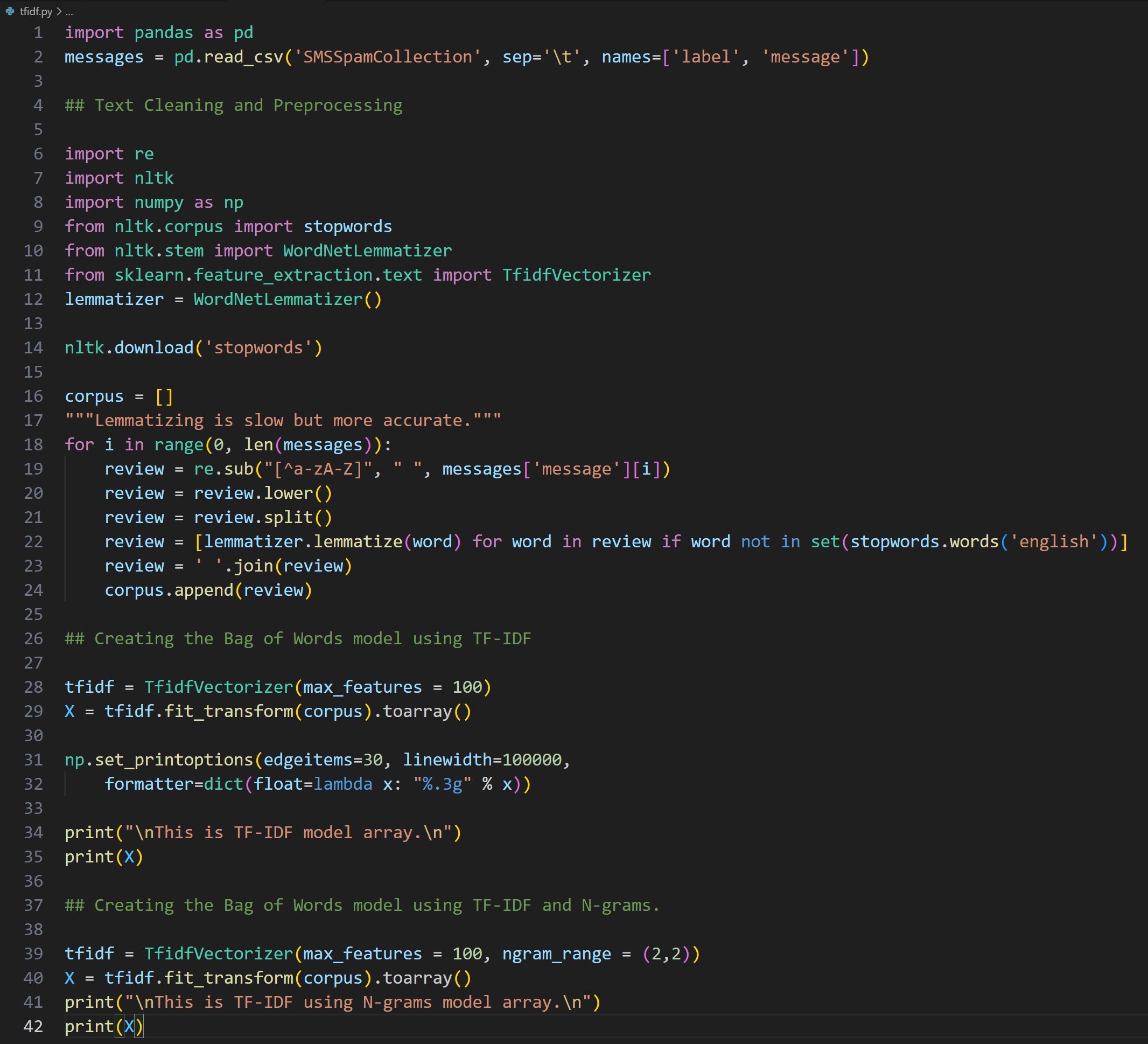




T.K.ANJANAA SREE
Hey I am on Medial • 1y
Why should create a pdf viewer app integrated with AI So everytime we come across a new sentence or new word we come out and search for it.. so using AI selecting the text and double taking leads to result of meaning of the sentence Why shouldn't we
See More
/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)

























Download the medial app to read full posts, comements and news.