
Back

Sanskar
Keen Learner and Exp... • 6m
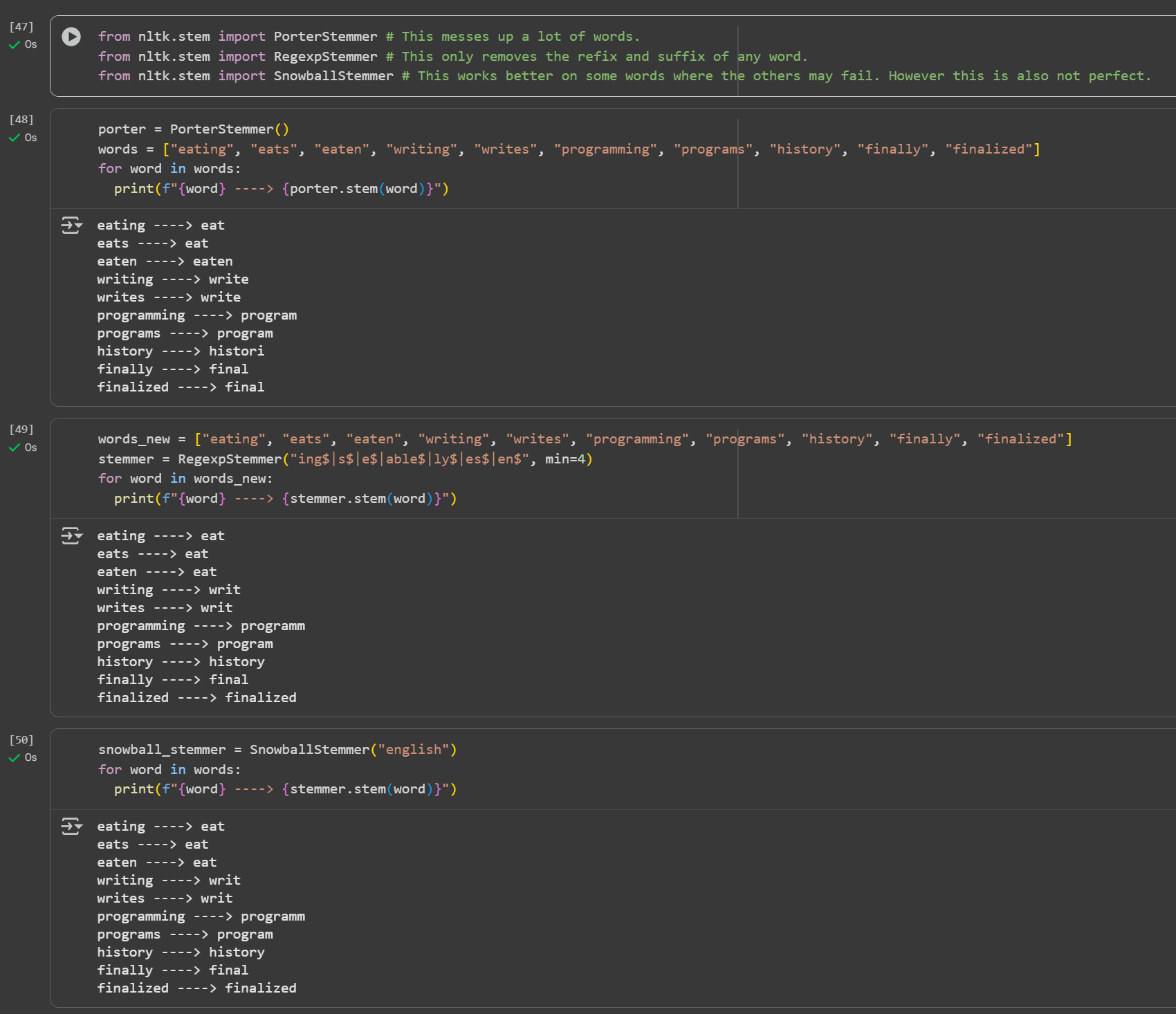
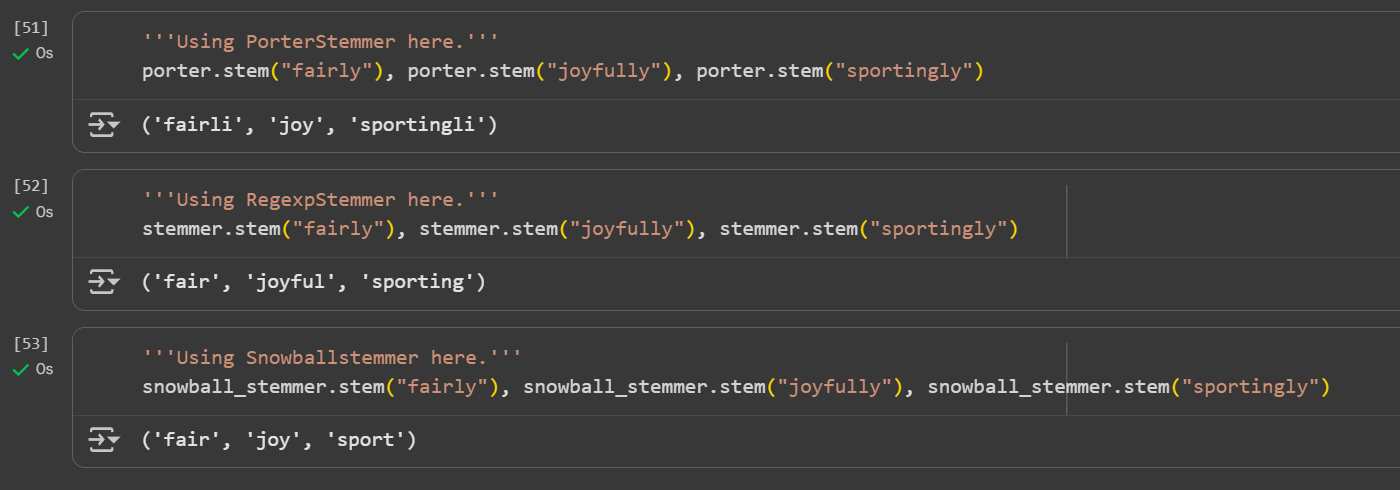
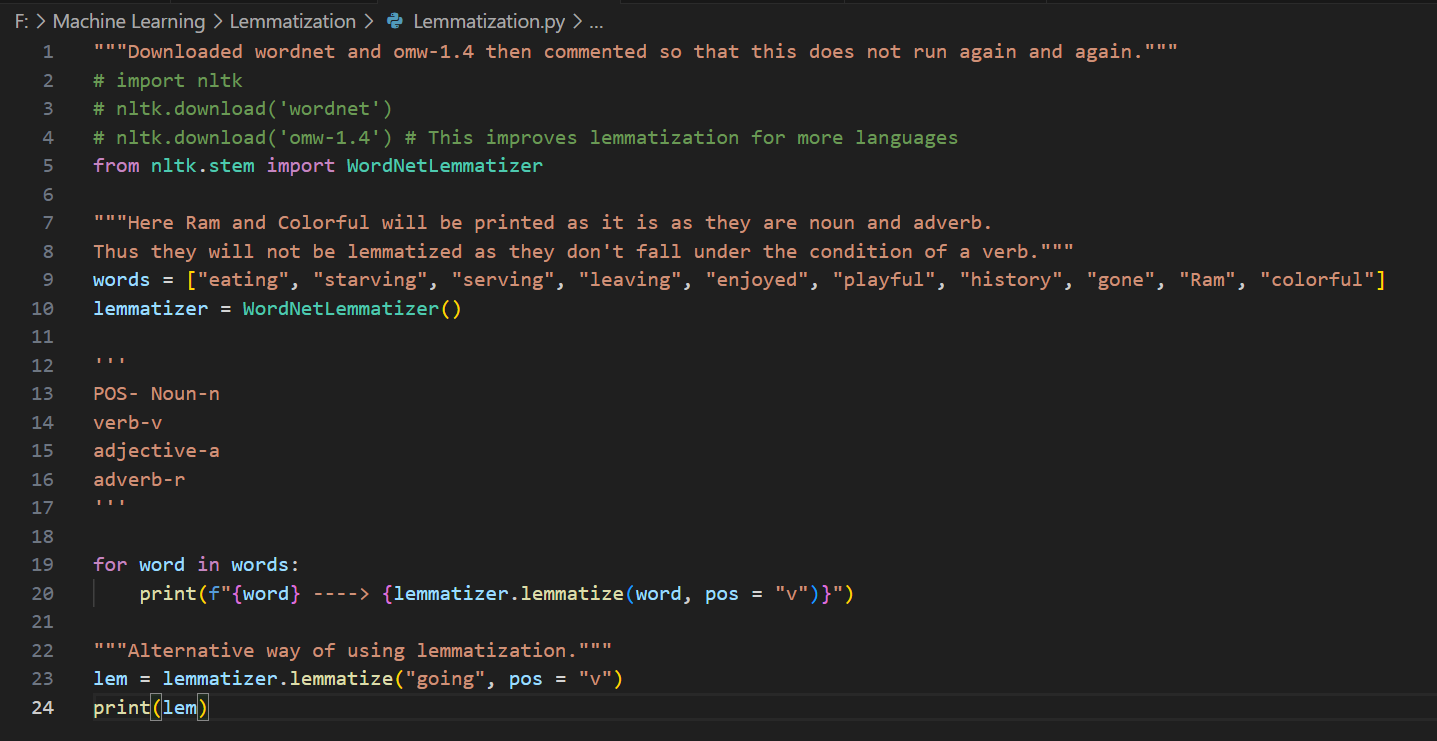
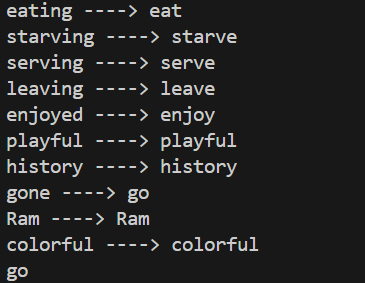
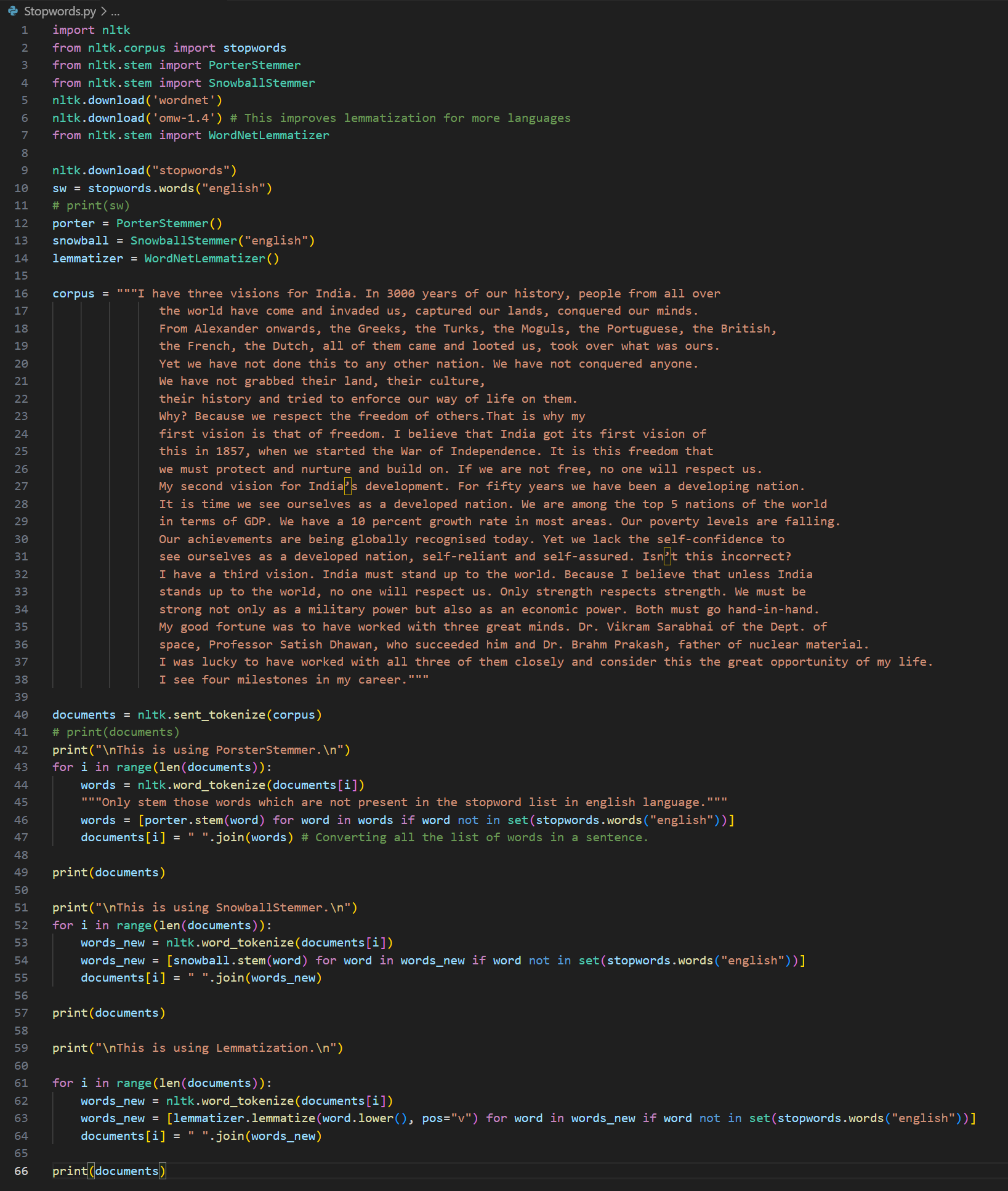
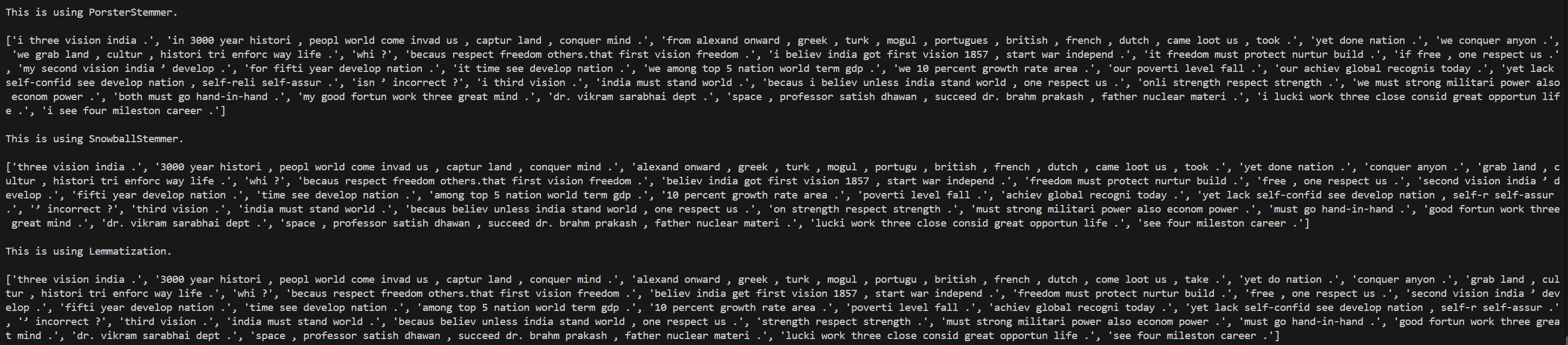
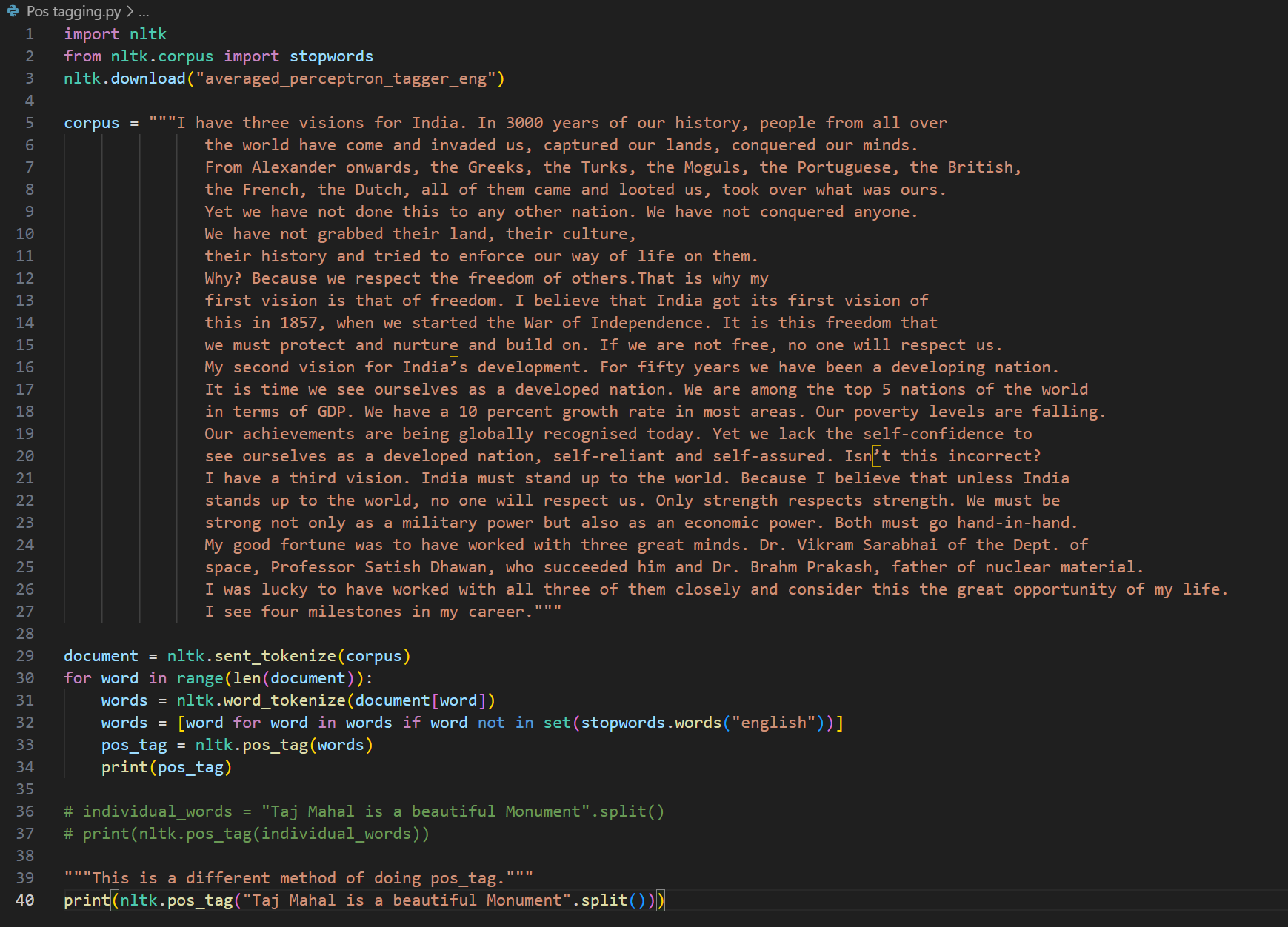
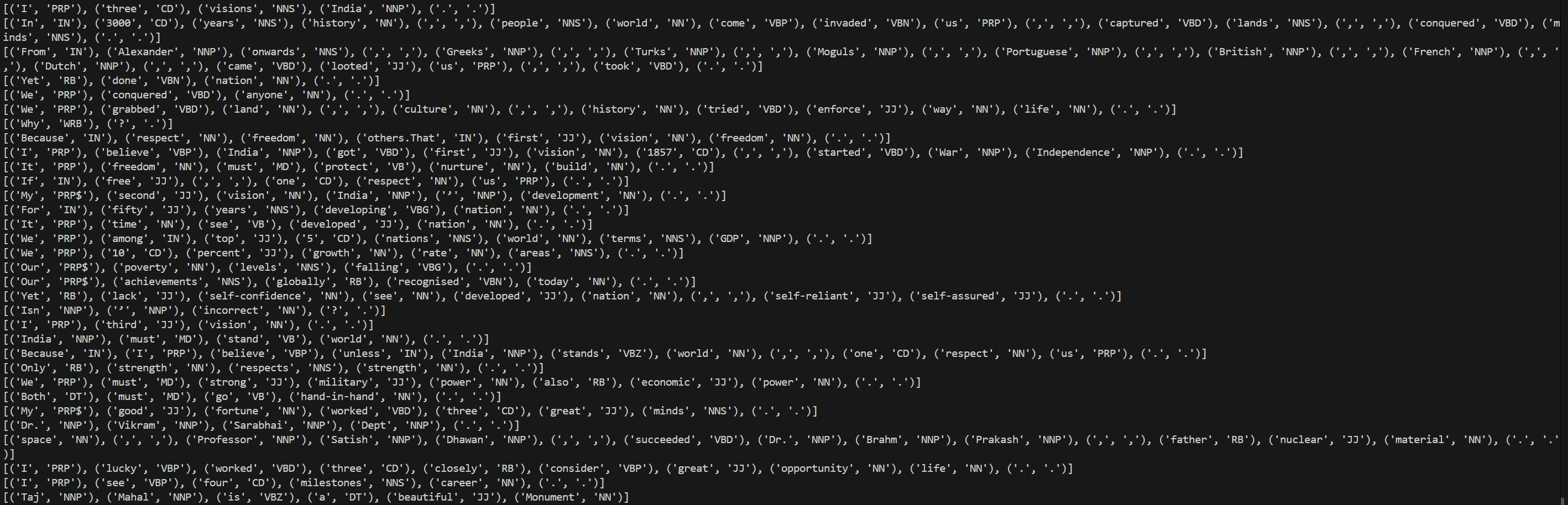
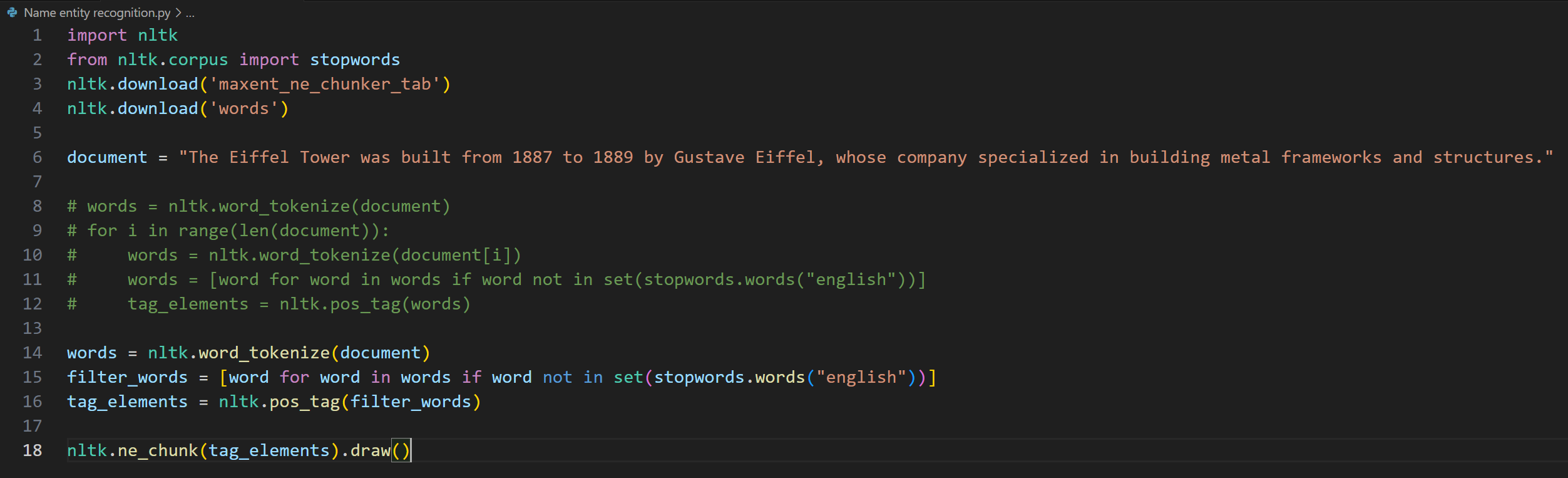
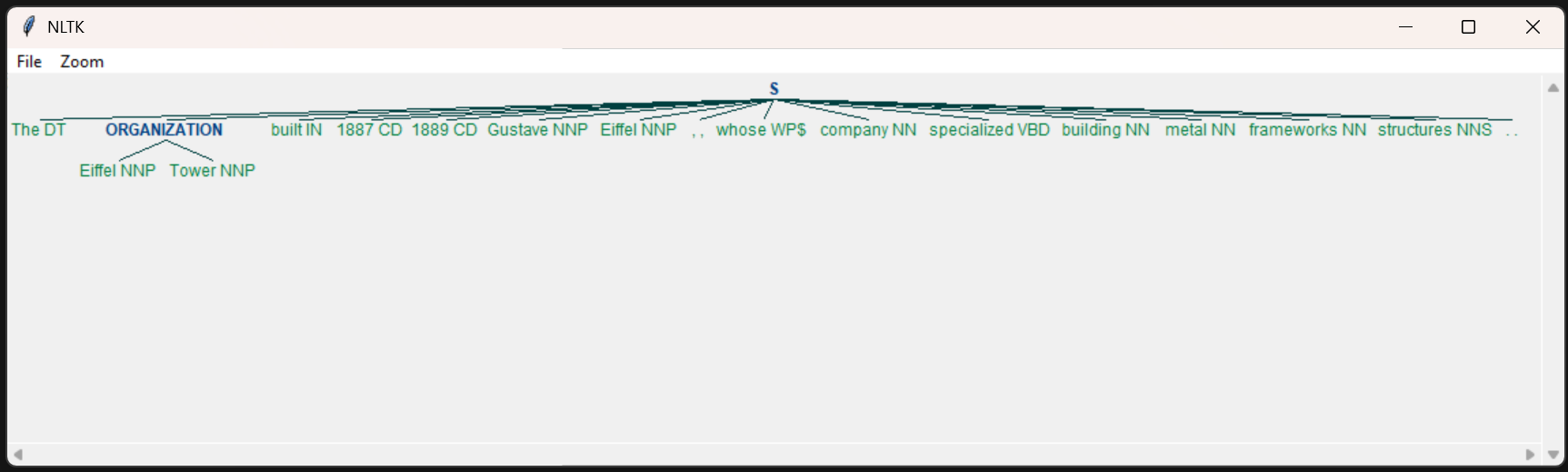
