
Back

Swamy Gadila
Founder of Friday AI • 5m
Big News: Friday AI – Adaptive API is Coming! We’re launching Adaptive API, the world’s first real-time context scaling framework for LLMs. Today, AI wastes massive tokens on static context — chat, code, or docs all use the same window. The result? Higher GPU bills, latency, and poor enterprise scalability. Our Solution: Adaptive API dynamically reshapes requests (12K→1M tokens) in <200ms, analyzing activity and semantic density to save compute and cost. Think of it as an optimizer layer between your app and model. Unlike LangChain or Mem0, it’s composable, selective, and brain-inspired. Works with OpenAI, Anthropic, Grok, and any LLM. Benefits: Developers save 30–40% tokens. Enterprises lower infra costs, monitor usage, and deploy securely. Pricing starts at $0.018/1K tokens. Join our beta launch → fridayai.fun
Replies (2)

More like this
Recommendations from Medial



Account Deleted
Hey I am on Medial • 7m
Dhruv rathee's AI Fiesta claims you “save 90%” on API costs. Here’s the reality 👇 400k tokens ≈ $1.30 worth of API usage. AI Fiesta charges $3.99 for it. That’s a 237% markup. And the “unlimited” plan? Not really. 400k tokens = ~10 days of actua
See More

Swamy Gadila
Founder of Friday AI • 3m
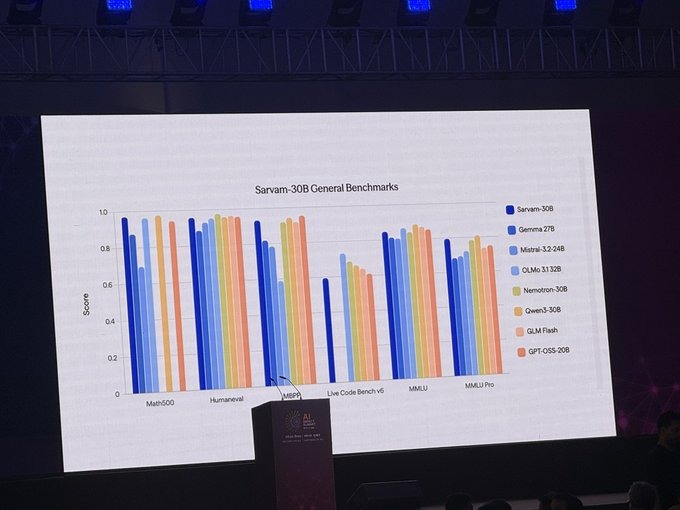
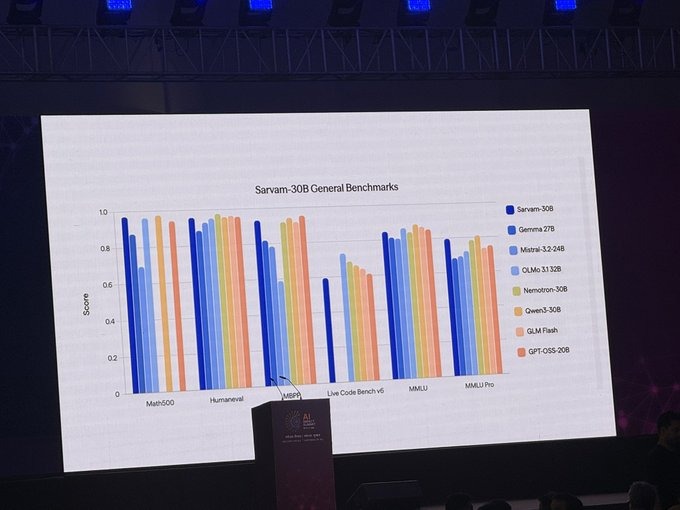
Adaptive Plugin: The next efficiency layer for Enterprise GenAI LLM workloads are exploding across finance, healthcare, SaaS, telecom, and government. The hidden drain is token waste from oversized prompts, long documents, and heavy chat histories.
See More


