
Back

Sanskar
Keen Learner and Exp... • 6m
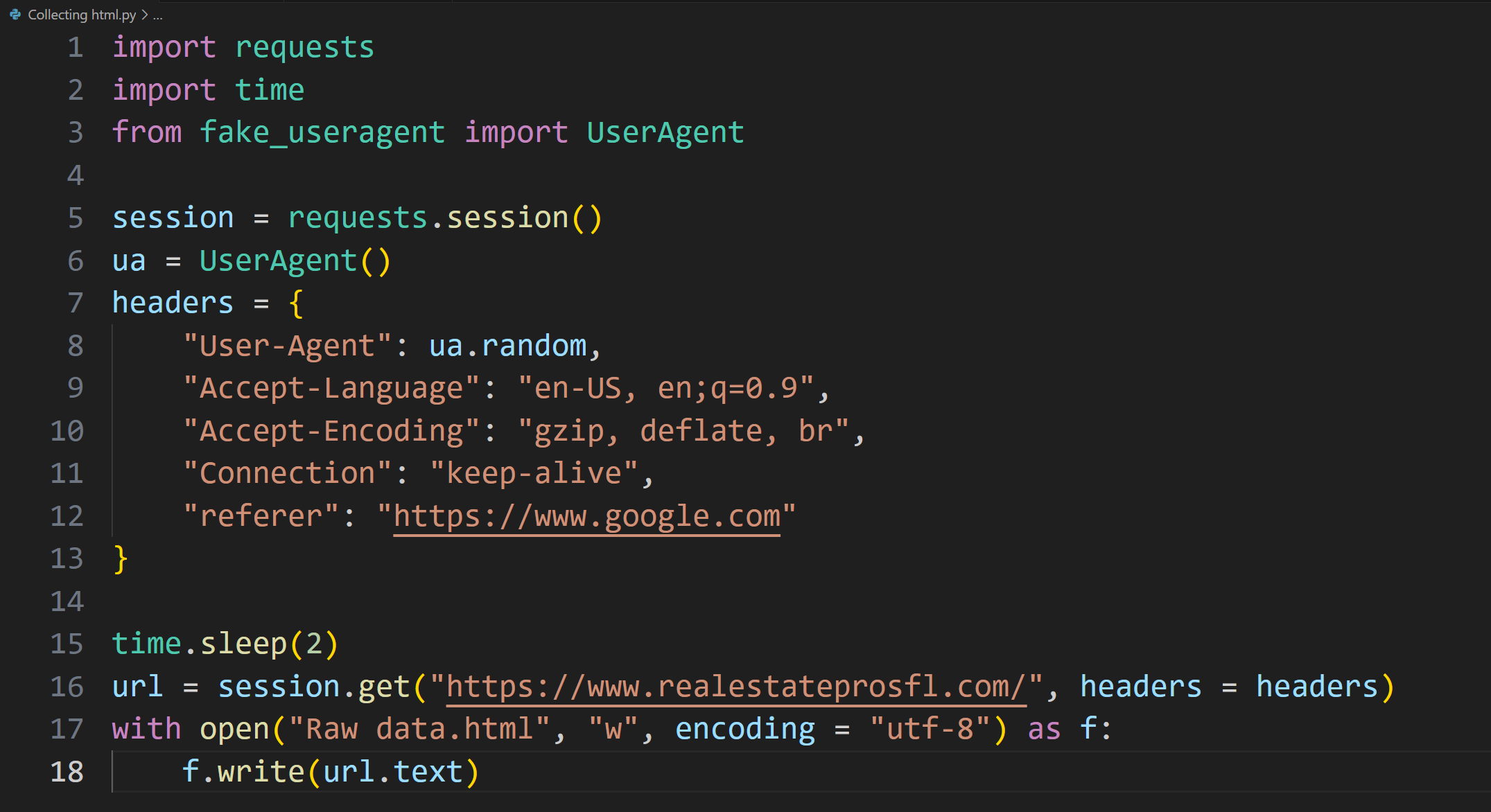
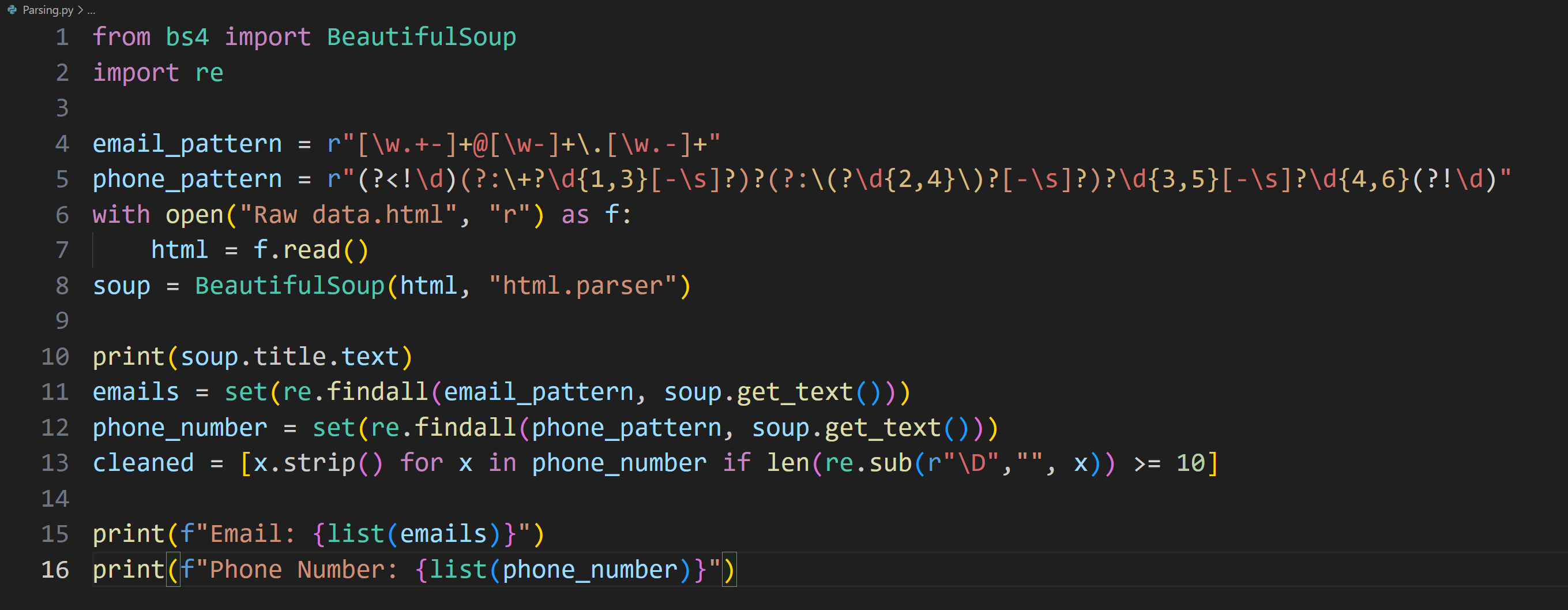
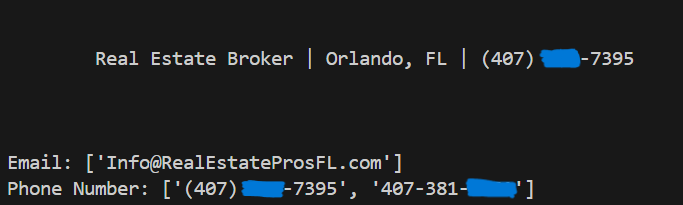
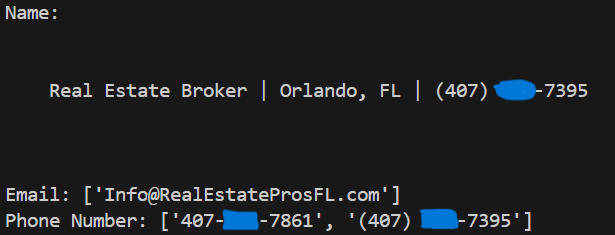
Day 27 of learning python as a beginner. Topic: web scraping using beautiful soup. A few days ago I got introduced to requests library in python which can scan the html from websites. At that time I was confused on what might be the real life implications of it that's when many amazing people guided me that most of its implications are in web scraping (something which I wasn't aware about then). Web scraping is essentially extracting data from websites (in html format) and then parsing it to extract useful information. There are mainly two libraries used for web scraping 1. Beautiful Soup and 2. Selenium some say Scrapy is also good for this purpose. I have focused on beautiful soap and was successful in scraping data of a real estate website. First I used requests and File I/O to save the html data (many people say that there's no need for it however I think that one should save the data first in order to avoid unexpected errors from website or to avoid repeat scraping when you want to extract more information from the same data). At first the website was forbidding me for scraping html data therefore I gave a time delay of 2 second because sending too many requests to the server is a common signal that I am scraping data. Then I used fake user agent to create a realistic user agent and manipulated browser header so that the request seem more legitimate. Once I got all the HTML data saved in a file I used Beautiful Soup to parse the data (Beautiful soup converts raw html into structured parse tree). I identified my goal as extracting the email and phone number (which I hid obviously) from the website and for this purpose I used regular expressions (regrex [I finally got some understanding of this]) because it helps me create patterns which can be used to identify the text which I require (email and phone number) although I created the pattern of email myself however took AI's help to design the pattern of phone number (it was a bit challenging for me). I have performed all this on a single website and in future I have plans to do this in bulk (I may require proxies for those to avoid IP ban) and then I can enter all that data in the database using PostgreSQL. I also have to learn Selenium because I believe it may also have its own implications (correct me if I am wrong). And here's my code and it's result.
More like this
Recommendations from Medial



Tuhin Subhra Biswas
Building in 🥷🏻• Pr... • 1y
As there are irregularities in the NEET 2024 exam results, in order to investigate this, Harkirat Bhaiya shared his 1Hour long session of scraping data from NEET RESULT website and building a web where users can enter their roll number, application n
See More






Nandha Reddy
Cyber Security | Blo... • 9m
💡 Ever Wondered Why Apps Like Rapido Might Incur Costs for Your Searches? Every time you open an app like Rapido and input your pickup and destination locations, the app communicates with external services to fetch route details, estimated times, a
See More


/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.