
Back

Sanskar
Keen Learner and Exp... • 6m
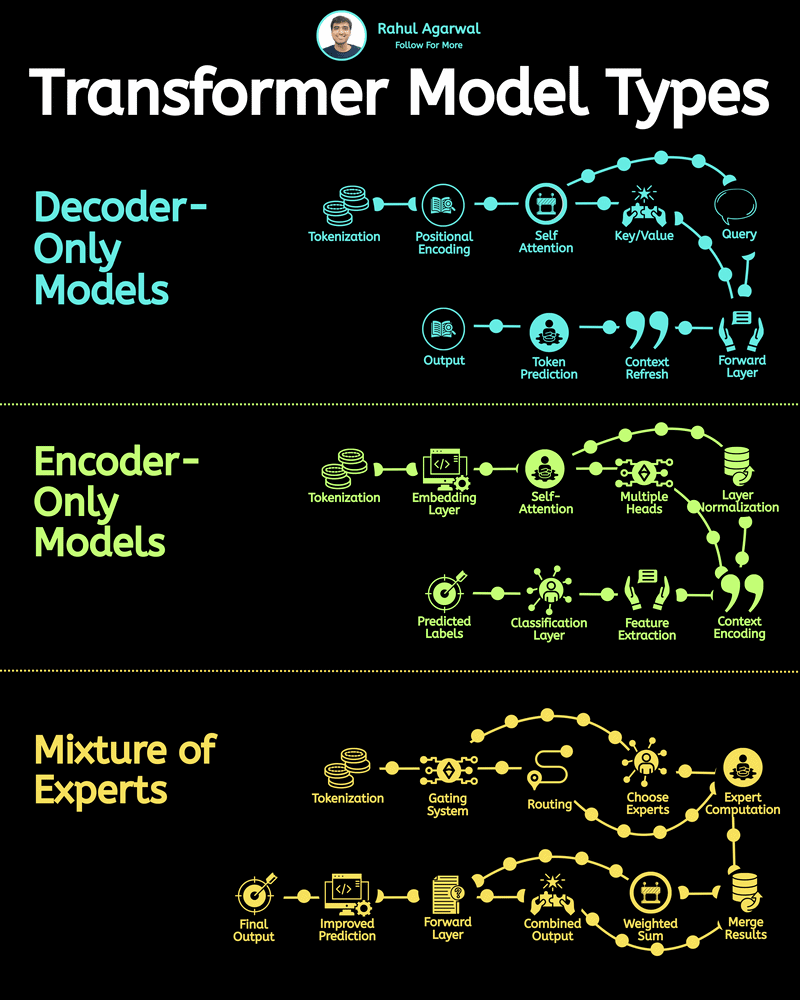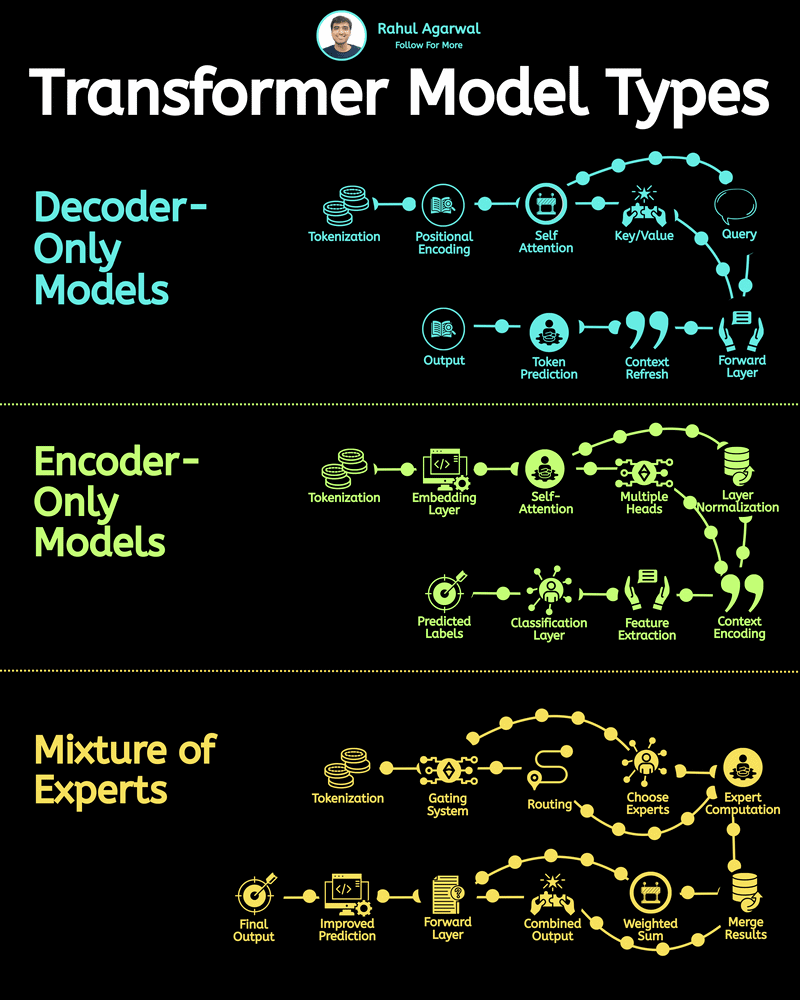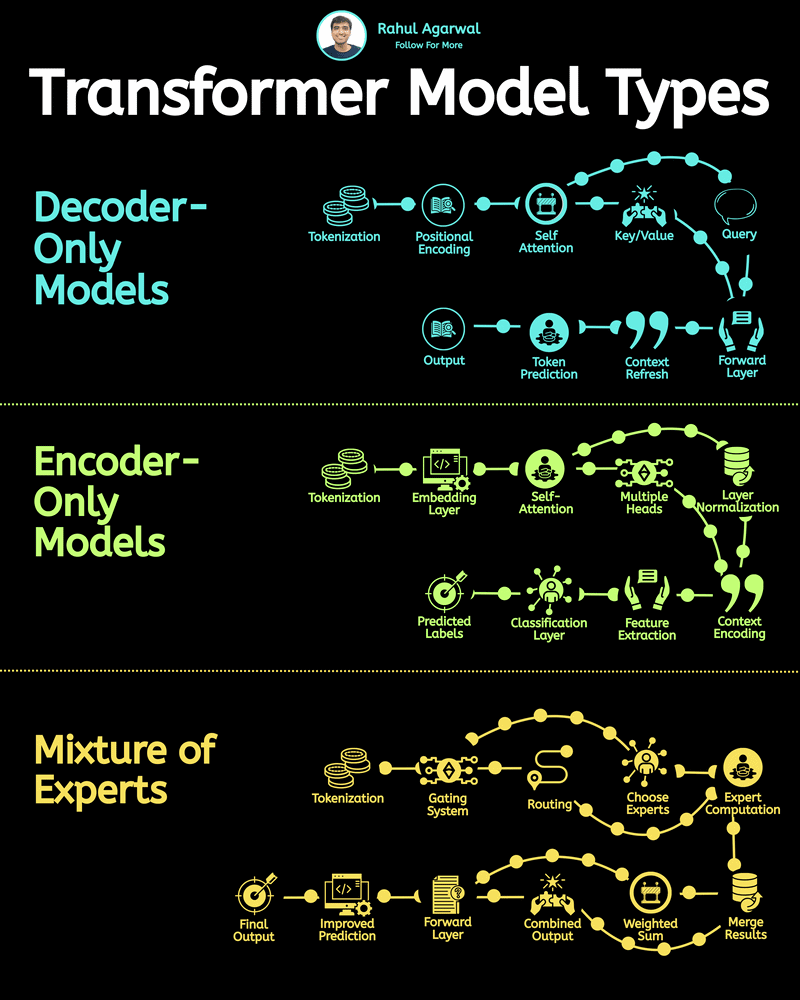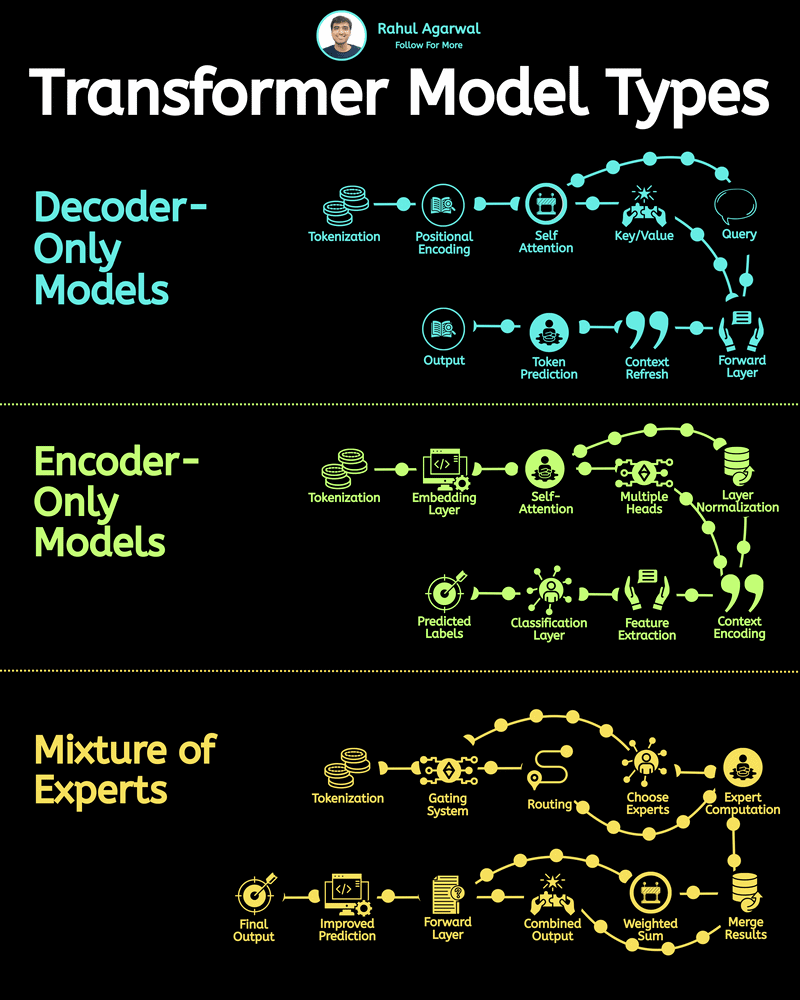
Day 2 of learning AI/ML as a beginner. Topic: text preprocessing (tokenization) in NLP. I have moved further and decided to learn about Natural Language Process(NLP) which is used especially for translations, chatbots, and help them to generate human like responses (in