
Back

Sanskar
Keen Learner and Exp... • 6m
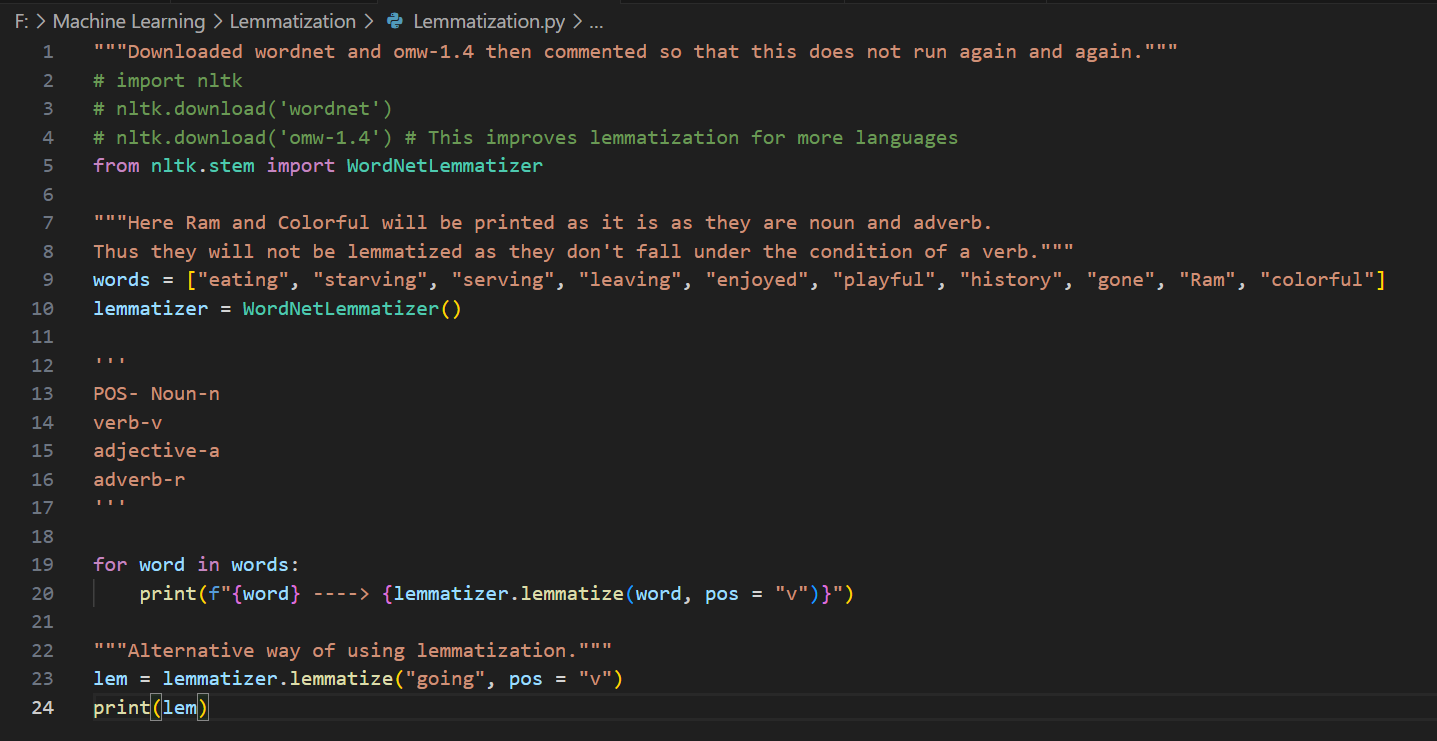
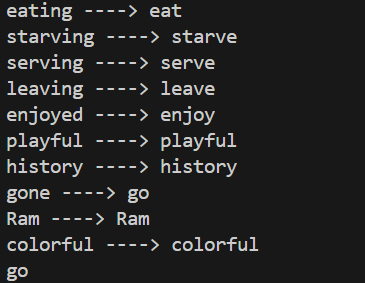
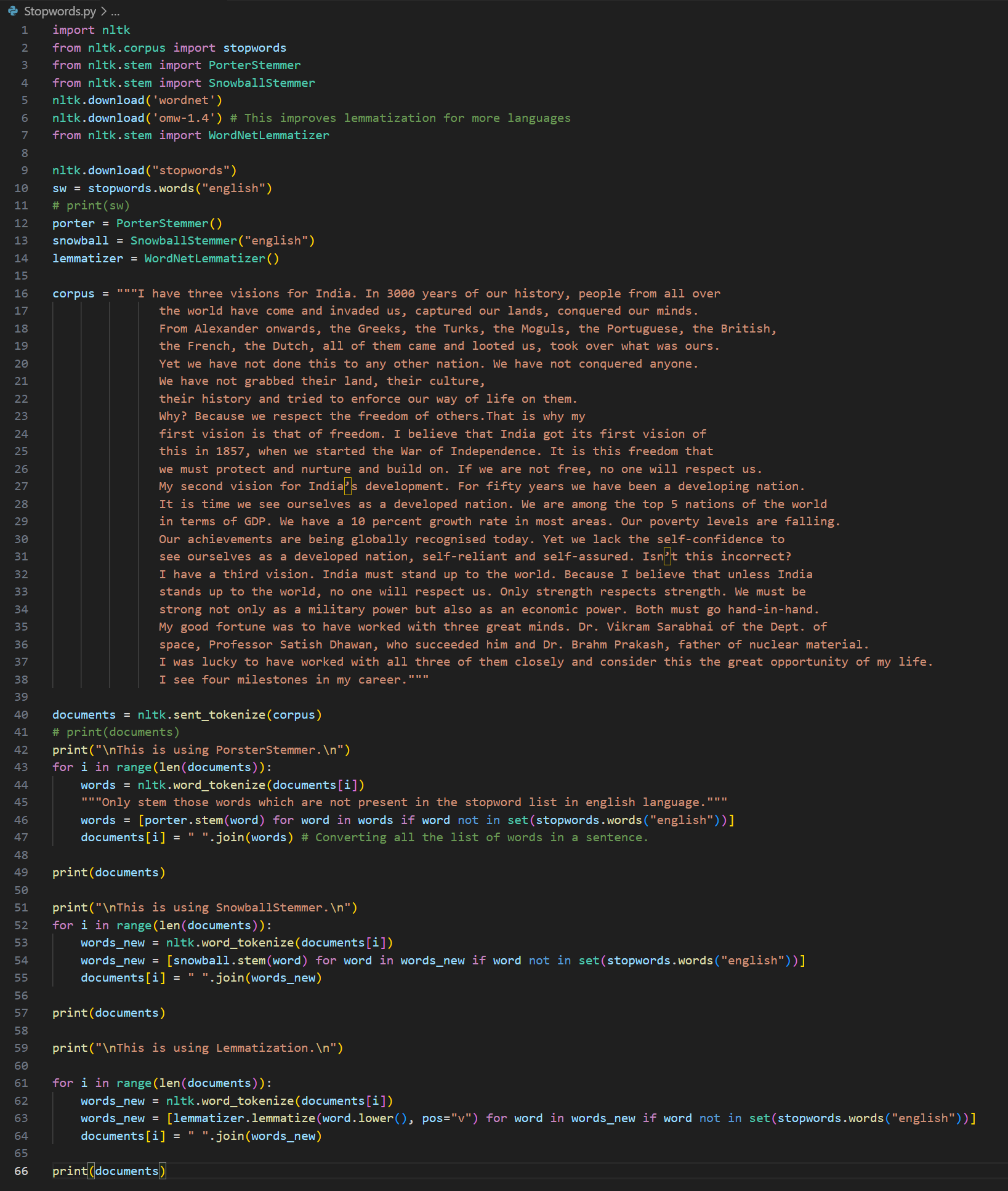
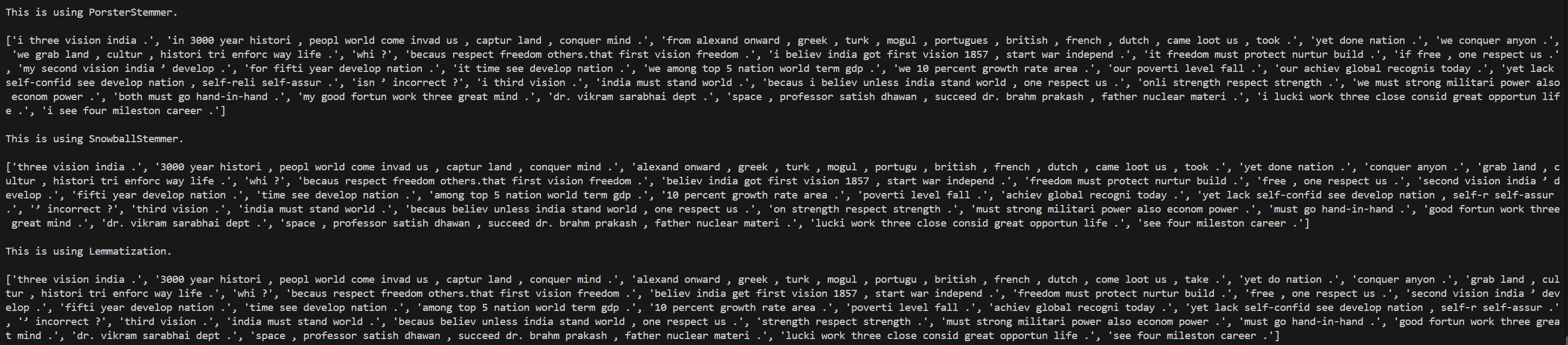
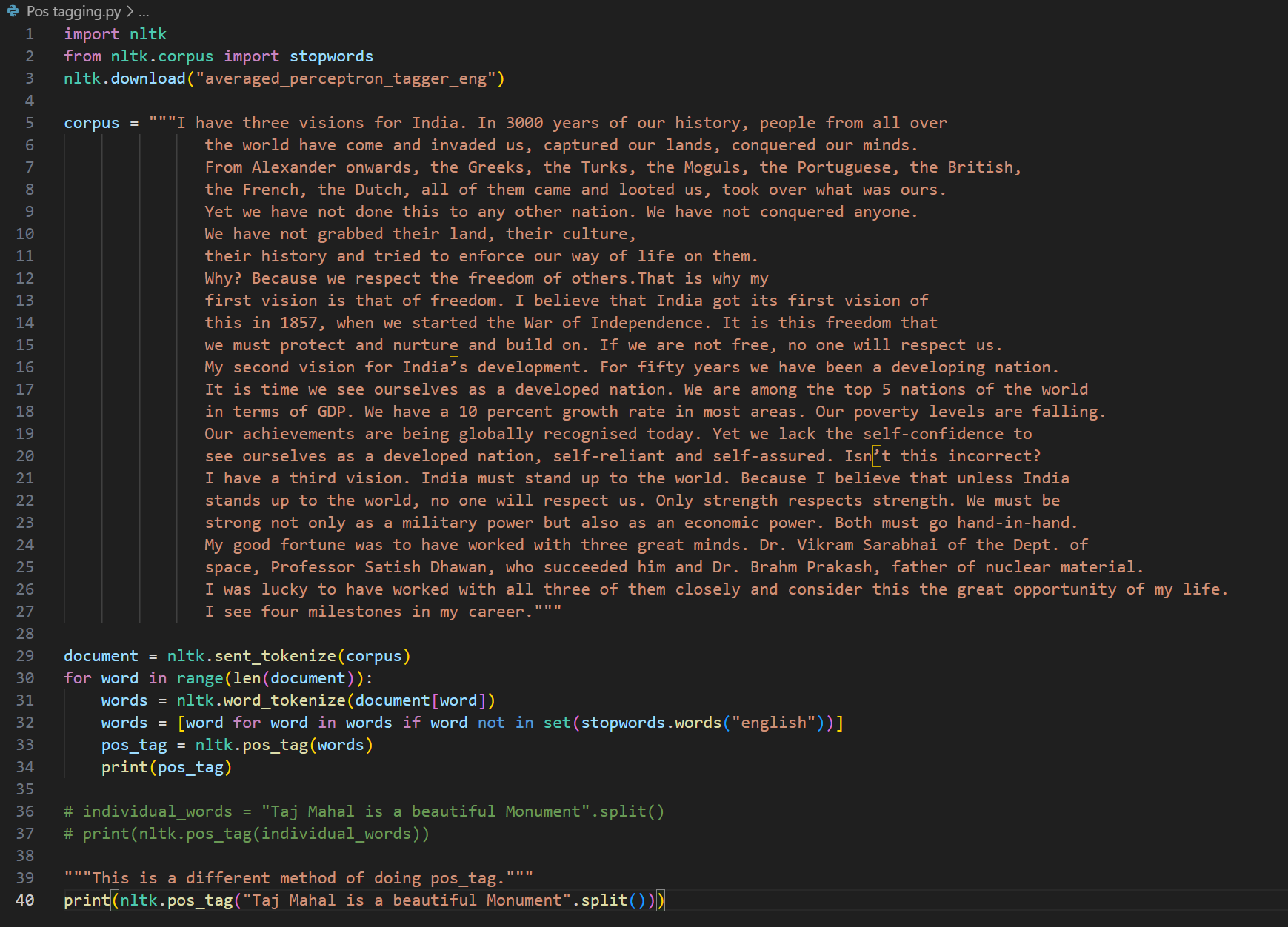
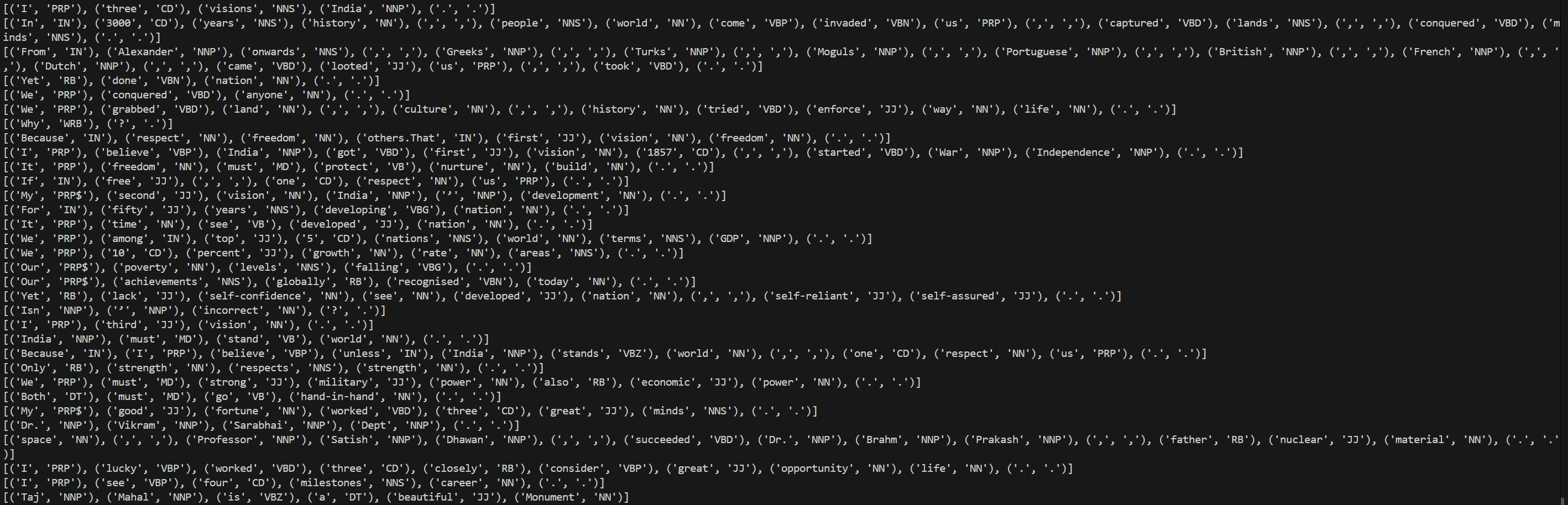
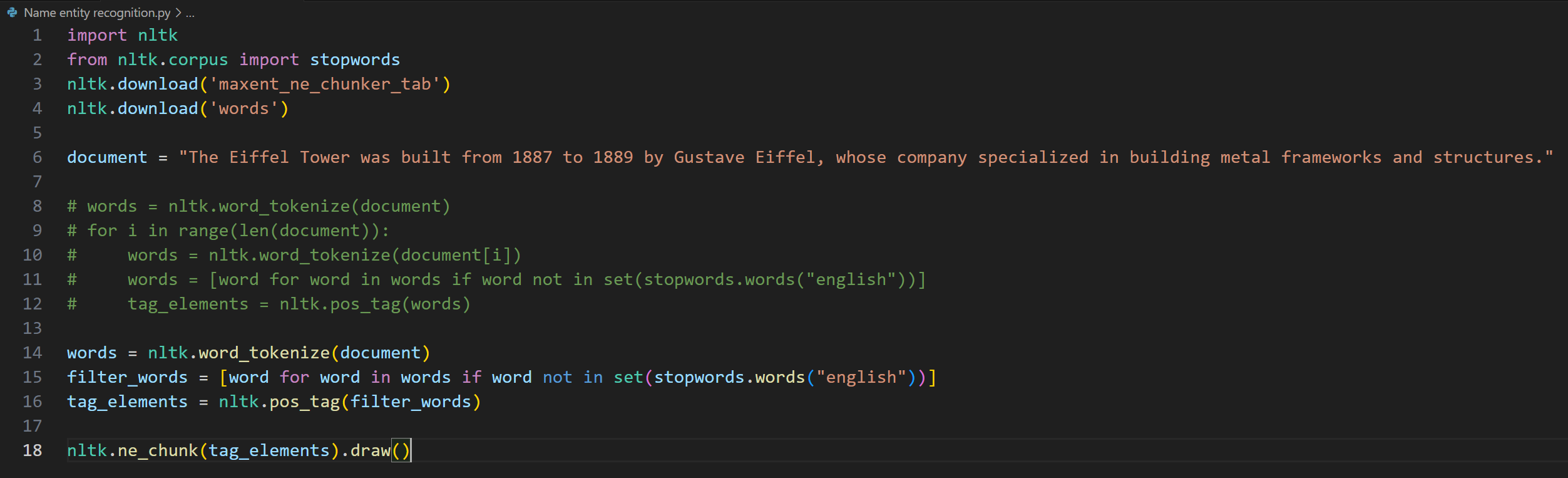
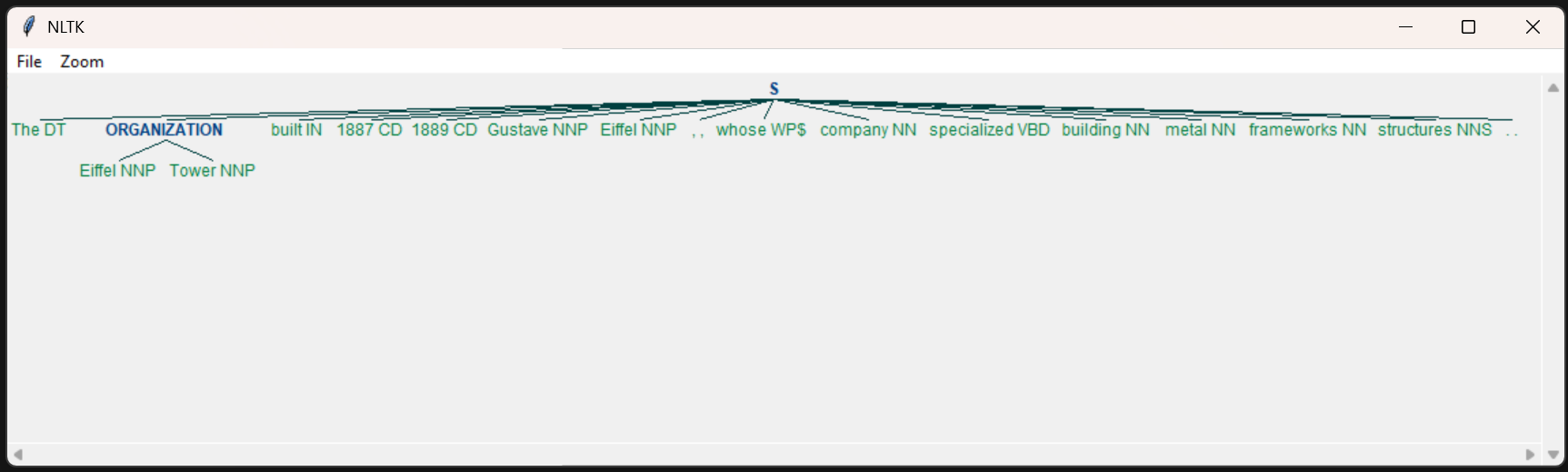
Day 5 of learning AI/ML as a beginner. Topic: lemmatization and stopwords. Lemmatization is same as stemming however in lemmatization a word is reduced to its base form also known as lemma. This is a dictionary based process. This is accurate then stemming however on the cost of speed (i.e. it is slower as compared to stemming). Lemmatization also involve parts of speech(pos) where "v" stands for verb, "n" stands for nouns, "a" stands for adjectives, "r" stands for adverb. Lemmatization works well when you use the more suitable pos although it also had some tagging feature which is yet to be learned by me so no comments on it for this time. Then there is stop words which consists of all those very commonly used words in a language (for example in English they can be referred to as is, am, are, was, were, the etc.) Stop words are usually removed in order to reduce noise in the text, to speed up processing and to sort out the important words in a document(sentence). I used lemmatization and stop words together to clean a corpus (paragraph). and take out the main words from every document (I also used sent_tokenize to break the corpus into documents i.e. sentences and those sentences are further broken into word tokens). These words are then put in a new sentences. I have also used PosterStemmer and SnowballStemmer with a motive to compare results and to practice what I have learnt in a few days. Here's my code and its result.
