
Back

Rahul Agarwal
Founder | Agentic AI... • 20d
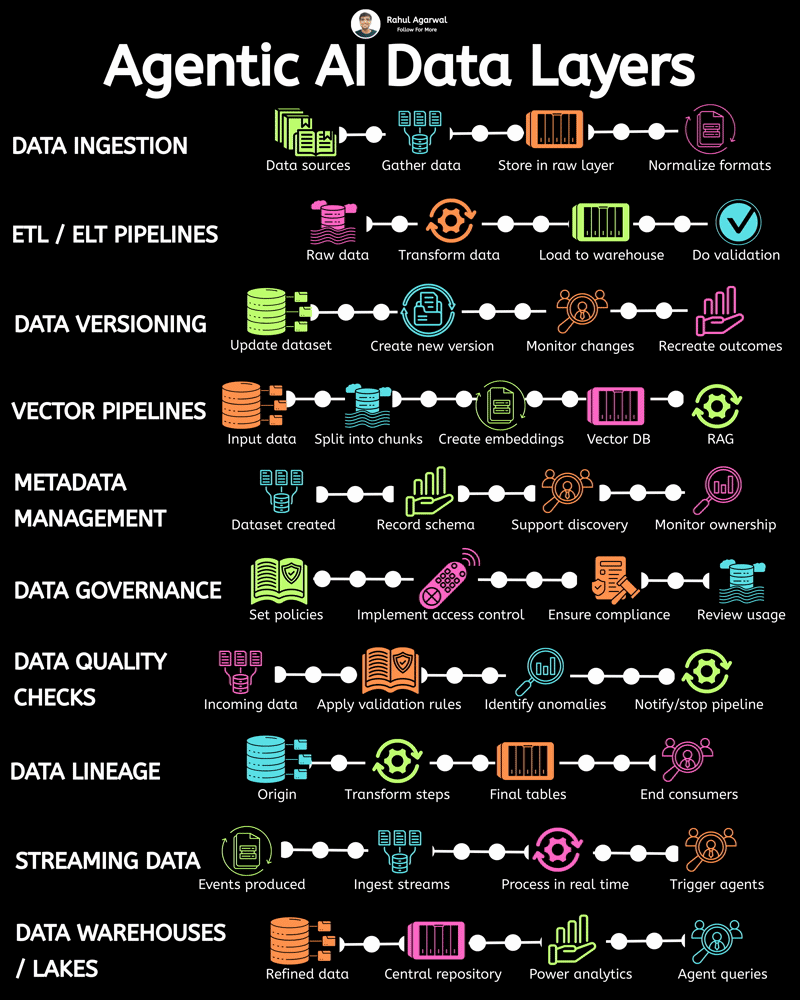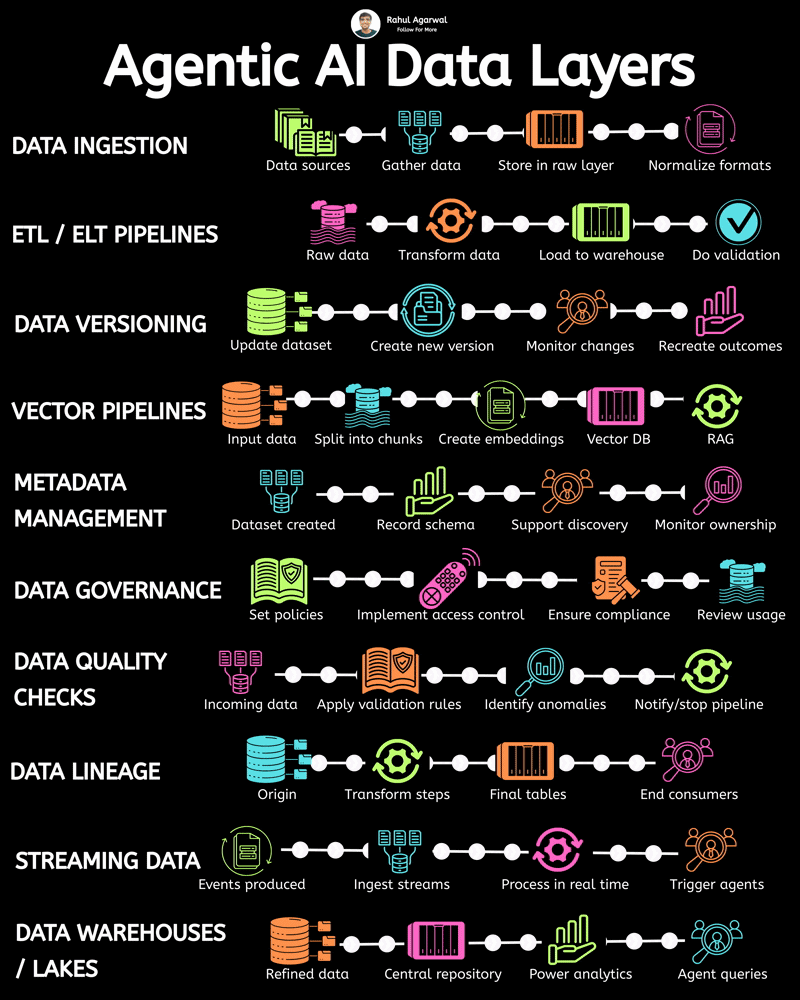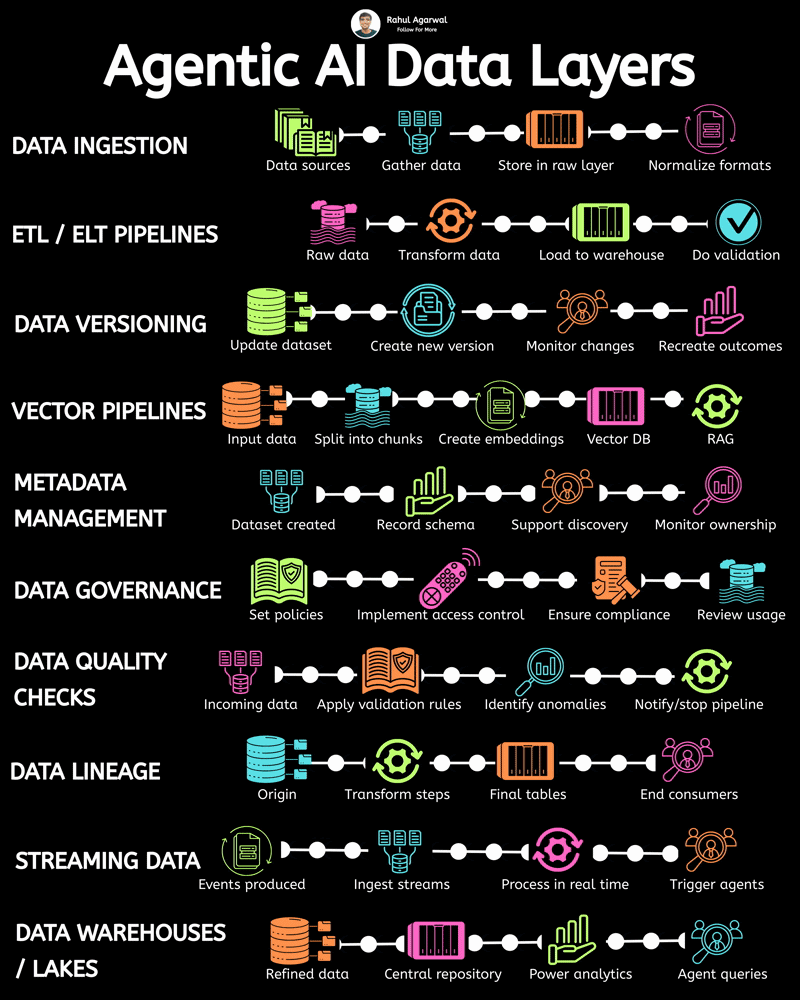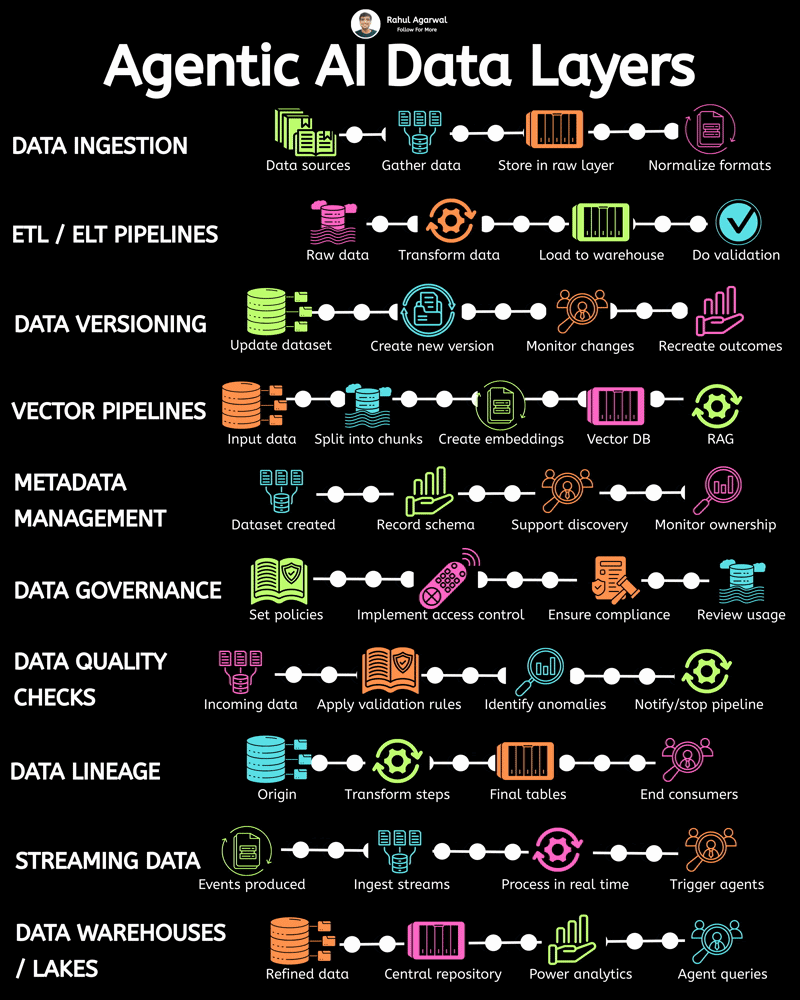
Most AI projects don’t fail because of models. They fail because data never flows properly. Without reliable data movement, even the smartest AI system becomes useless infrastructure. Everything begins with pipelines. They quietly power modern analytics, machine learning, and AI-driven decision systems. They gather information. They clean it. They move it. They prepare it for real use. But designing one well is harder than it looks. Several layers must work together smoothly for the system to actually deliver value. It starts with sources. Raw