human readable language). I have also created a roadmap of learning NLP which I will be following to learn it in a more structured manner. I have already started with text preprocessing theory more specifically of tokenization. Tokenization is the process of breaking down text into smaller units called tokens. These tokens can be sentences or even words depending upon the level of tokenization applied. Tokenization have four main technical jargons namely: 1. Corpus - this refers to paragraphs. 2. Documents - this refers to sentences. 3. Vocabulary - these are the unique words used in a sentence or paragraph. 4. Words - these are the normal words we use. Tokenization typically depends upon the use of punctuation in order to create tokens. I have scratched the surface of NLP and will most probably apply this practically in my python code. I will warmly welcome all the questions, suggestions, recommendations and "constructive" criticism (the one which contains the problem and its likely solution, I will research the rest). And also here are my notes which I made while learning this.




More like this
Recommendations from Medial


Sanskar
Keen Learner and Exp... • 6m
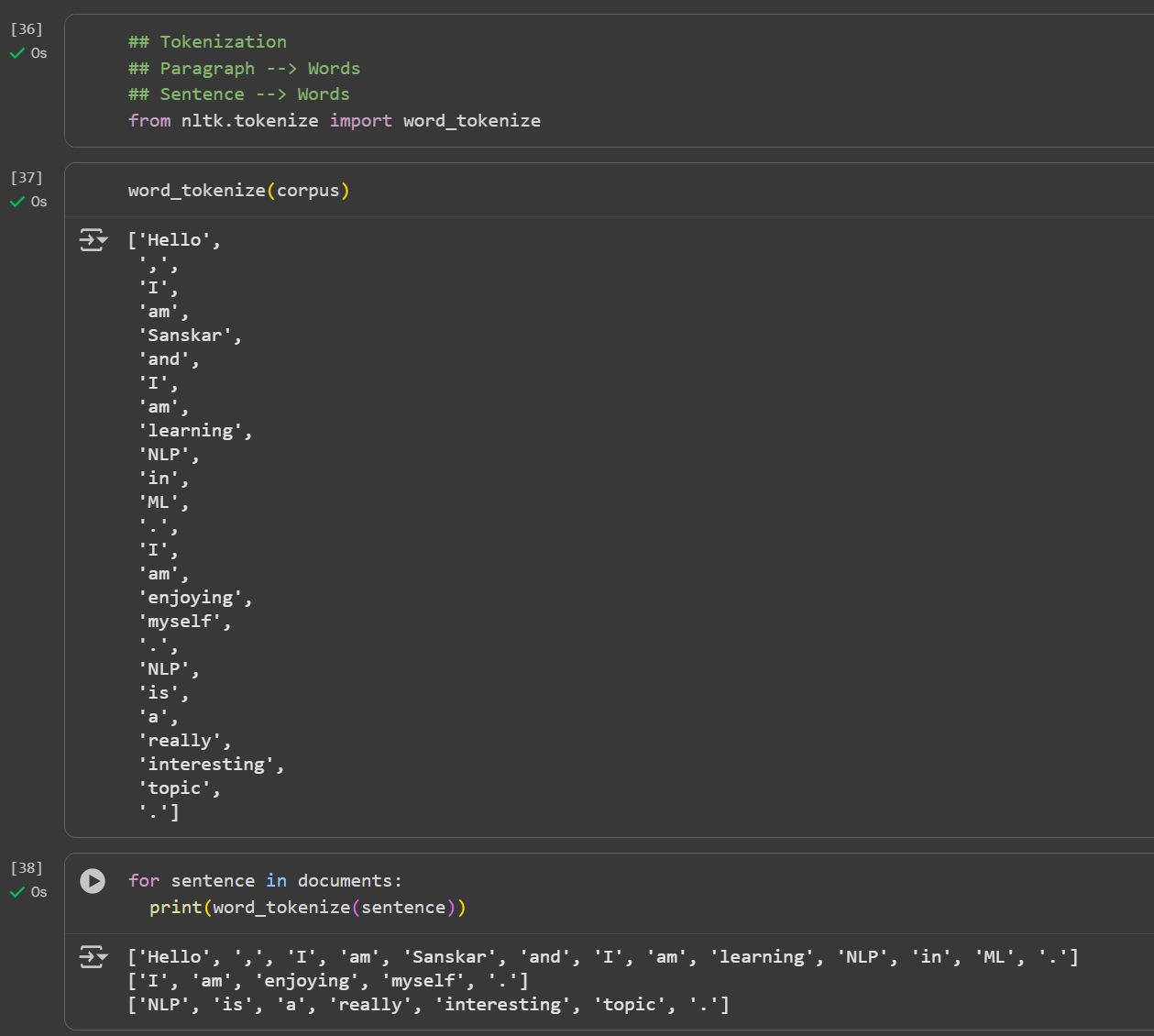
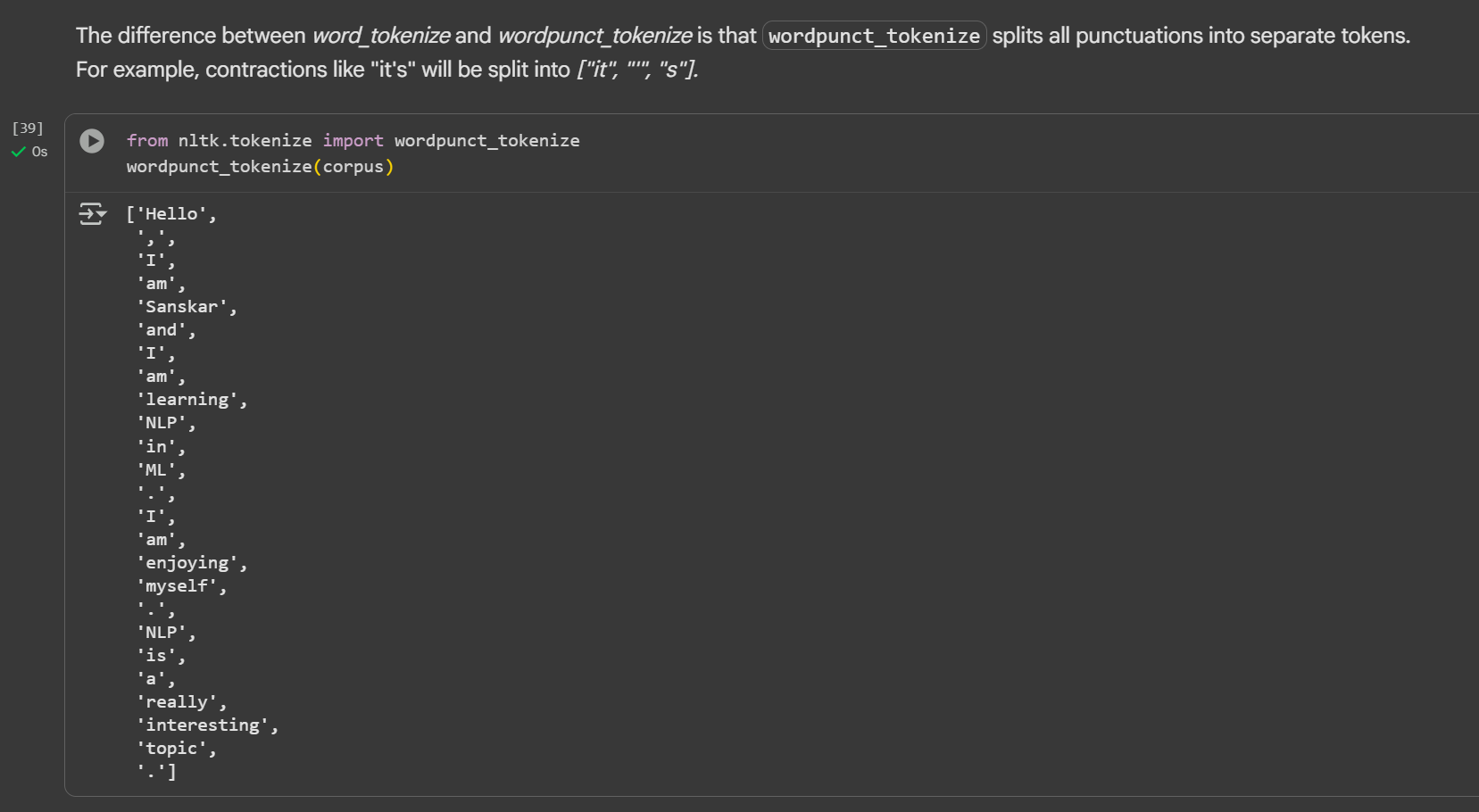
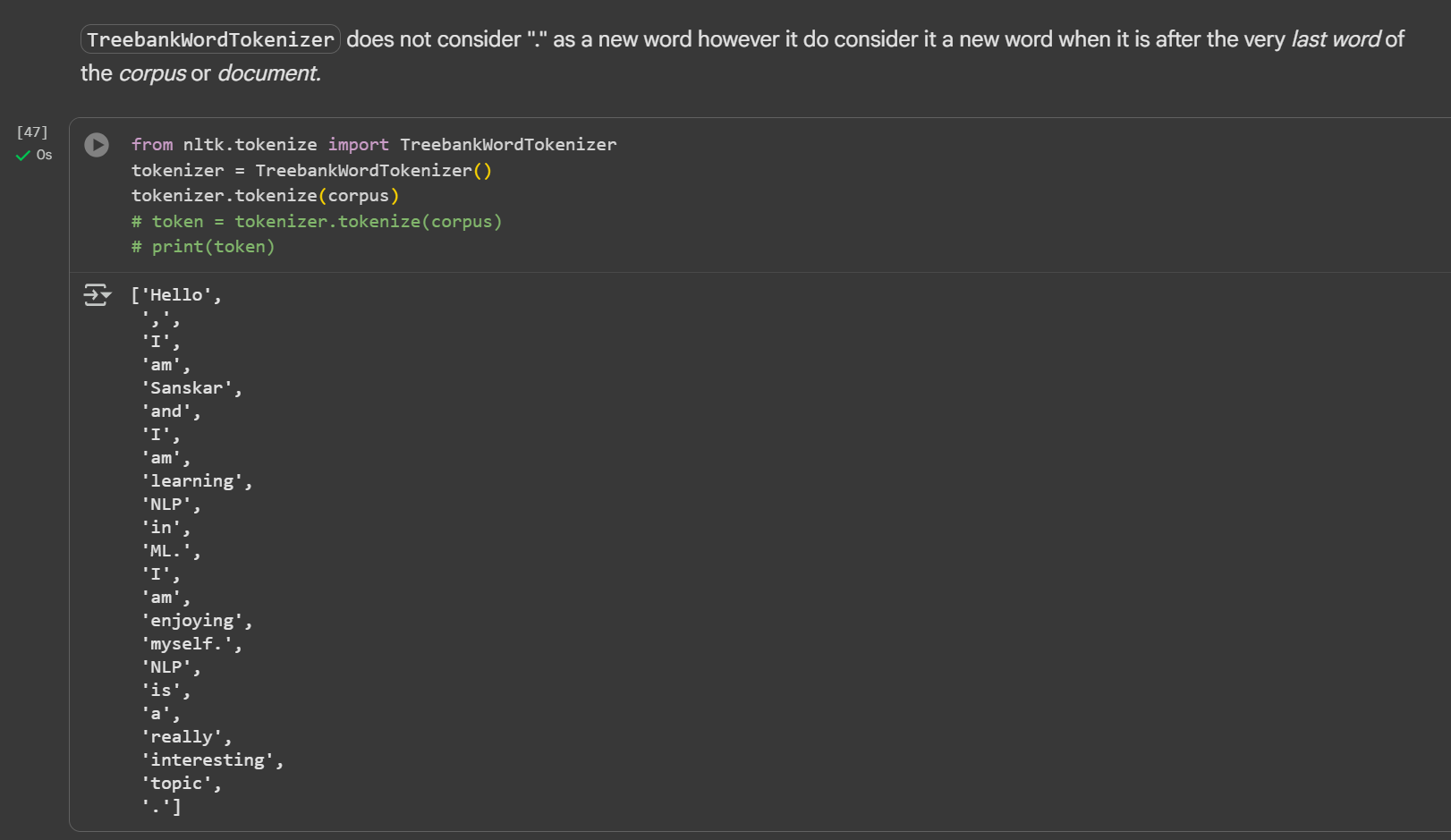
Day 3 of learning AI/ML as a beginner. Topic: NLP (Tokenization) Tokenization is breaking paragraph (corpus) or sentence (document) into smaller units called tokens. In order to perform tokenization we use nltk (natural language toolkit) python li
See More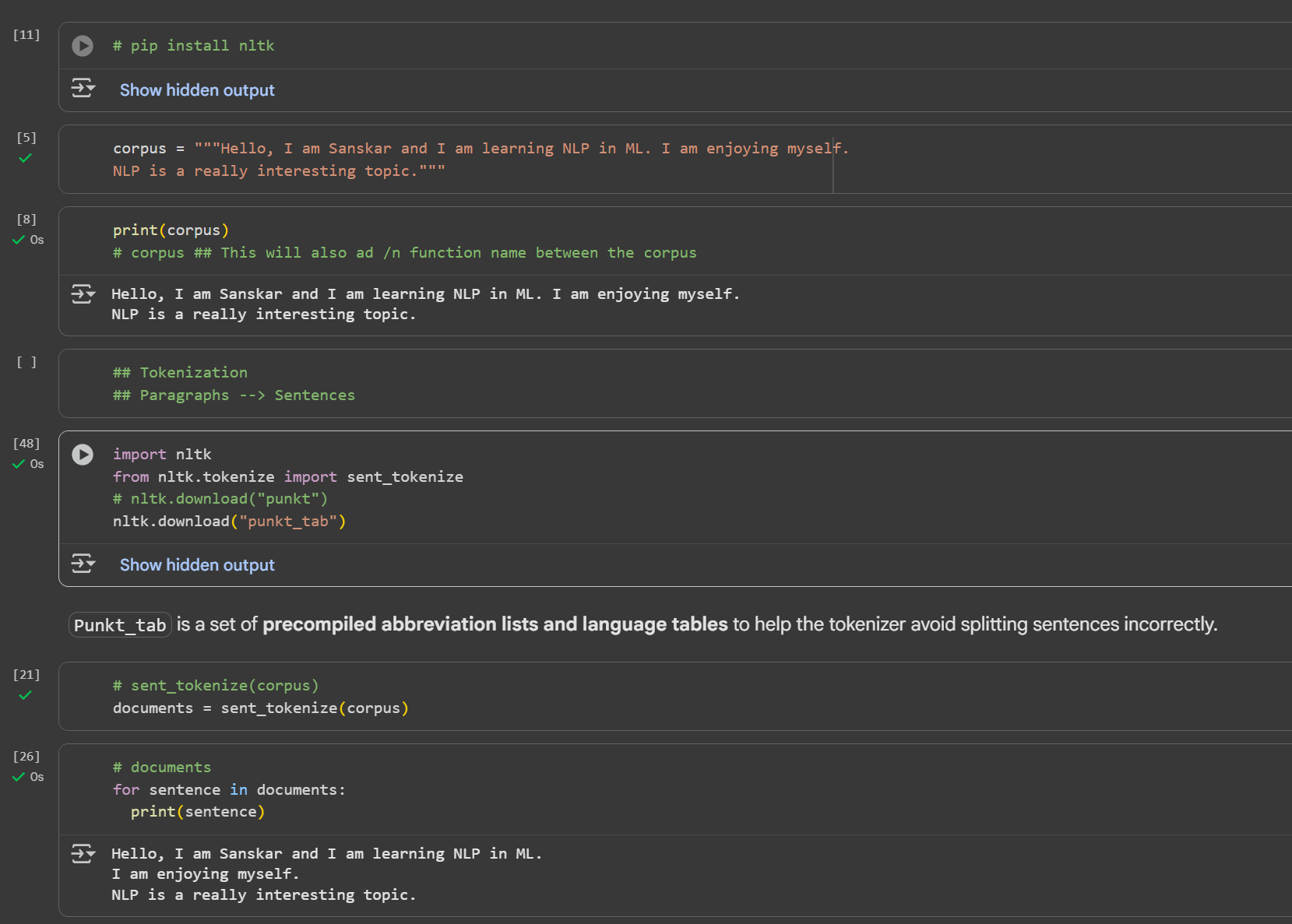

Sanskar
Keen Learner and Exp... • 6m
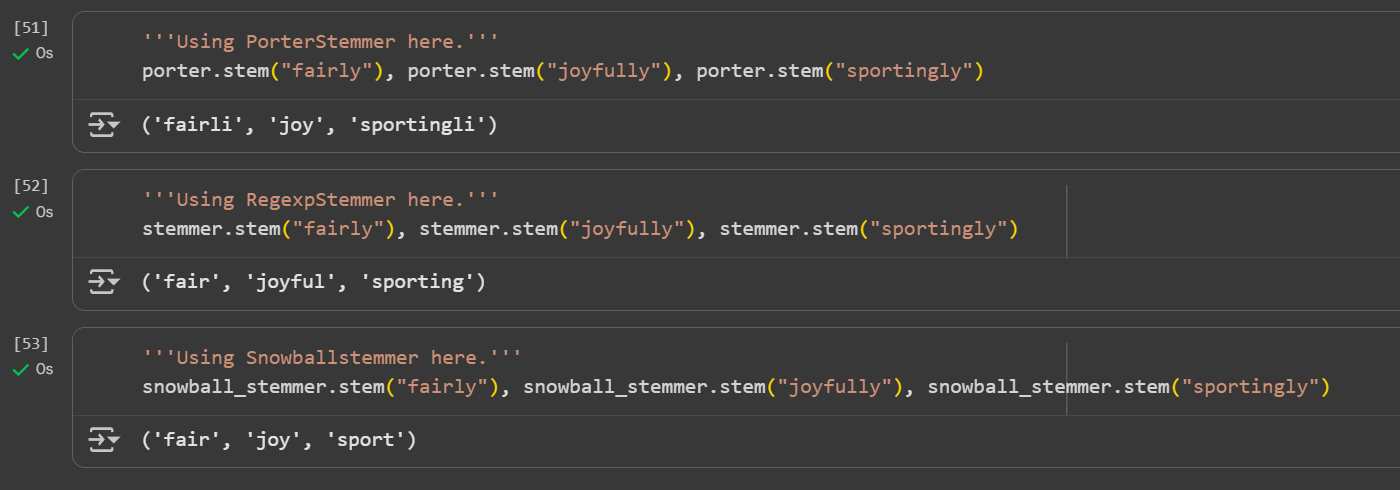
Day 4 of learning AI/ML as a beginner. Topic: text preprocessing stemming using NLTK. I have learned about tokenization and now I am learning about text preprocessing in ML. Text preprocessing is cleaning up of raw text (raw text is the one entered