More like this
Recommendations from Medial


Sanskar
Keen Learner and Exp... • 6m
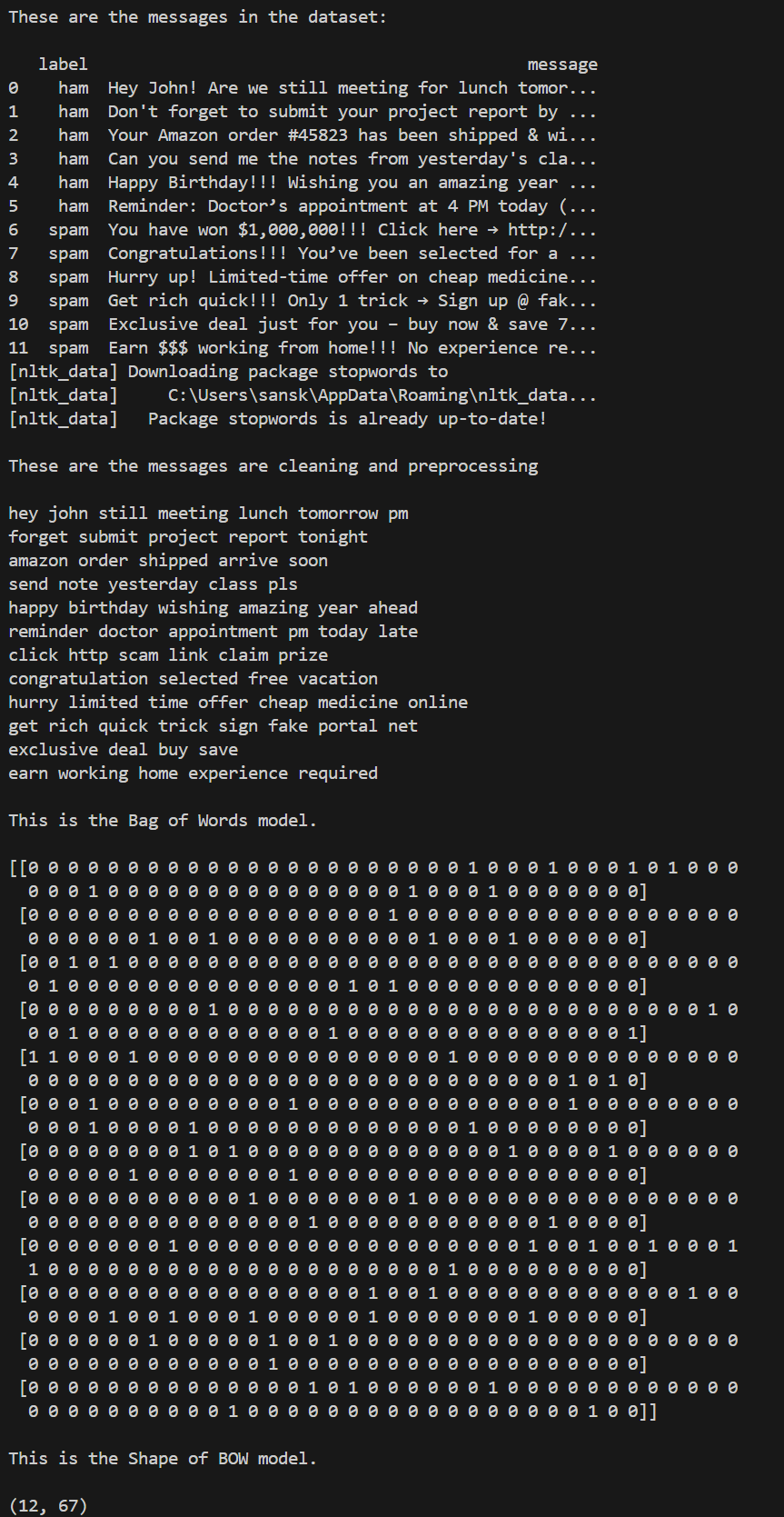
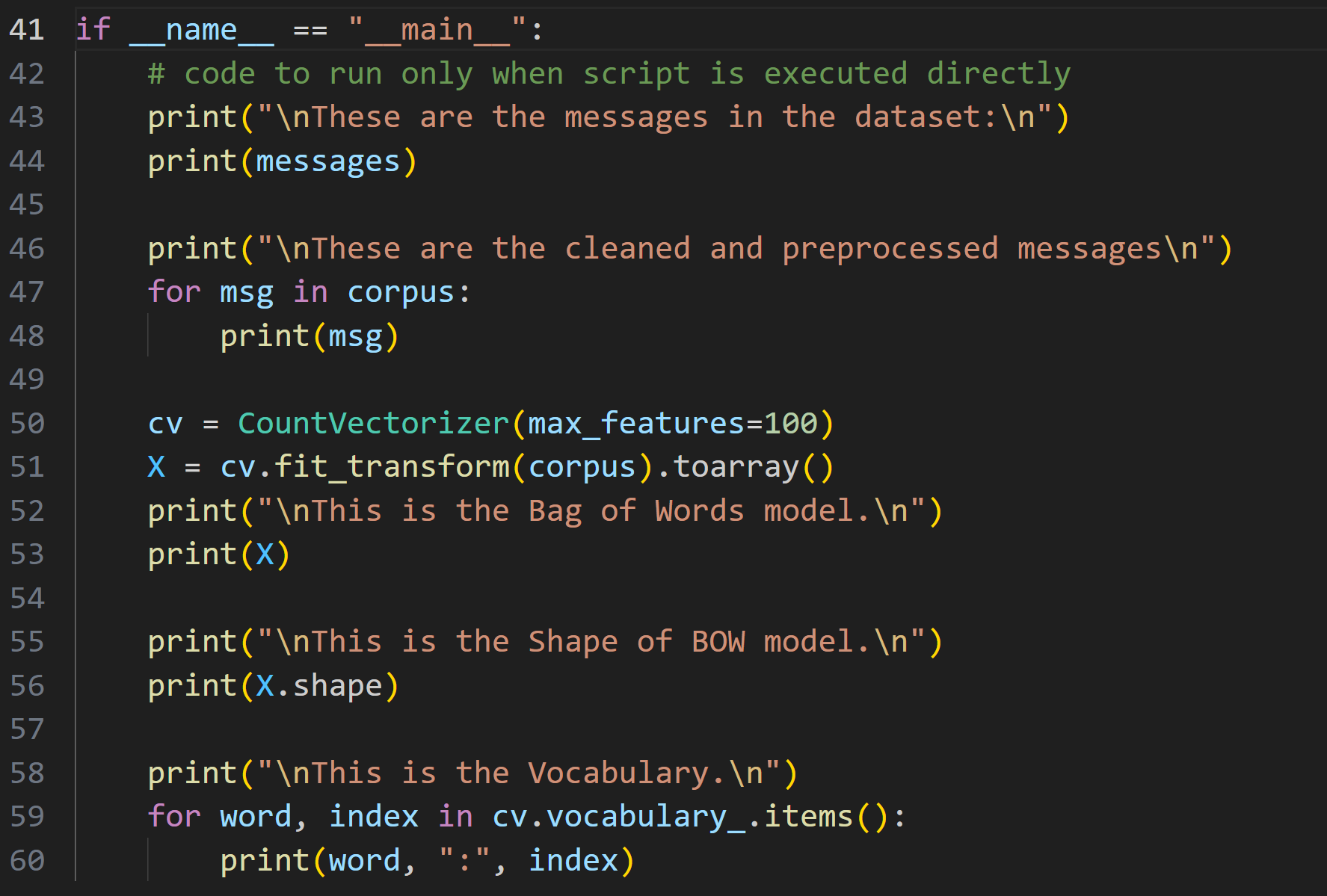
Day 9 of learning AI/ML as a beginner. Topic: Bag of Words practical. Yesterday I shared the theory about bag of words and now I am sharing about the practical I did I know there's still a lot to learn and I am not very much satisfied with the topi
