
Back
Anonymous 2
Hey I am on Medial • 1y
Claude 3.5 Sonnet crushing it with 93.7% in code? Looks like we have a new coding MVP in the AI game! 🏆 But what's up with those reasoning skills? Just 65%—you'd think AI would ace that too
Replies (1)
More like this
Recommendations from Medial


Aakash kashyap
Building JalSeva and... • 1y
AI Model Performance Benchmarks: 🚀 Comparing Claude, GPT-4o, and Gemini Across Key Tasks with Claude 3.5 Sonnet performing best overall, especially in code (93.7%) and reasoning (65.0%). Gemini 1.5 Pro excels in math (86.5% with 4-shot CoT). GPT-
See More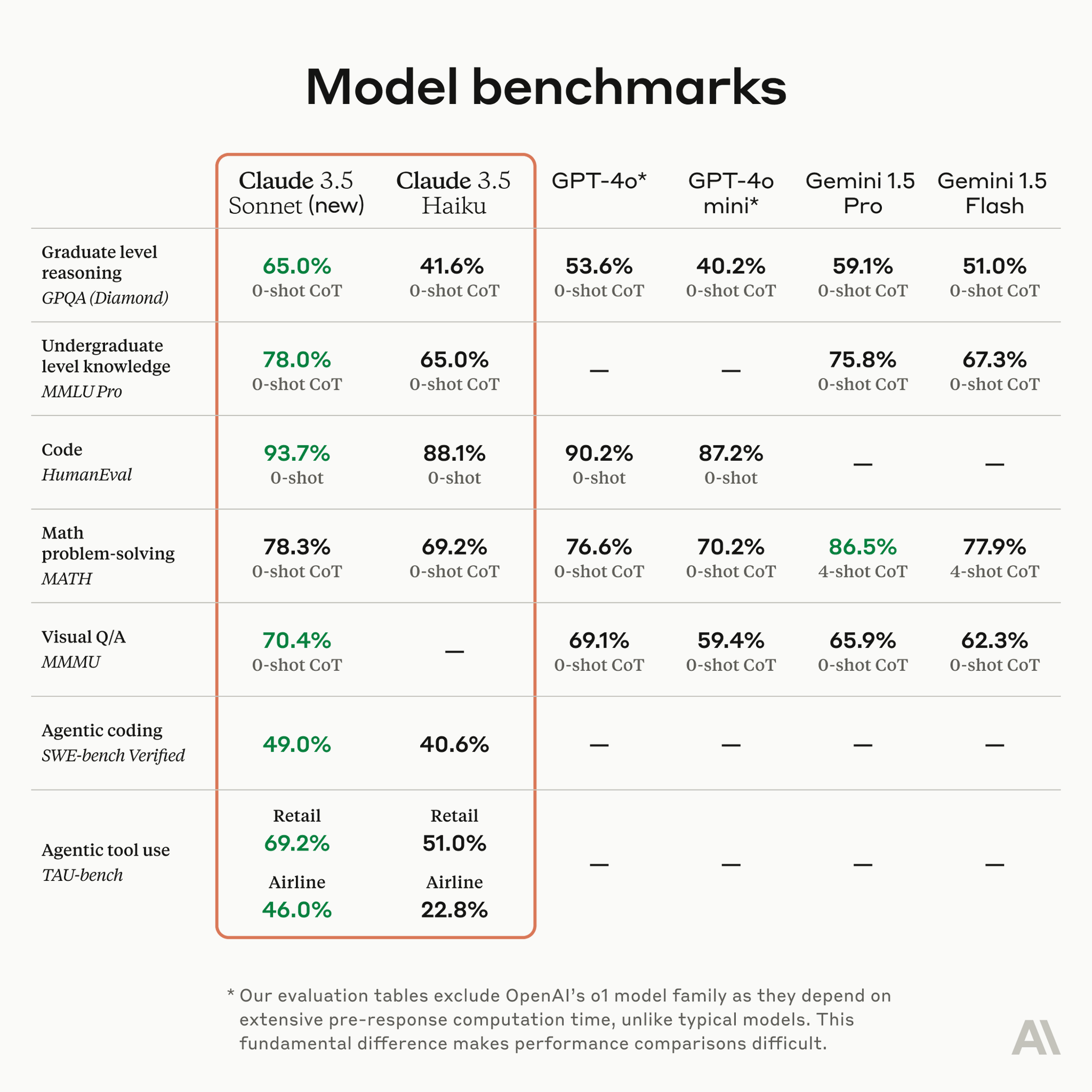