Day 4 of learning AI/ML as a beginner. Topic: text preprocessing stemming using NLTK. I have learned about tokenization and now I am learning about text preprocessing in ML. Text preprocessing is cleaning up of raw text (raw text is the one entered by the user) to make it usable in Natural Language processing (NLP) and in Machine Learning (ML) models. Stemming is the process of removing prefix and suffix from a word in order to achieve its root word. For example: eating consists of a suffix "ing" and its root word is eat. We use stemming to group similar meanings words and to reduce the size of vocabulary (unique word in a document or corpus). Stemming can be achieved using various libraries in Natural Language Tool Kit (NLTK). Such libraries includes: 1. PorterStemmer: this is one of the oldest and most popular stemmer used in removing common suffix however it's performance decline as the level of words increases (sometimes this messes up the words and produce results which may not be real). 2. RegexpStemmer: this is a very simple yet a powerful rule based stemmer. This uses regular expression's rules to identify the prefix and suffix in a word and removes it in order to find the root word. This is flexible and better than PorterStemmer however it also makes some mistakes. 3. SnowballStemmer a.k.a Porter2 Stemmer: as the name suggests this is an improved version of PorterStemmer. This is more consistent and accurate as compare to PorterStemmer and also supports multiple languages. I welcome all the questions and suggestions which will help me understand these concepts more clearly and develop a deeper understanding. Also here's my code and it's result.
