
Back
Anonymous 3
Hey I am on Medial • 2y
What data are you training or fine tuning your model on?
Replies (1)
More like this
Recommendations from Medial


Nikhil Raj Singh
Entrepreneur | Build... • 6m
Hiring AI/ML Engineer 🚀 Join us to shape the future of AI. Work hands-on with LLMs, transformers, and cutting-edge architectures. Drive breakthroughs in model training, fine-tuning, and deployment that directly influence product and research outcom
See More

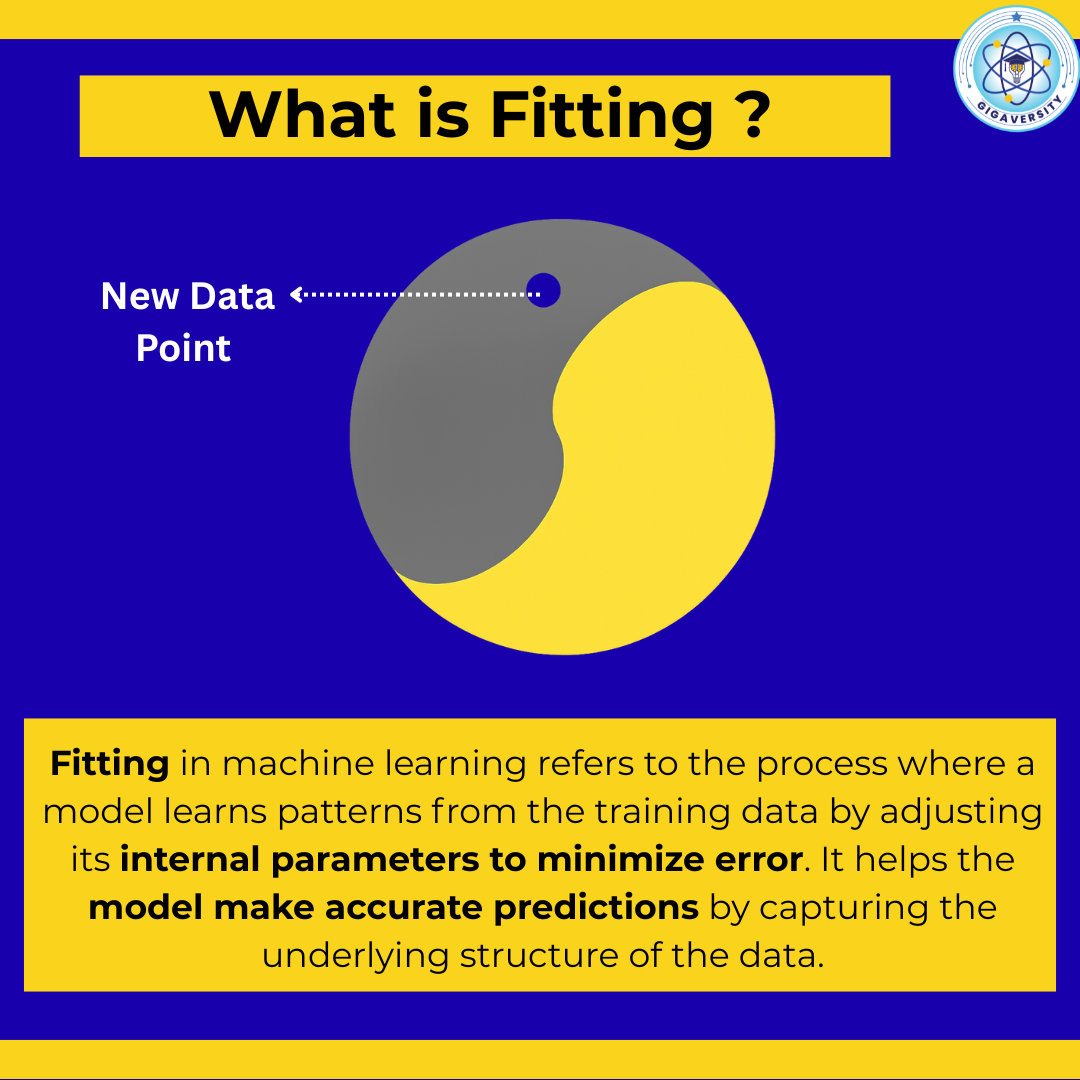
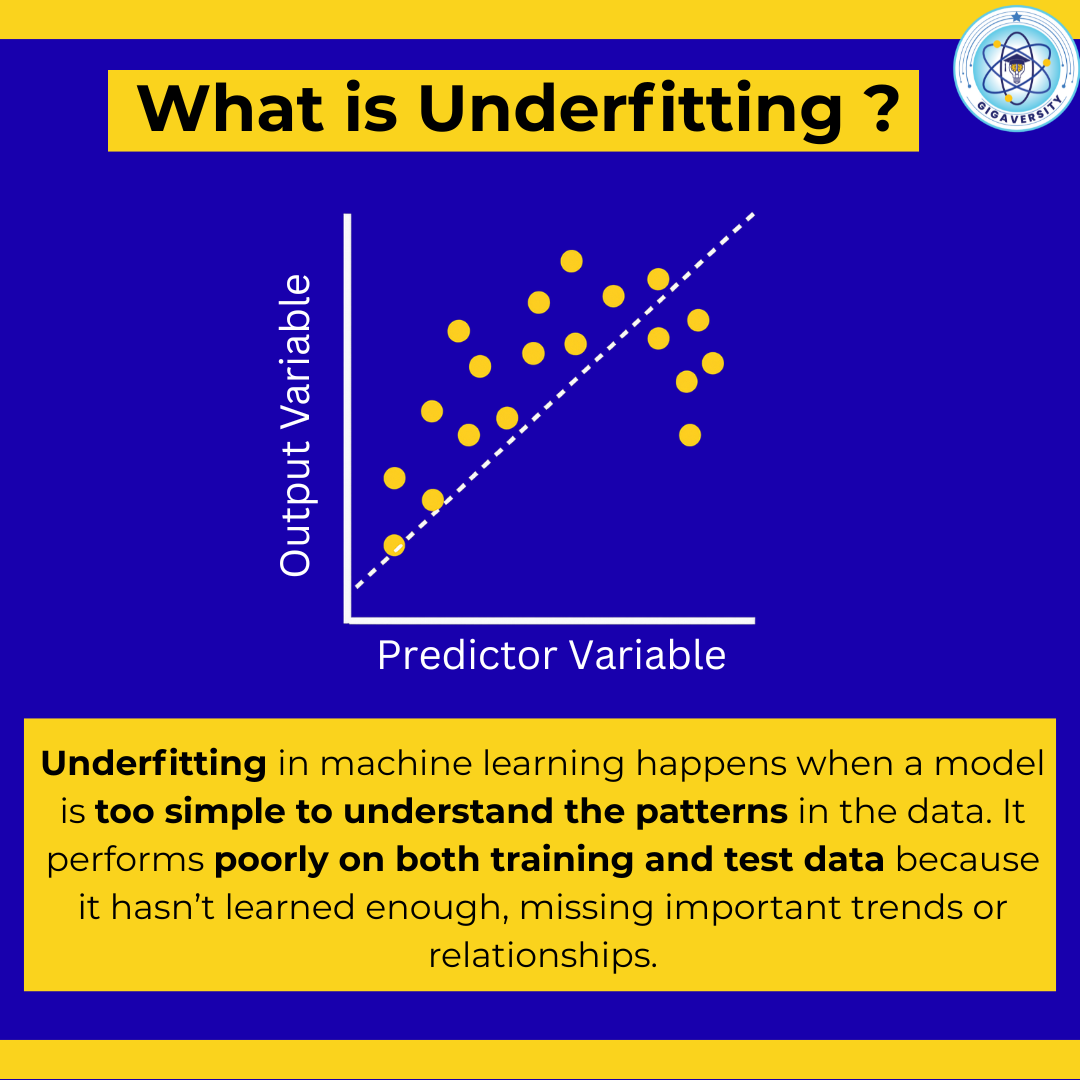
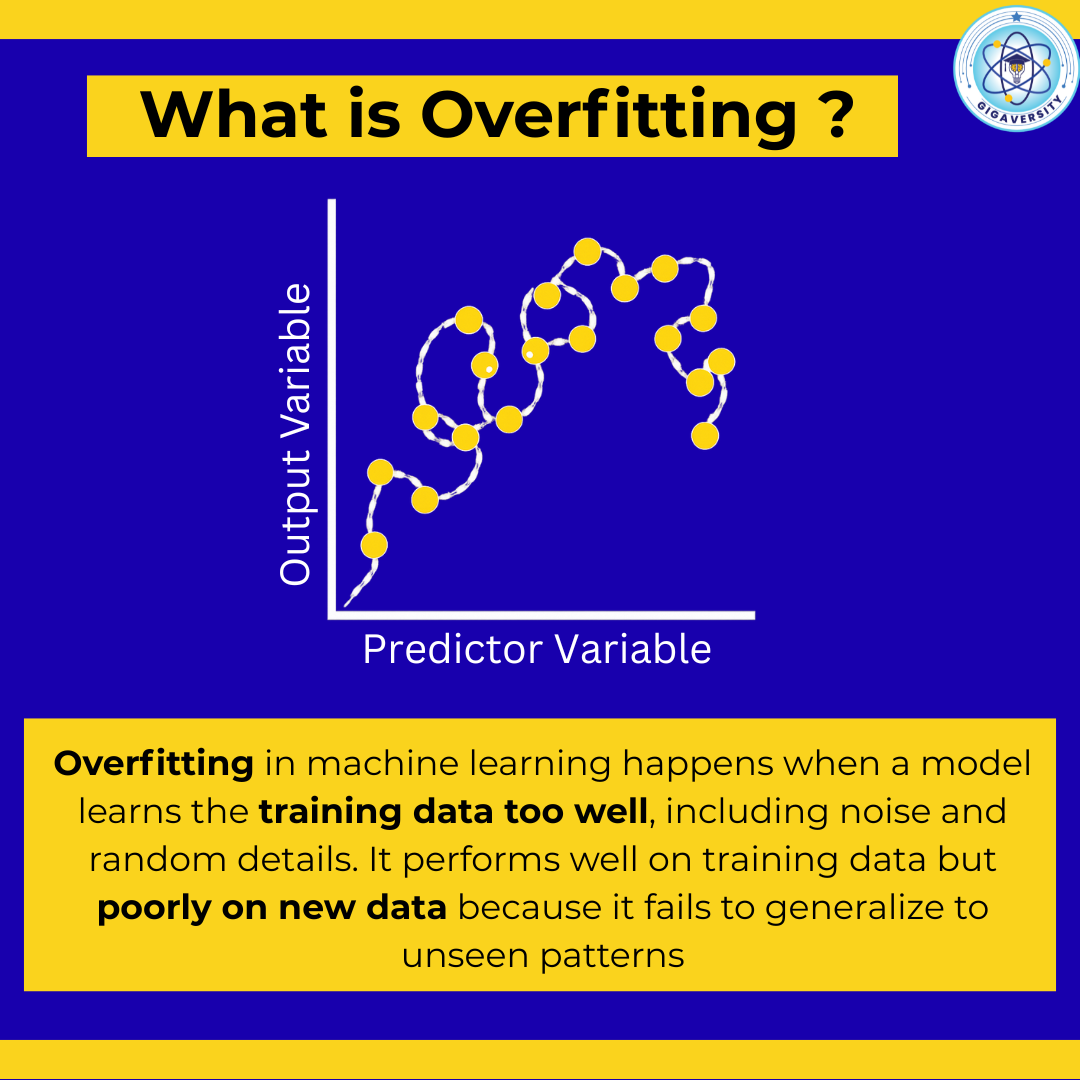