Nishant Viroja
Making AI tools easy... • 6m
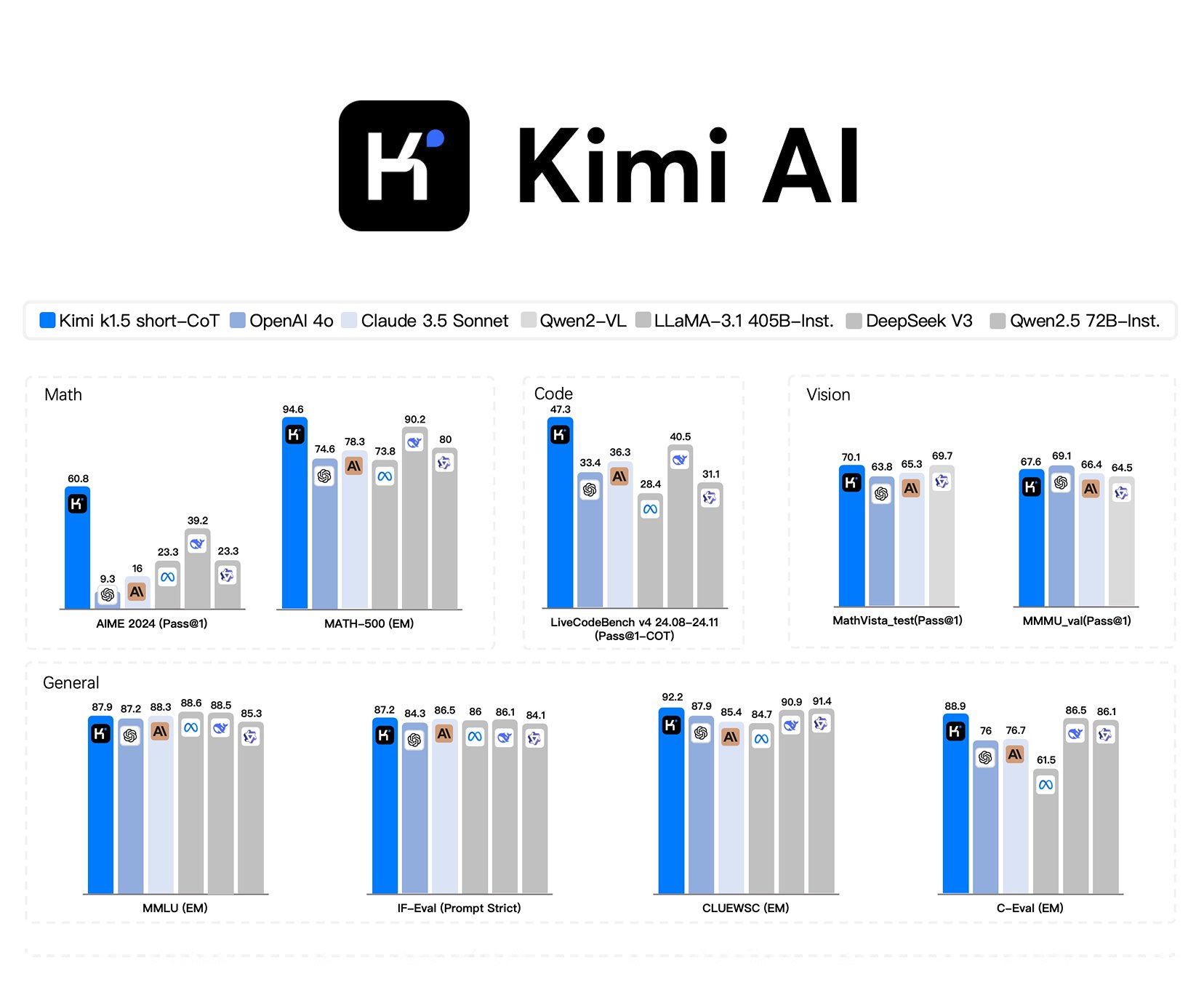
🚀 Anthropic just dropped its most advanced AI model yet - Claude Sonnet 4.5 This powerhouse can code for 30+ hours straight, build entire apps, and run complex agent workflows with enterprise-level safety and reliability. From stronger security to
See More

Mada Dhivakar
Let’s connect and bu... • 9m
Why Grok AI Outperformed ChatGPT & Gemini — Without Spending Billions In 2025, leading AI companies invested heavily in R&D: ChatGPT: $75B Gemini: $80B Meta: $65B Grok AI, developed by Elon Musk's xAI, raised just $10B yet topped global benchmar
See More



/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)























Download the medial app to read full posts, comements and news.