Vansh Khandelwal
Full Stack Web Devel... • 25d
Composable commerce lets retailers assemble best-of-breed modules rather than use monolithic platforms. The MACH stack—Microservices, API-first, Cloud-native and Headless—enables this: microservices allow independent, resilient deployable functions;
See More

Account Deleted
Hey I am on Medial • 10m
Somebody just scanned 2000 Vibecoded websites... and here's what he found : - 49.5% had security issues - Found 1120 JWT tokens exposed - 70 Google API keys floating around And yes, env vars in production 🤦♂️ Security ain't a vibe if you're lea
See More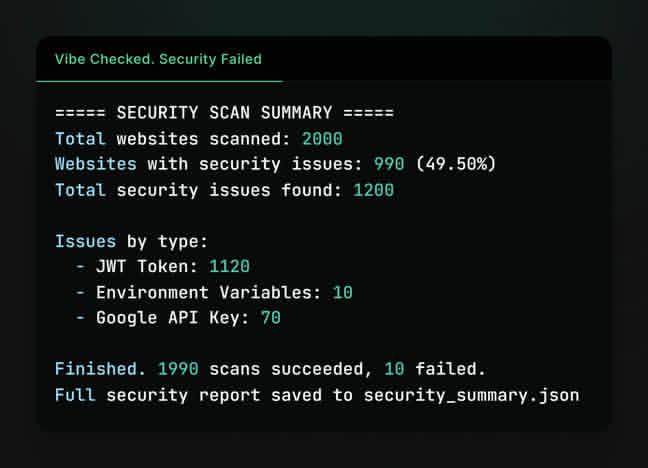
Anonymous
Hey I am on Medial • 1y
hii, i have created an ai android app where i use gemini api to fetch ai response i use gemini 1.5 flash. It provide rate limit of 15 RPM and 1M TPM (tokens per minute) which is obviously less in production. So, i have an idea that i will generate 20
See More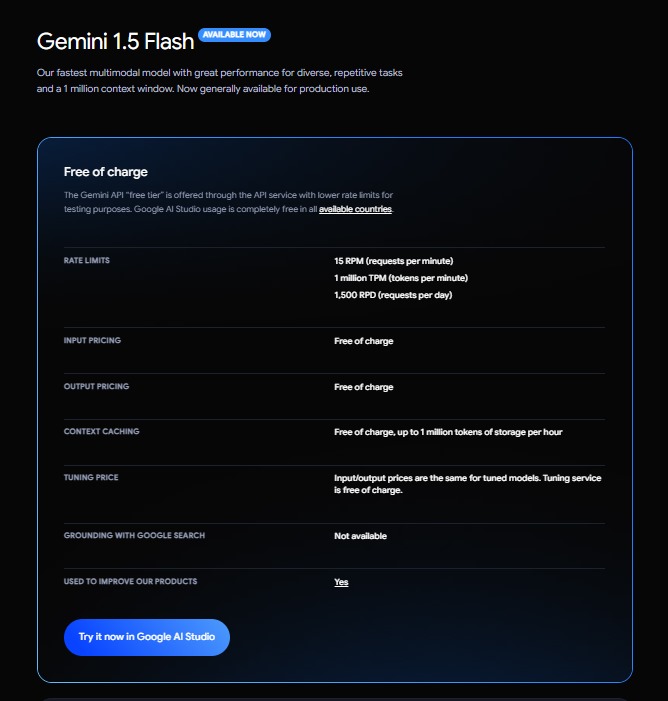

Tirush V
Infrastructure/AI en... • 8m
Hey everyone, First Indian product on Vision RAG, Currently RAG systems often struggle to maintain context, leading to hallucinations and inaccurate response. At https://blackwhole.dev we solving this so you can upload any document and get highly re
See More

Aparna Pradhan
fullstack dev specia... • 5m
🚀 How to Save 90% on Your AI Costs Here’s exactly how we cut AI costs from $500/month to $5/month: 1. Avoid LLMs When Possible Use rules, regex, or database lookups for simple tasks (60–80% of workflows). Example: A lead qualification bot using rege
See More

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.