Replies (2)

More like this
Recommendations from Medial


Sanskar
Keen Learner and Exp... • 6m
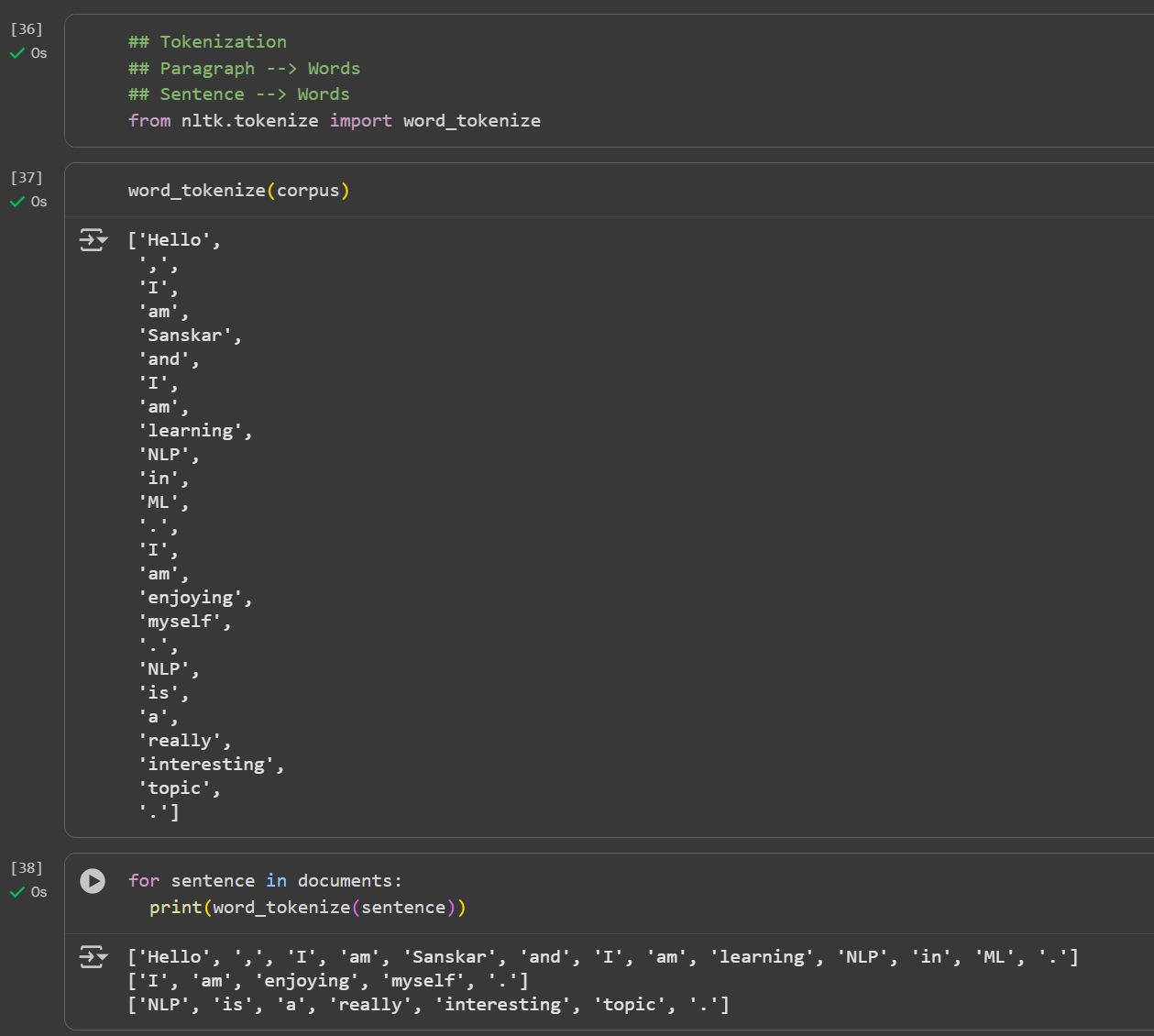
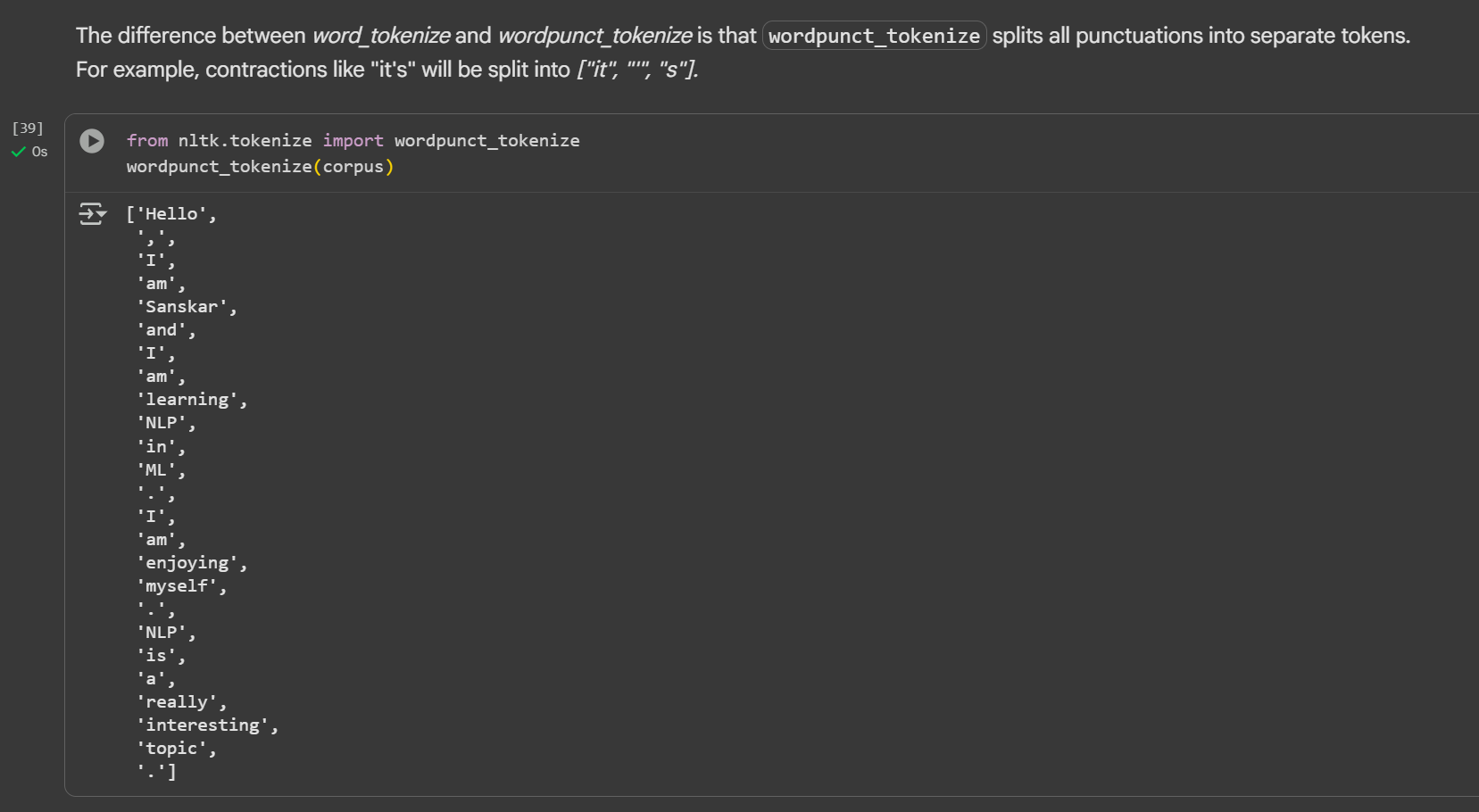
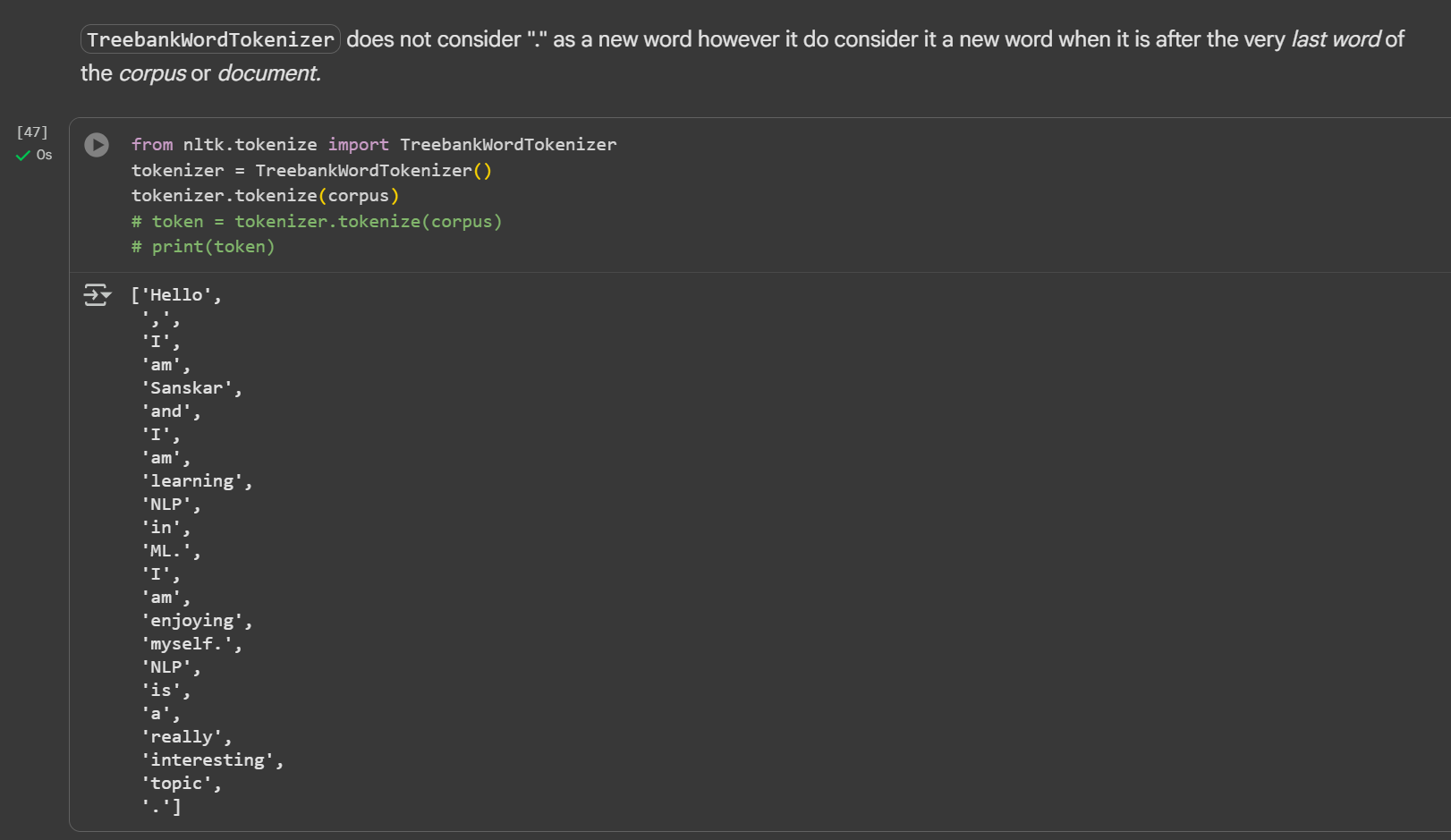
Day 3 of learning AI/ML as a beginner. Topic: NLP (Tokenization) Tokenization is breaking paragraph (corpus) or sentence (document) into smaller units called tokens. In order to perform tokenization we use nltk (natural language toolkit) python li