information arrives from applications, databases, APIs, sensors, and external services. Then ingestion begins. Loaders collect and transport trusted datasets into the central data environment. Next comes raw storage. A data lake keeps unprocessed information accessible for later transformation and analysis. Processing follows. Computation layers clean, structure, and convert messy inputs into usable formats. Then comes organization. Data warehouses store structured outputs optimized for analytics and reporting. Finally, distribution happens. Prepared datasets become available to analysts, dashboards, and AI models. Each stage matters. Break one step and everything downstream suffers. Strong pipelines turn scattered information into reliable intelligence businesses can actually act on. That’s what makes modern AI possible.
More like this
Recommendations from Medial

Sheikh Ayan
Founder of VistaSec:... • 7m
📊 Top 5 Open-Source Tools Powering Big Data Innovation Big Data is transforming decision-making, and open-source tools are leading the charge. Here are the must-know platforms: 1️⃣ Apache Hadoop 🗂️ – The backbone for distributed storage & process
See More
Sudarshan Pal
Data Engineer @Quant... • 1y
Many argue that Data Engineering is a part of data science and analytics. It's different from data science, but they work together closely. Data Engineers come first in the process. They gather and organize data. This data is then used by Data Scien
See More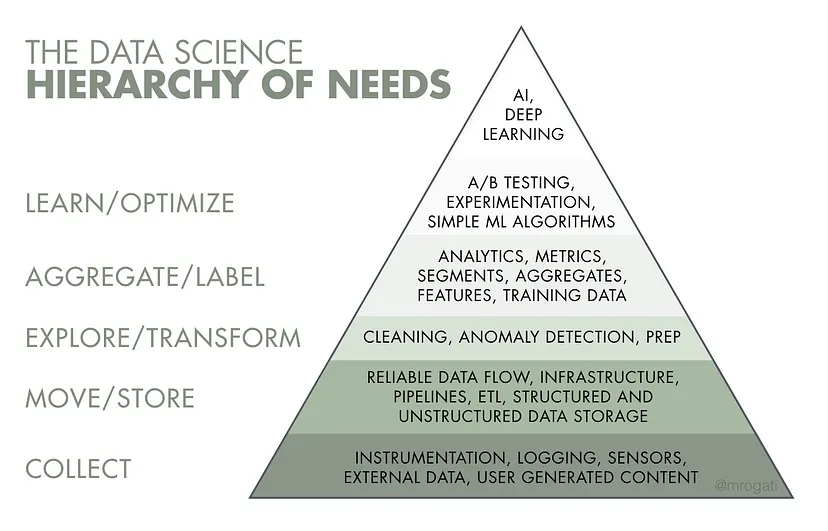





Pulakit Bararia