See More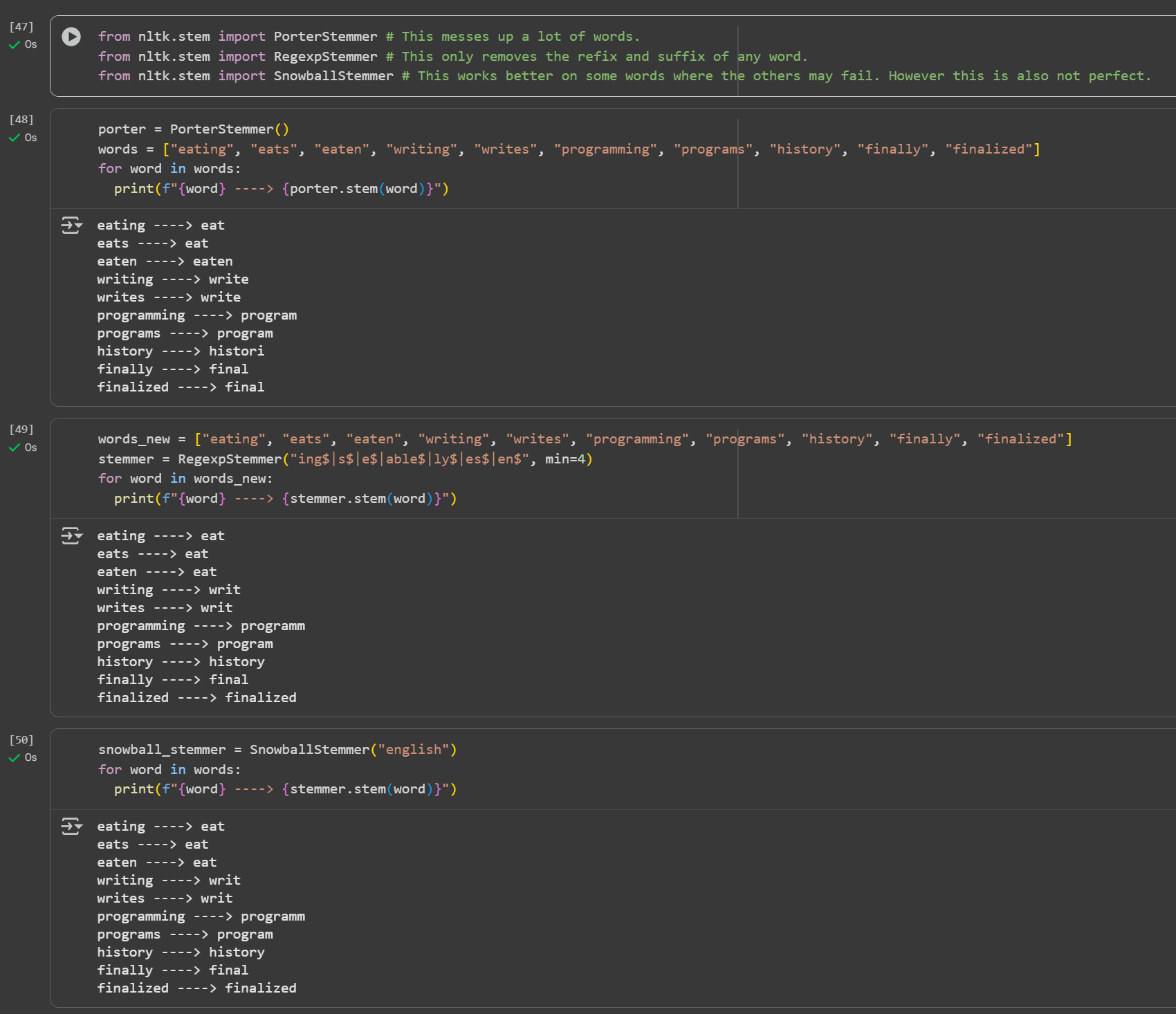
Sanskar
Keen Learner and Exp... • 6m
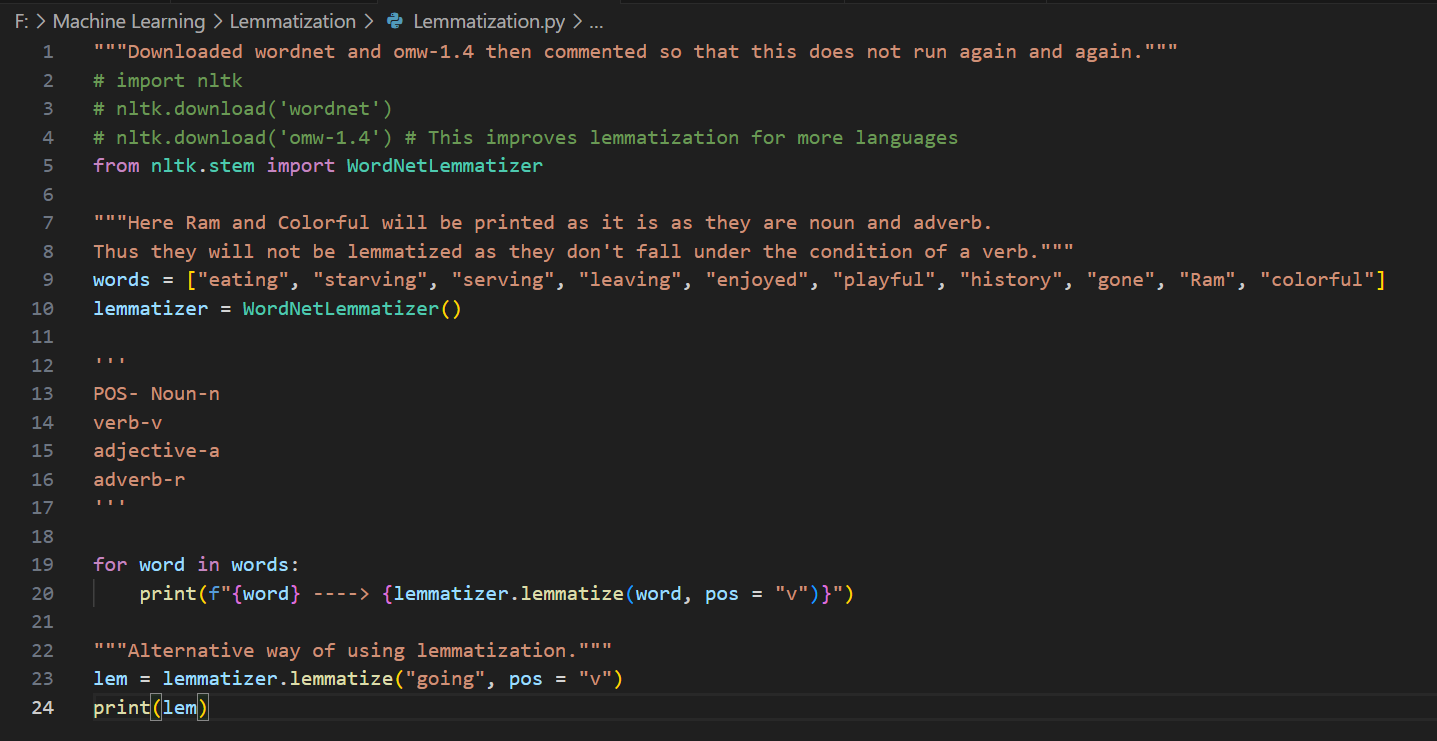
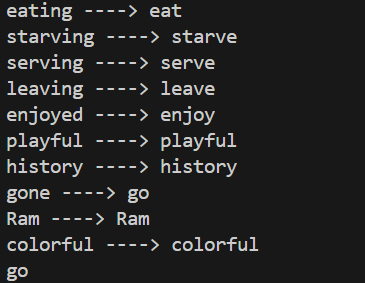
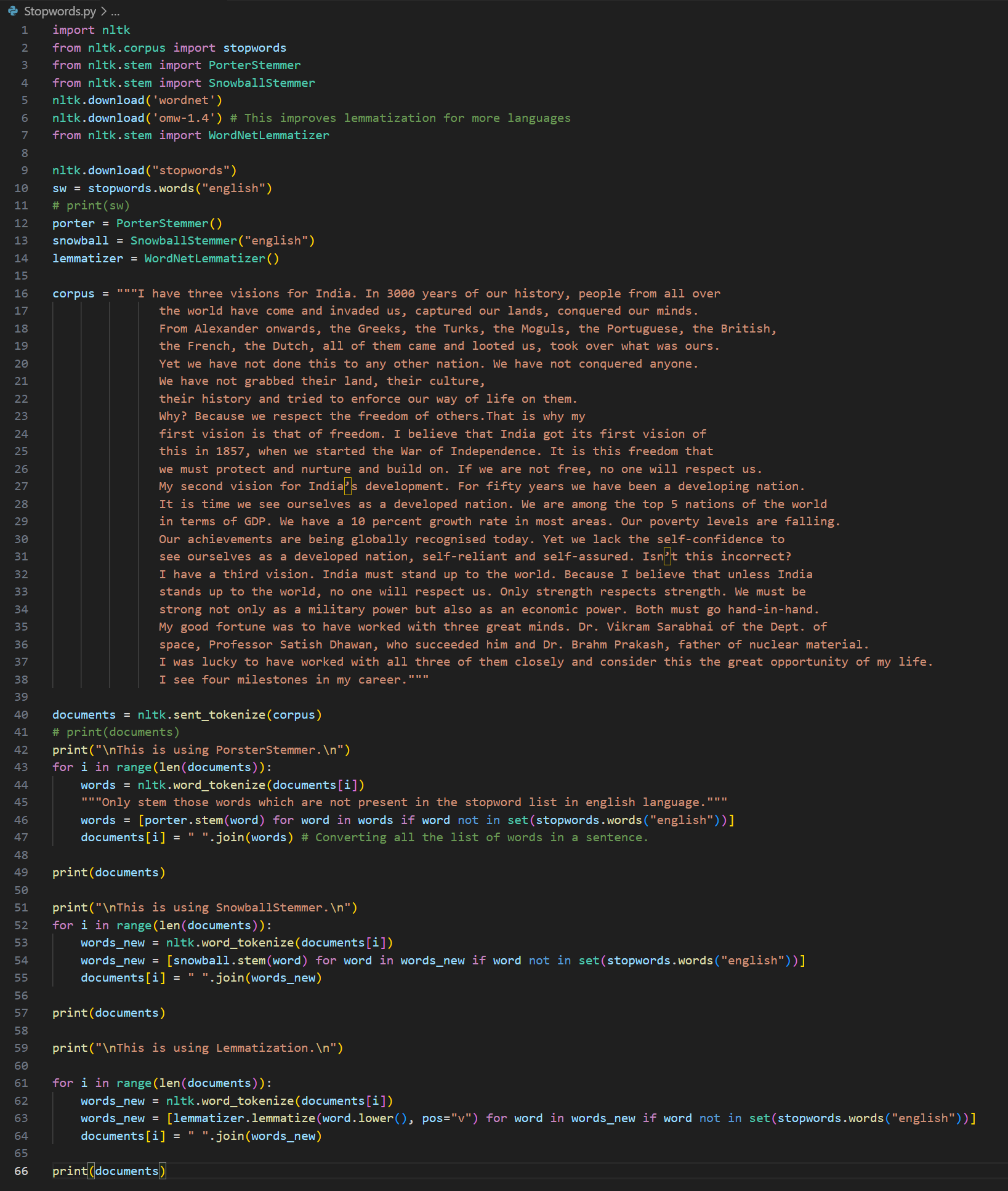
Day 8 of learning AI/ML as a beginner. Topic: Bag of Words (BOW) Yesterday I told you guys about One Hot Encoding which is one way to convert text into vector however with serious disadvantages and to cater to those disadvantages there's another on