Aditya Karnam
Hey I am on Medial • 1y
"Just fine-tuned LLaMA 3.2 using Apple's MLX framework and it was a breeze! The speed and simplicity were unmatched. Here's the LoRA command I used to kick off training: ``` python lora.py \ --train \ --model 'mistralai/Mistral-7B-Instruct-v0.2' \ -
See More

Narendra
Willing to contribut... • 4m
I fine-tuned 3 models this week to understand why people fail. Used LLaMA-2-7B, Mistral-7B, and Phi-2. Different datasets. Different methods (full tuning vs LoRA vs QLoRA). Here's what I learned that nobody talks about: 1. Data quality > Data quan
See More

Bhoop Singh Gurjar
AI Deep Explorer | f... • 12m
"A Survey on Post-Training of Large Language Models" This paper systematically categorizes post-training into five major paradigms: 1. Fine-Tuning 2. Alignment 3. Reasoning Enhancement 4. Efficiency Optimization 5. Integration & Adaptation 1️⃣ Fin
See More






lakshya sharan
Do not try, just do ... • 1y
Random Thought : I was wondering, why ChatGPT weren't build on the Increment Learning modle.. Because I might destroy it's algo.... Let me expain.. In the world of machine learning, training models can be approached in two main ways, Batch Lea
See More

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.