Founder Snippetz Lab... • 1y
How AI Works 1. Neural Networks – AI’s Brain AI’s neural networks consist of three layers: Input Layer: Takes in raw data (e.g., an image). Hidden Layers: Process data to find patterns (e.g., detecting edges, shapes). Output Layer: Produces the fi
See More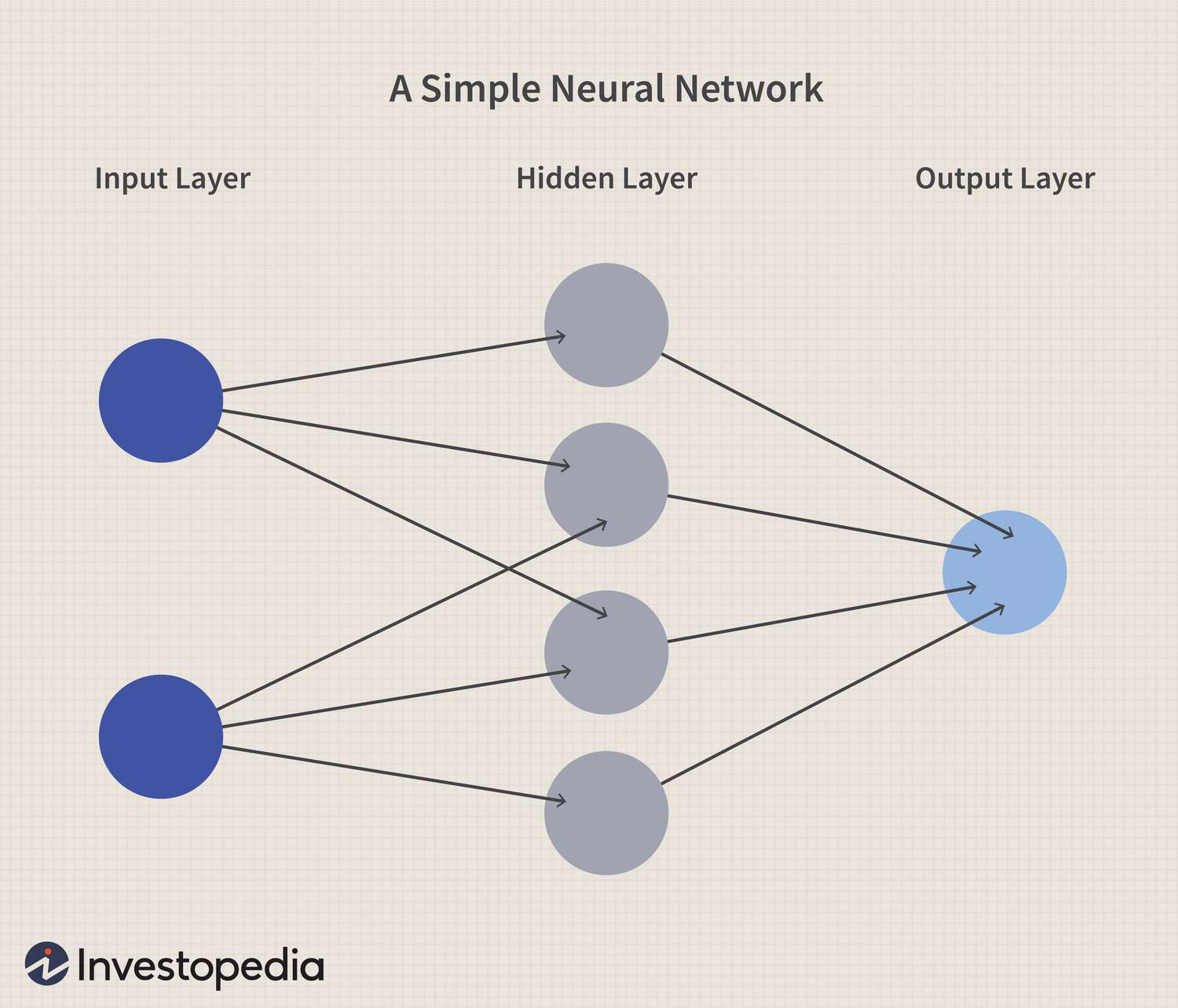


Aroneo
| Technologist | ML ... • 1y
Machine Learning vs. Deep Learning: What’s the Real Difference? 🤖⚡ Machine Learning (ML) and Deep Learning (DL) are both AI-driven, but they’re not the same! While ML relies on algorithms to learn from data, DL uses artificial neural networks to pr
See More
/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)

























Download the medial app to read full posts, comements and news.