See More


Sanskar
Keen Learner and Exp... • 6m
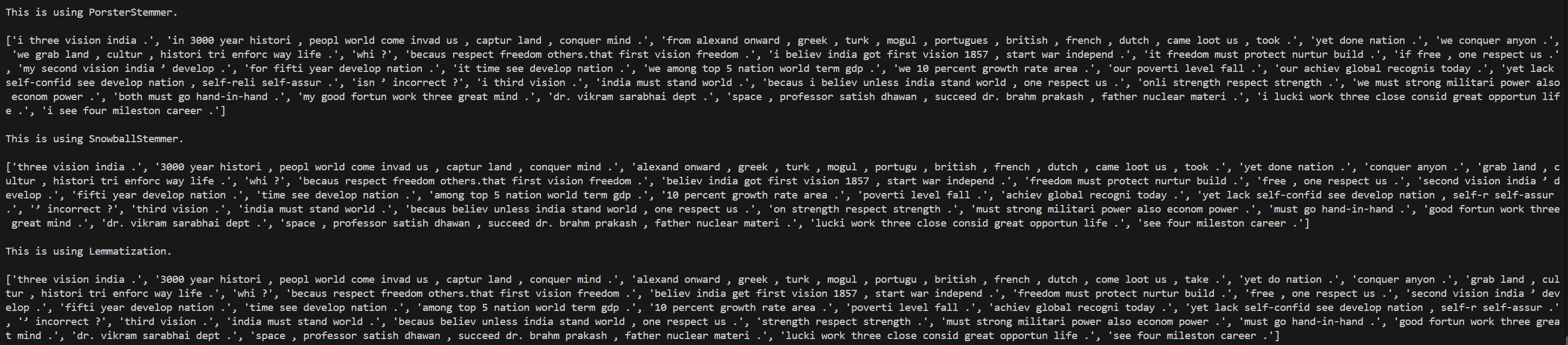
Day 9 of learning AI/ML as a beginner. Topic: Bag of Words practical. Yesterday I shared the theory about bag of words and now I am sharing about the practical I did I know there's still a lot to learn and I am not very much satisfied with the topi
See More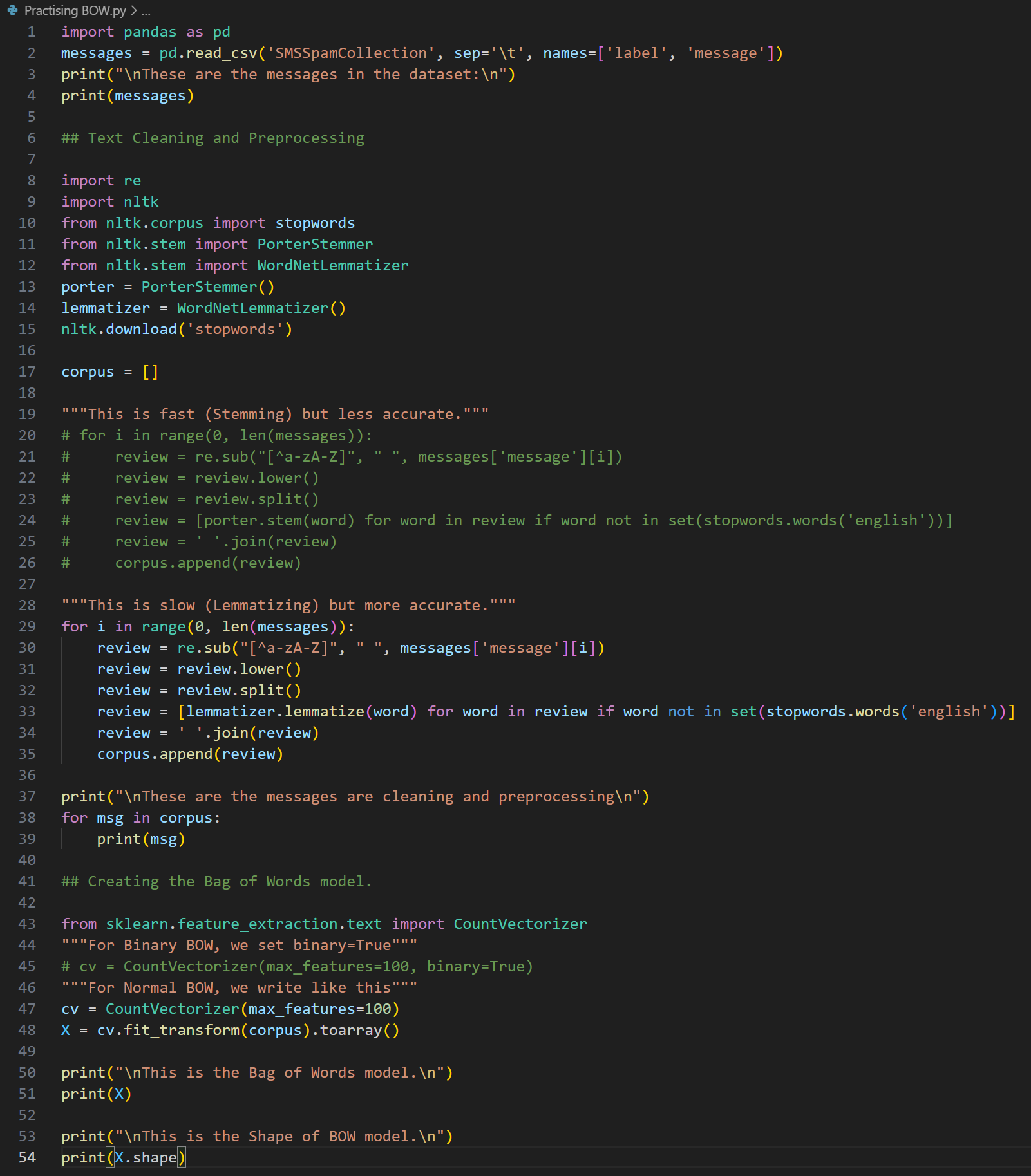

Sanskar
Keen Learner and Exp... • 6m
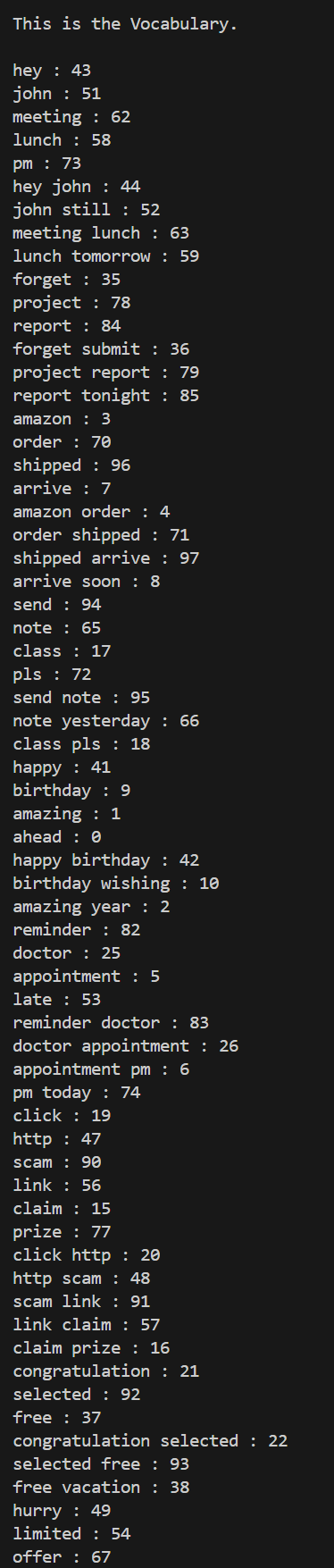