See More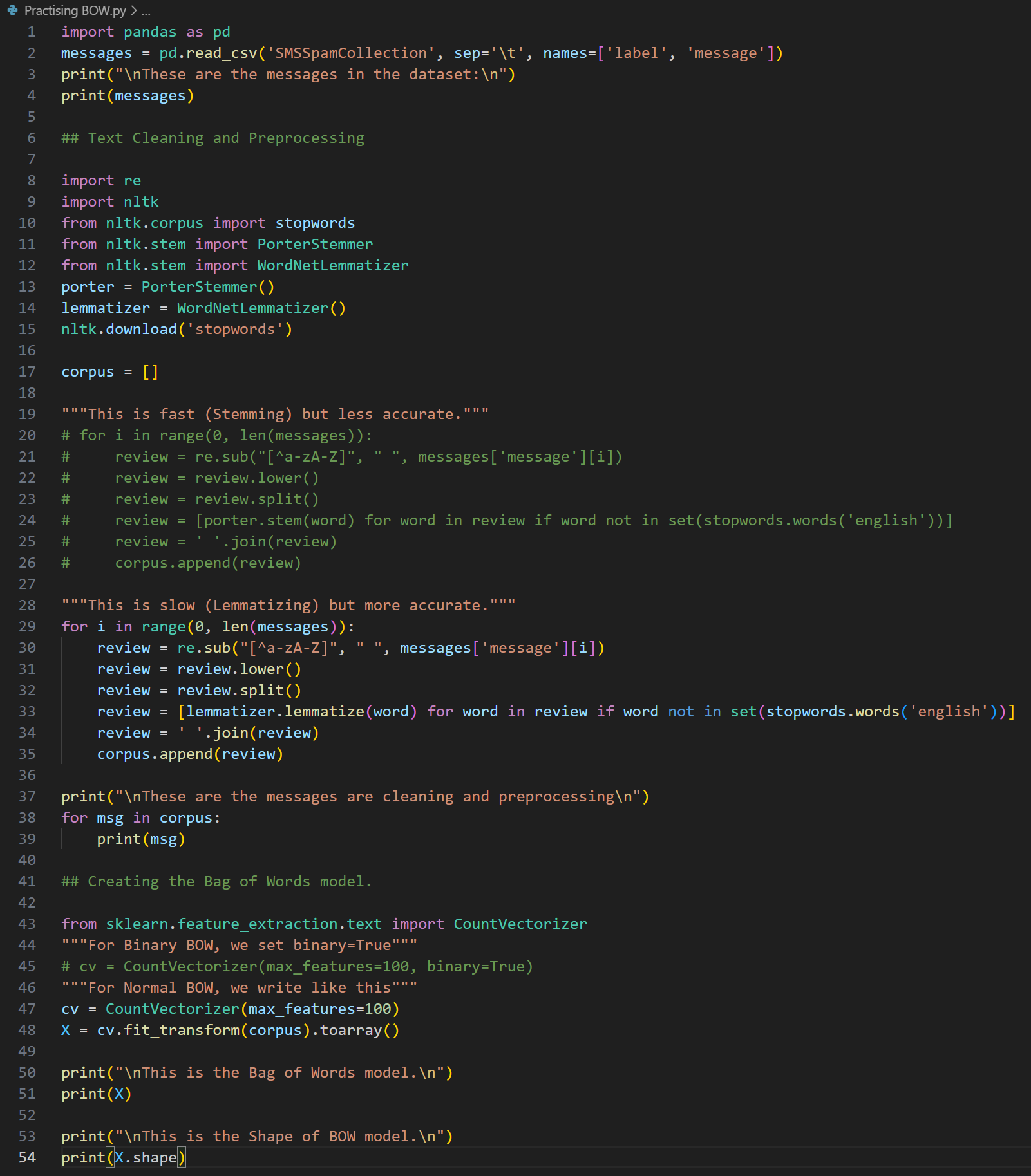

Sanskar
Keen Learner and Exp... • 6m
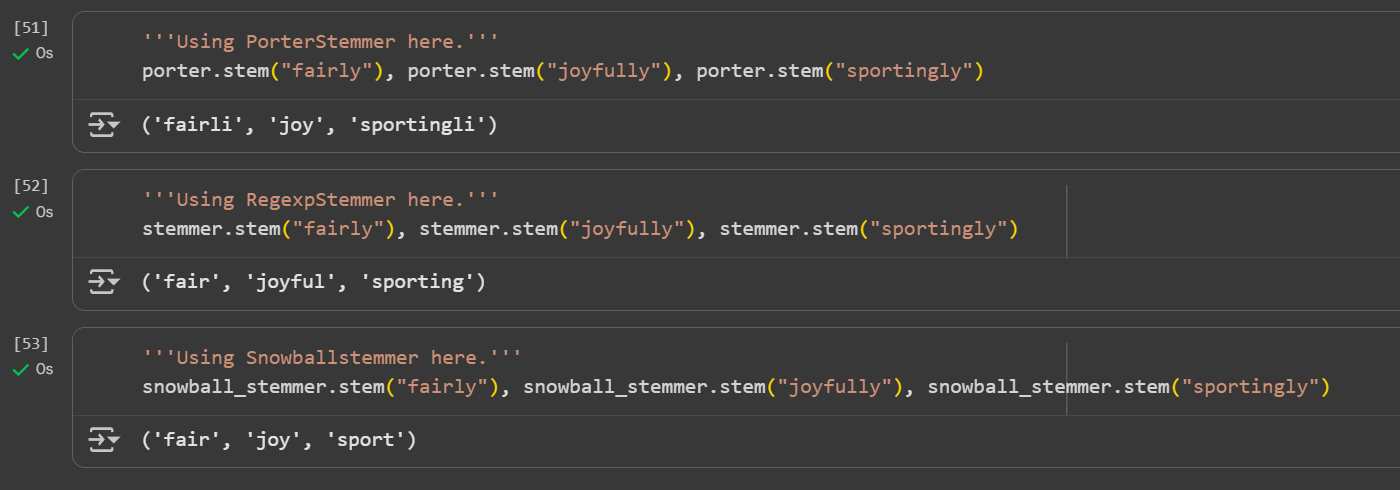
Day 4 of learning AI/ML as a beginner. Topic: text preprocessing stemming using NLTK. I have learned about tokenization and now I am learning about text preprocessing in ML. Text preprocessing is cleaning up of raw text (raw text is the one entered
See More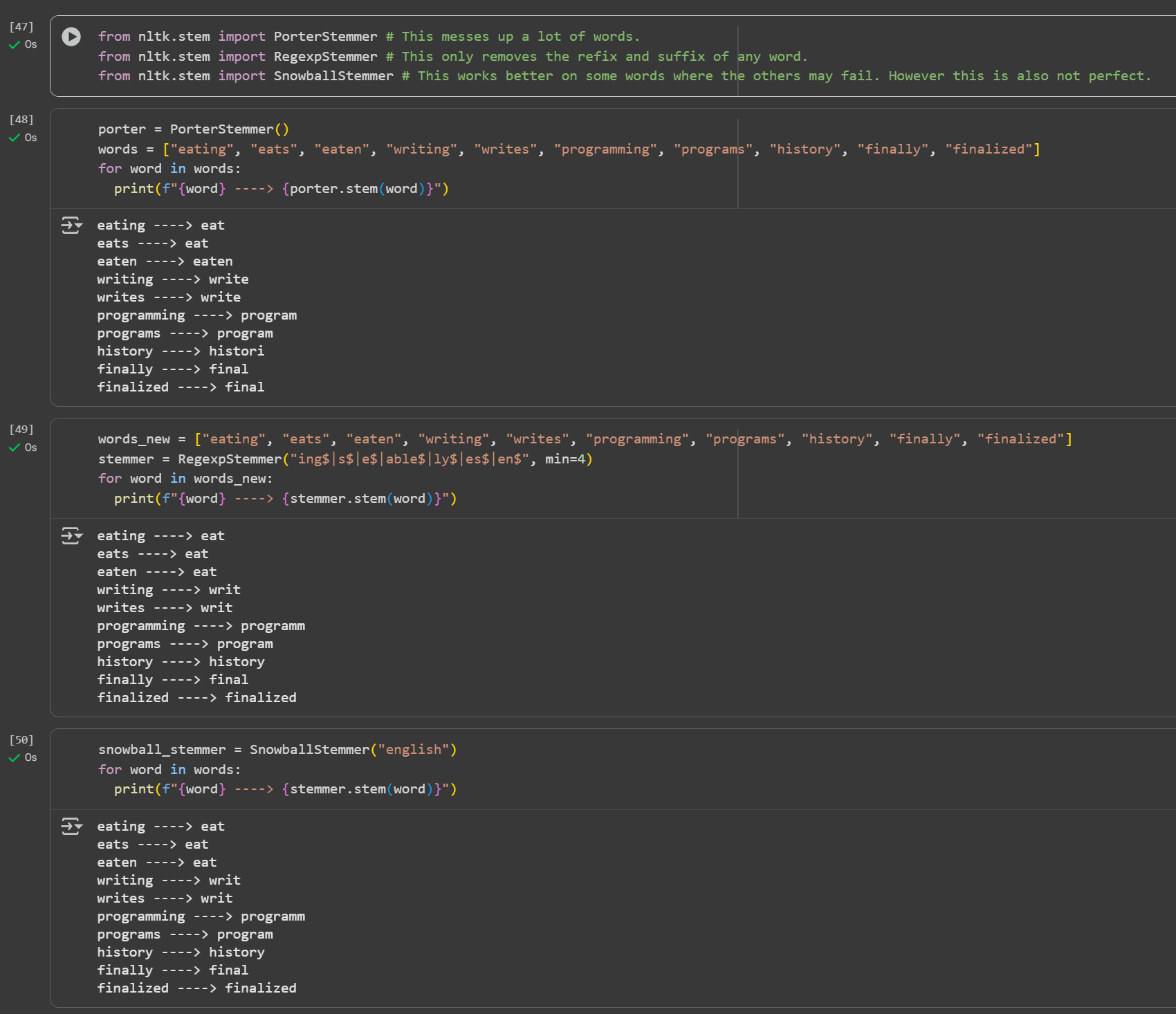





Sanskar