See More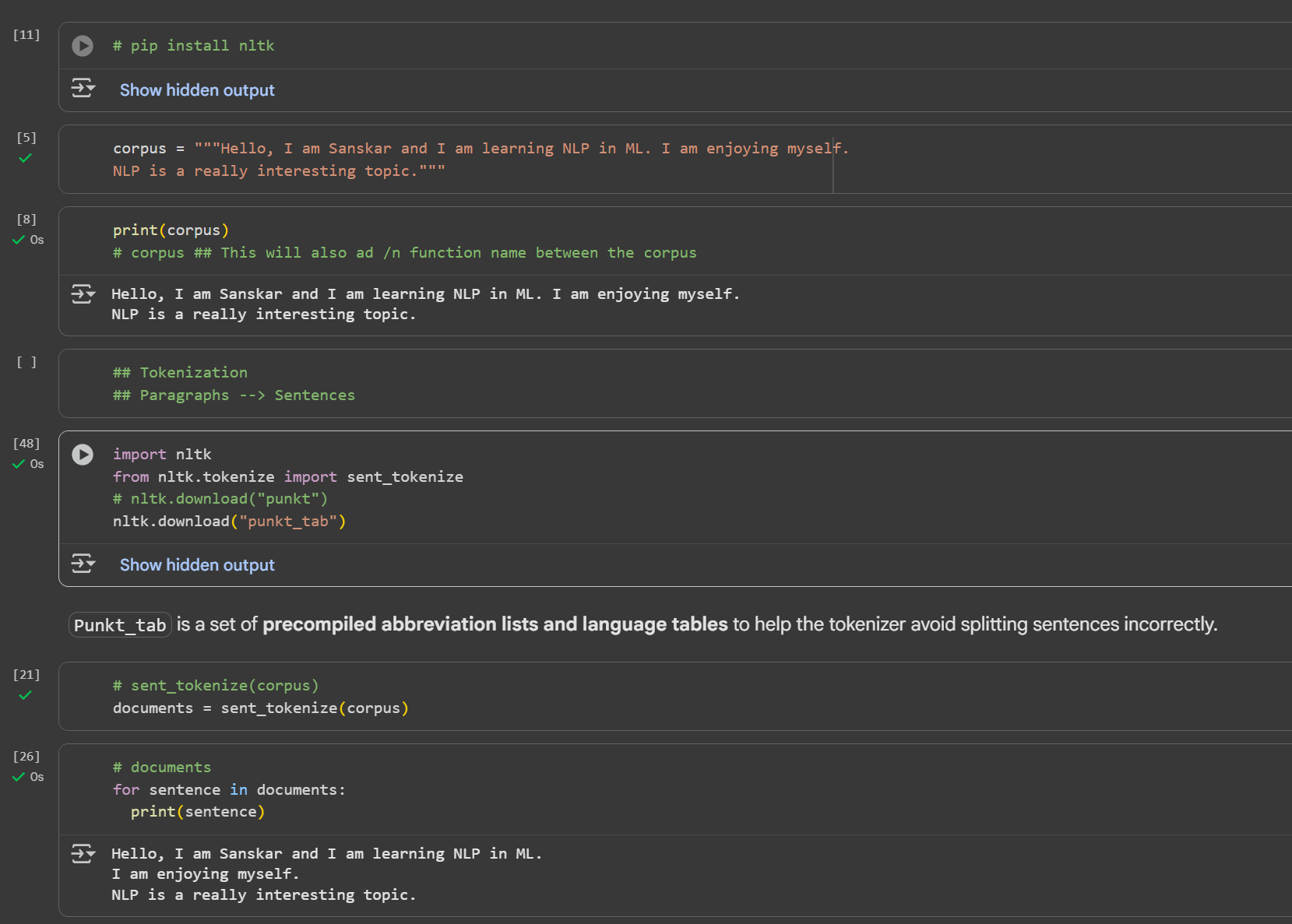

Sanskar
Keen Learner and Exp... • 6m
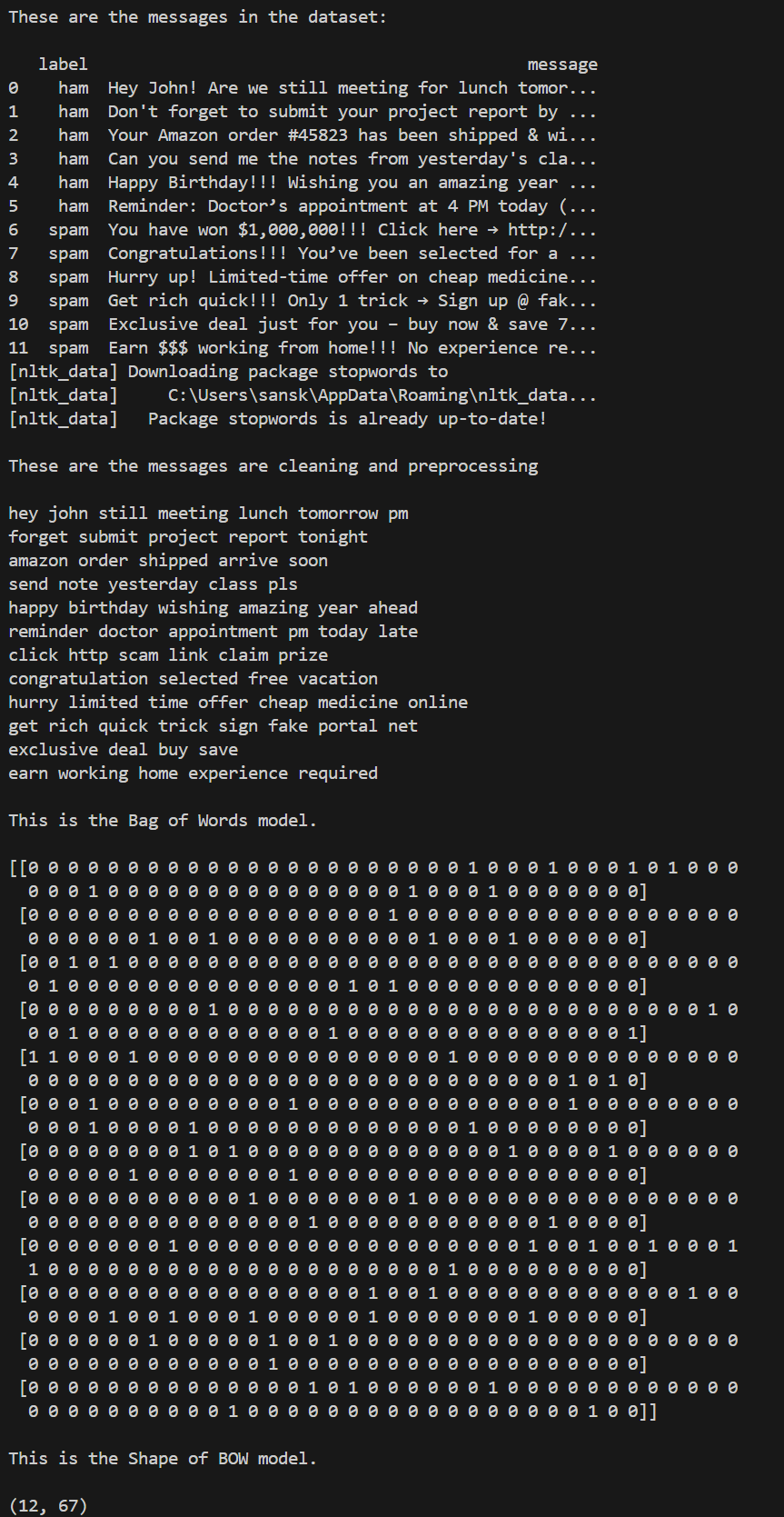
Day 9 of learning AI/ML as a beginner. Topic: Bag of Words practical. Yesterday I shared the theory about bag of words and now I am sharing about the practical I did I know there's still a lot to learn and I am not very much satisfied with the topi
See More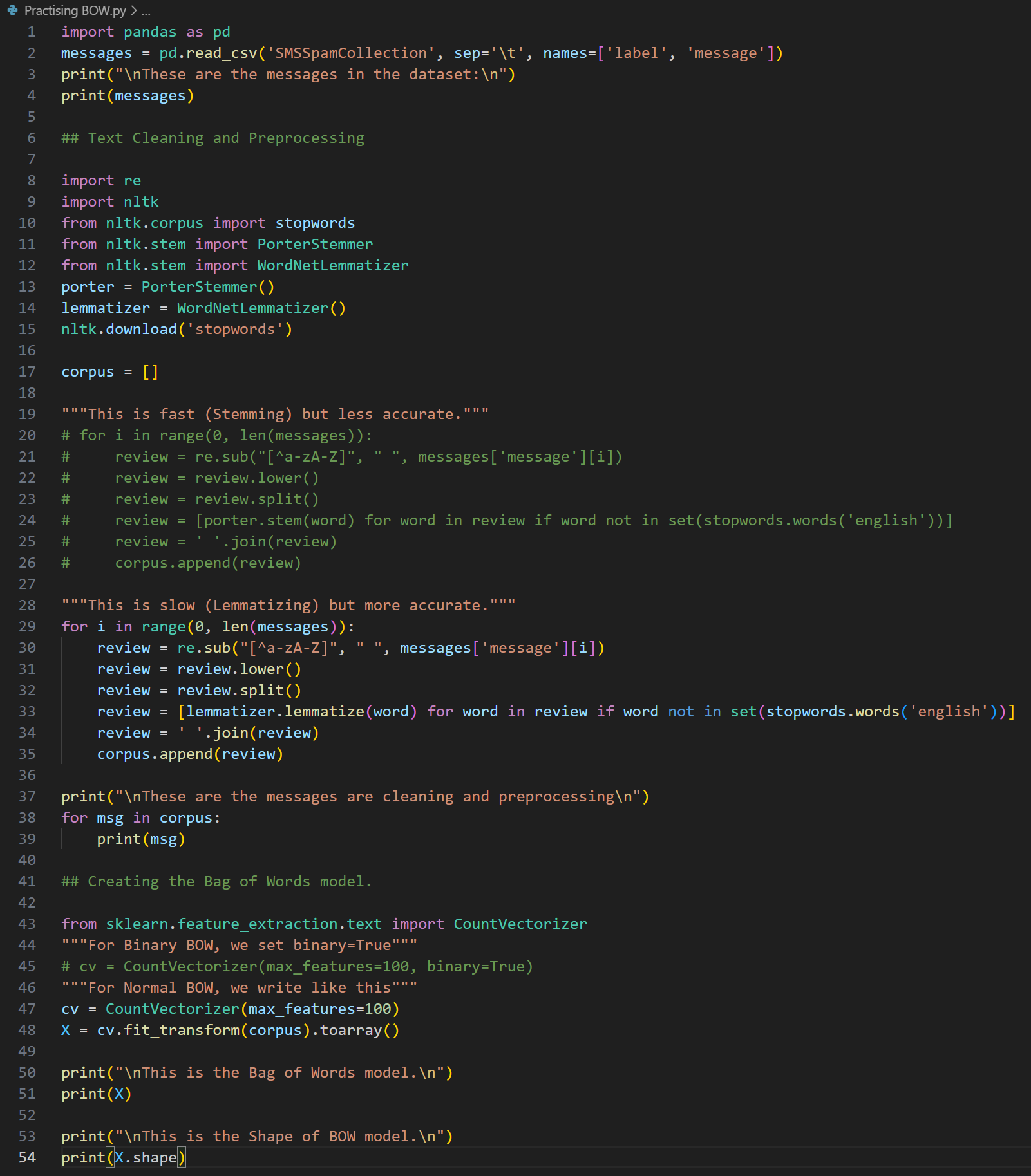








Anonymous
Hey I am on Medial • 1y
I had collage today as well. And in the last 10 mins, our eco teacher just called random students, gave them.a word, and they had to draw something on the board to let everyone guess the word. One person got the word 'Taxes', he just drew popcorn an
See More

T.K.ANJANAA SREE
Hey I am on Medial • 1y
Why should create a pdf viewer app integrated with AI So everytime we come across a new sentence or new word we come out and search for it.. so using AI selecting the text and double taking leads to result of meaning of the sentence Why shouldn't we
See More
gray man
I'm just a normal gu... • 10m
The Delhi High Court has overturned an arbitration tribunal's decision in the continuing legal battle stemming from the unsuccessful merger attempt between hotel giant OYO and competitor Zostel Hospitality. OYO stated that the High Court sided with
See More

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.