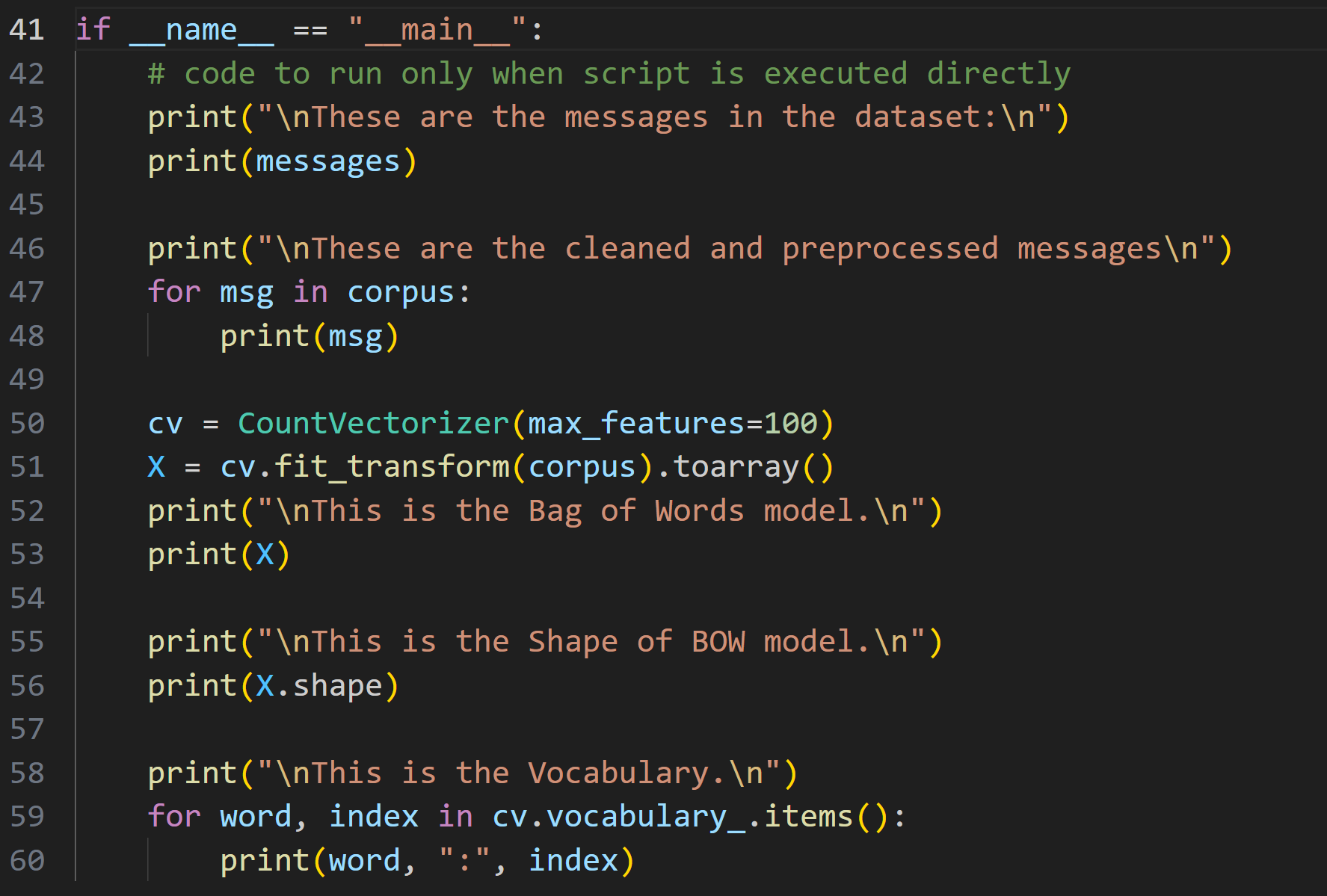
Day 10 of learning AI/ML as a beginner. Topic: N-Grams in Bag of Words (BOW). Yesterday I have talked about an amazing text to vector converter in machine learning i.e. Bag of Words (BOW). N-Gram is just a part of BOW. In BOW the program sees sente
See More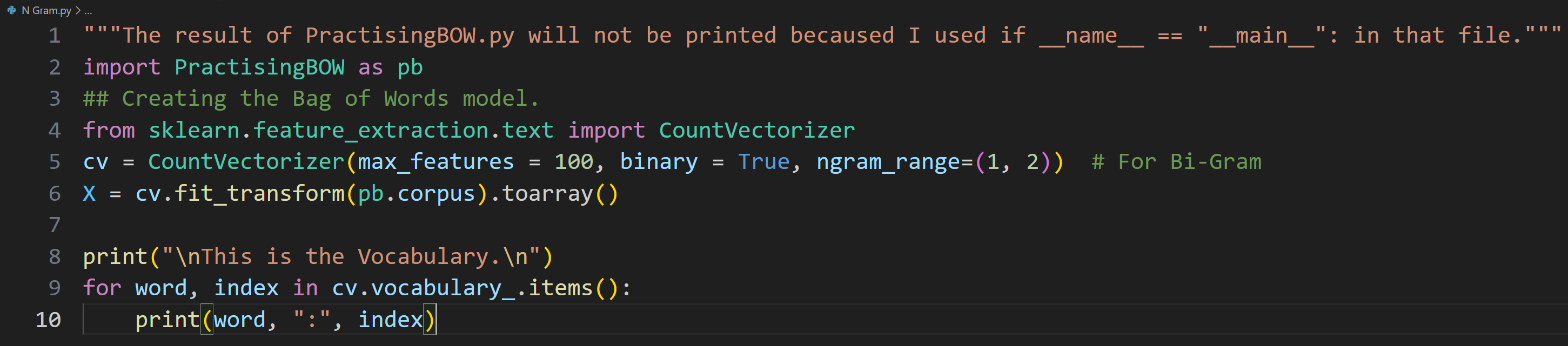








/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)























Download the medial app to read full posts, comements and news.