Keen Learner and Exp... • 6m
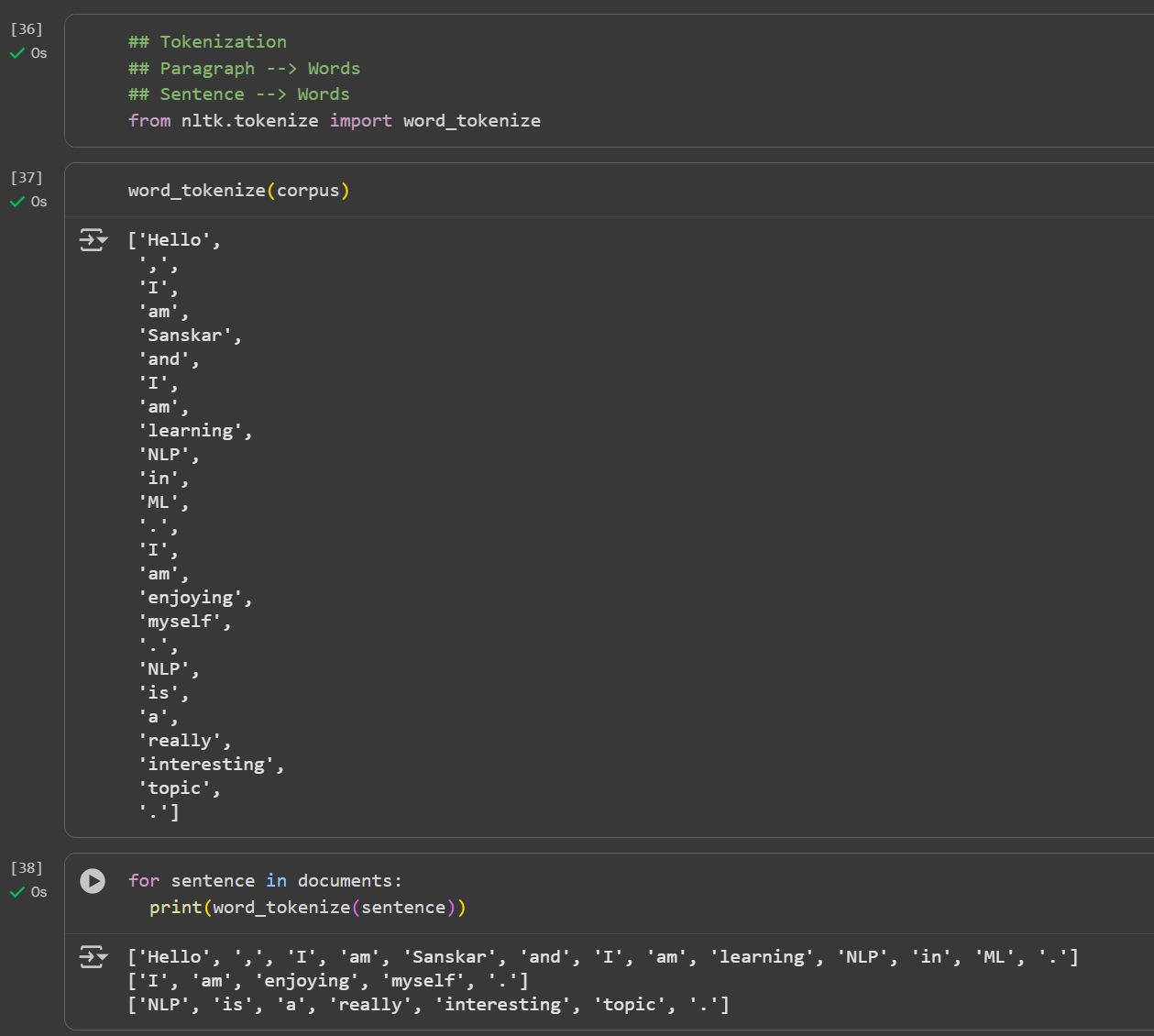
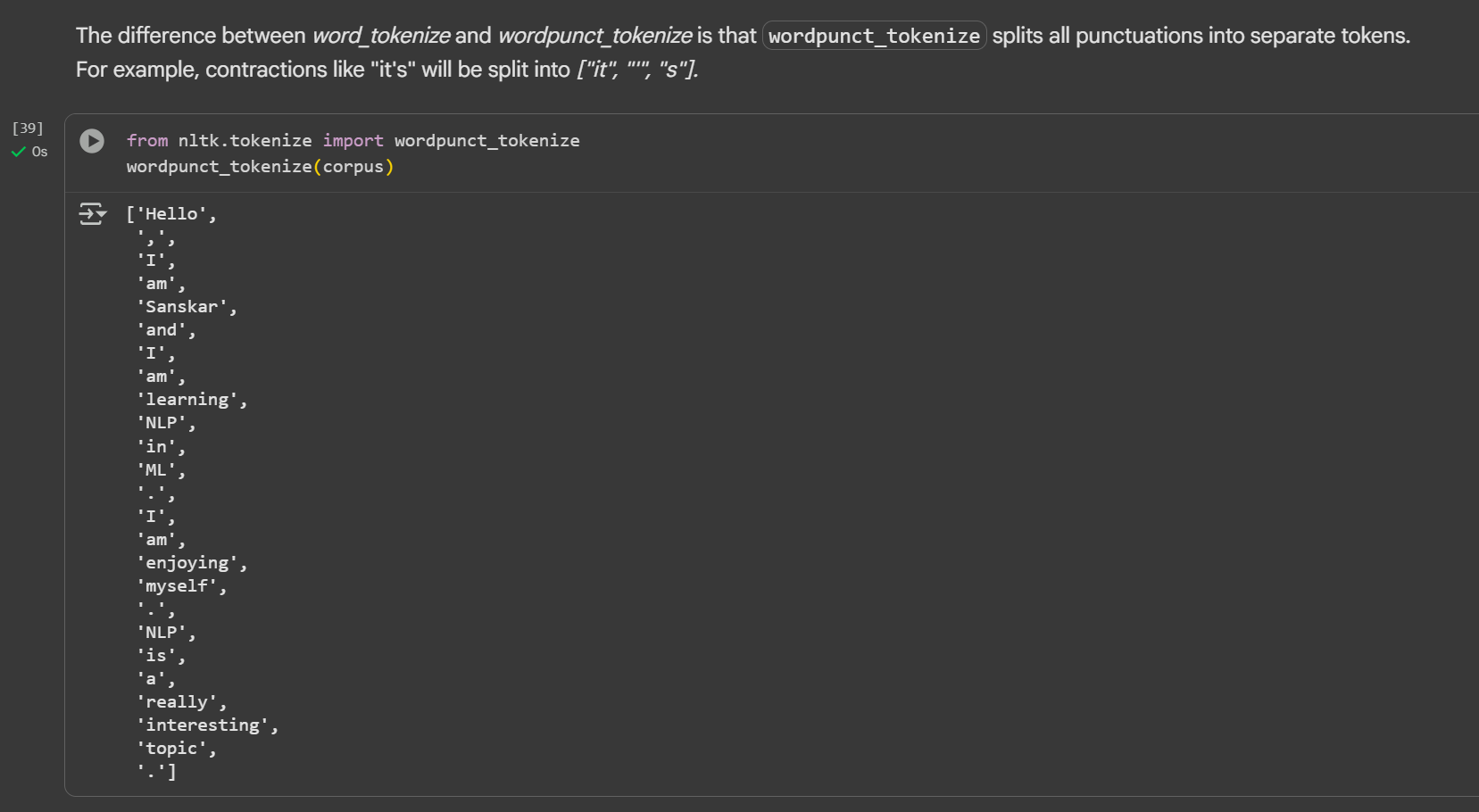
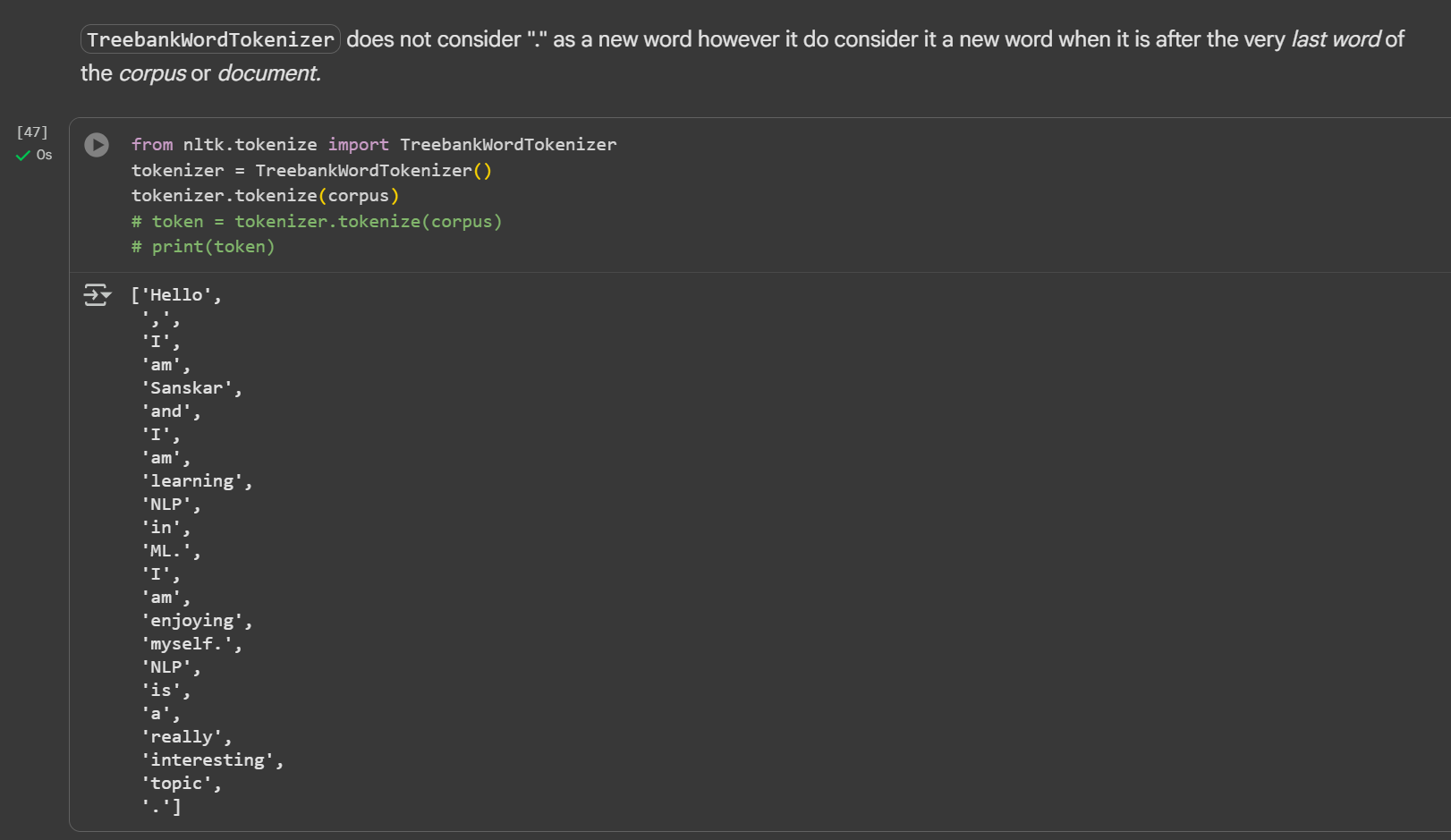
Day 3 of learning AI/ML as a beginner. Topic: NLP (Tokenization) Tokenization is breaking paragraph (corpus) or sentence (document) into smaller units called tokens. In order to perform tokenization we use nltk (natural language toolkit) python li
See More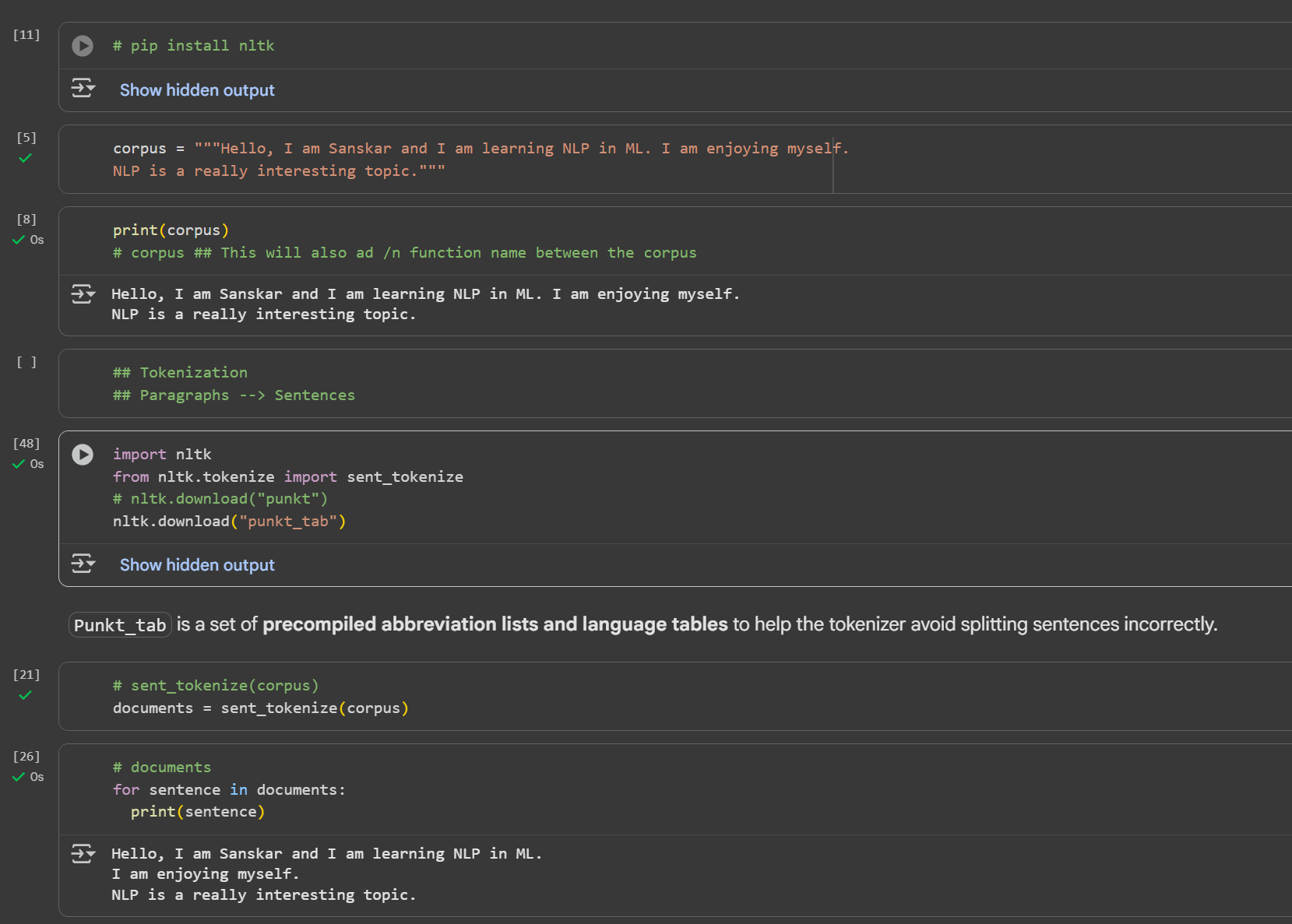


Sanskar
Keen Learner and Exp... • 6m
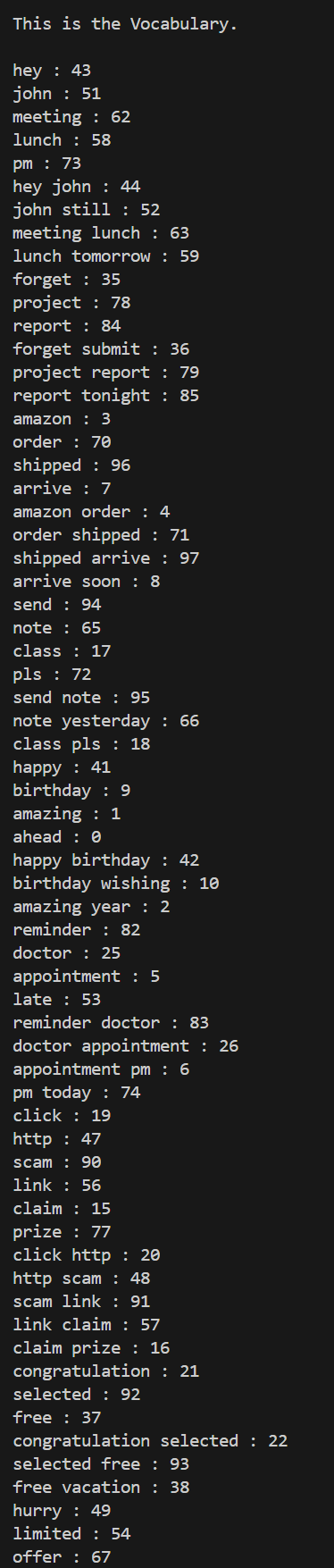
Day 10 of learning AI/ML as a beginner. Topic: N-Grams in Bag of Words (BOW). Yesterday I have talked about an amazing text to vector converter in machine learning i.e. Bag of Words (BOW). N-Gram is just a part of BOW. In BOW the program sees sente
See More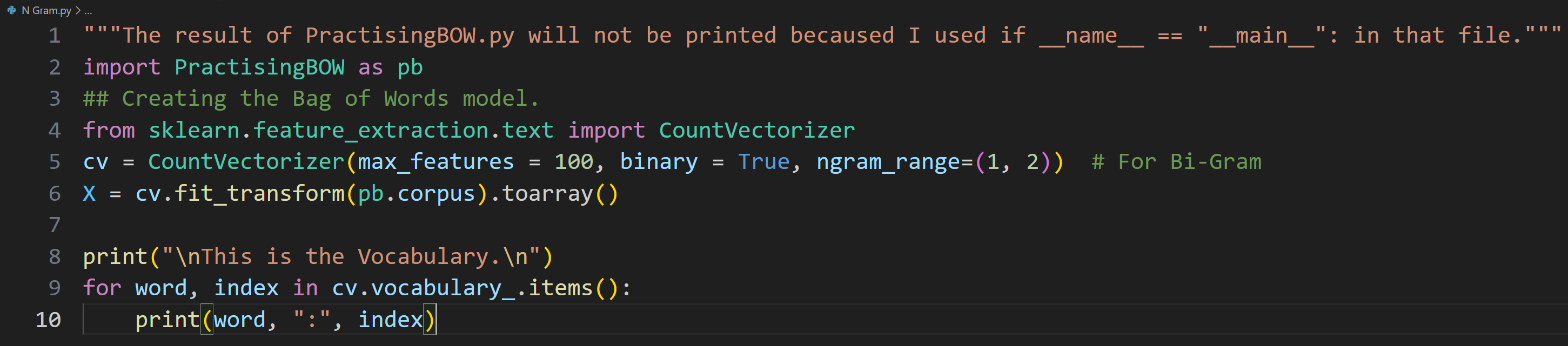


Prince Singh Chouhan
Front-end Developer • 1y
What is a Consensus algorithm in Blockchain? A consensus algorithm is a protocol used in blockchain networks, to ensure agreement among nodes on transaction validity and ledger state. It enables decentralized operation by providing agreement through
See More



/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)

























Download the medial app to read full posts, comements and news.