
Back

Greg
👤 • 8m
i don't think there's any tool readily available for this. However i found this on gemini: See if it helps: You'll need a solution that can programmatically access your local files, extract text despite the unstructured nature (even without perfect OCR if the documents are already OCR'd but the data isn't fixed), and then process that text. Python with libraries like fitz (PyMuPDF) or pdfplumber for text extraction, and then natural language processing (NLP) libraries such as spaCy or NLTK for identifying relevant data, would be your best bet. Here's a conceptual outline: Iterate through files: Use Python's os module to list all PDFs in your specified directory. Extract text: For each PDF, use fitz or pdfplumber to extract the text content. Since you mention they are OCR'd PDFs, these libraries should be able to get the text. Information Extraction (NLP): Apply NLP techniques to identify key entities and clauses relevant to your "summary" and "relevant data." This is the most complex part, as it requires defining what "relevant data" means for your legal agreements (e.g., parties, dates, key clauses, terms). Summarization and Tabular Output: Develop logic to condense the extracted information into a summary for each document and then compile the "relevant data" into a pandas DataFrame, which can then be exported to a tabular format like CSV or Excel.
Replies (1)

More like this
Recommendations from Medial


SHIV DIXIT
CHAIRMAN - BITEX IND... • 1y
★ Cellebrite startup was established in Israel in 1999 by Avi Yablonka . With this device you can access any mobile phone in the world even our goverment agencies like ED , CBI , RAW is using this device to extract data from criminals phones even s
See More

Navneet Chaudhary
•
Ozone Pharma • 8m
I've 100s of legal agreements (ocr pdf) in my laptop. I want to extract the relavant data out of it. But uploading one by one is too slow. How can I make a summary by analysing each documents and give the summary of all the pdfs with relavant data in
See More



Yashraj Thakor
AI Automation Specia... • 9m
Google Maps Lead Scraper Workflow – No-Code + No Paid APIs Tired of manually scraping Google Maps for business leads? This plug-and-play automation lets you: 🔍 Search local businesses by keyword (e.g., “Plumber in Mumbai”) 🌐 Extract business web
See More


Vansh Khandelwal
Full Stack Web Devel... • 3m
The blackboard architecture is an AI design pattern where a central shared repository—the blackboard—lets specialized knowledge sources (KS) read, write and iteratively collaborate under a control component that schedules which KS run; an optional UI
See More
Sanskar
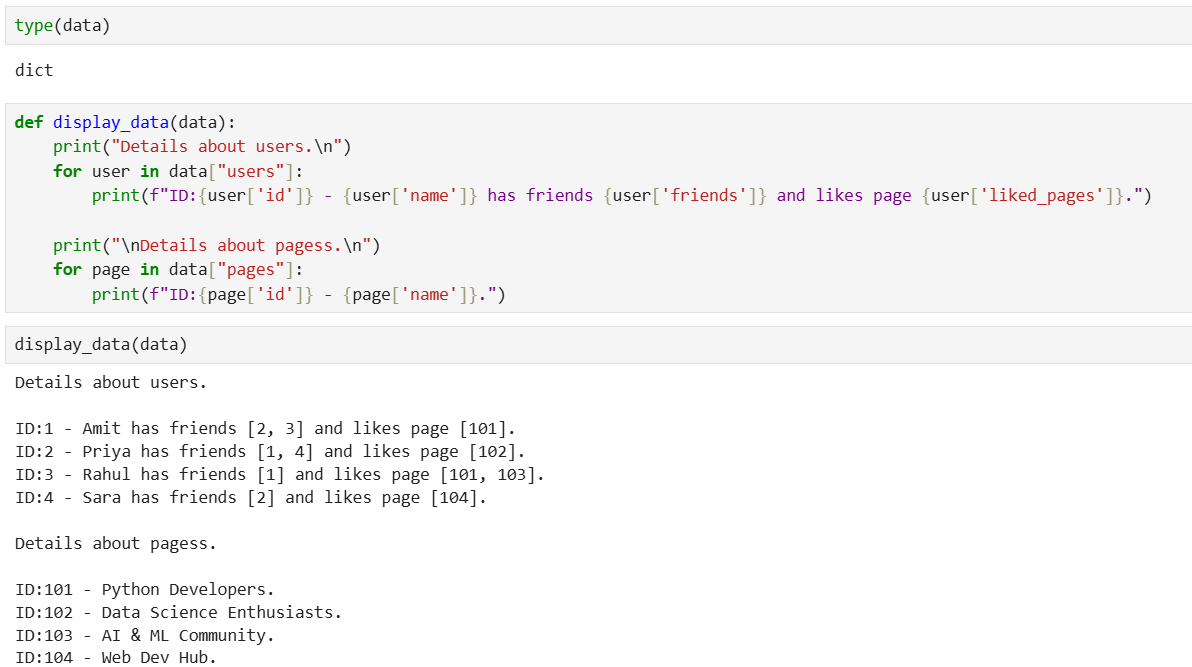
Keen Learner and Exp... • 5m
Day 1 of learning Data Science as a beginner. Topic: data science life cycle and reading a json file data dump. What is data science life cycle? The data science lifecycle is the structured process of extracting useful actionable insights from raw
See More


Sanskar
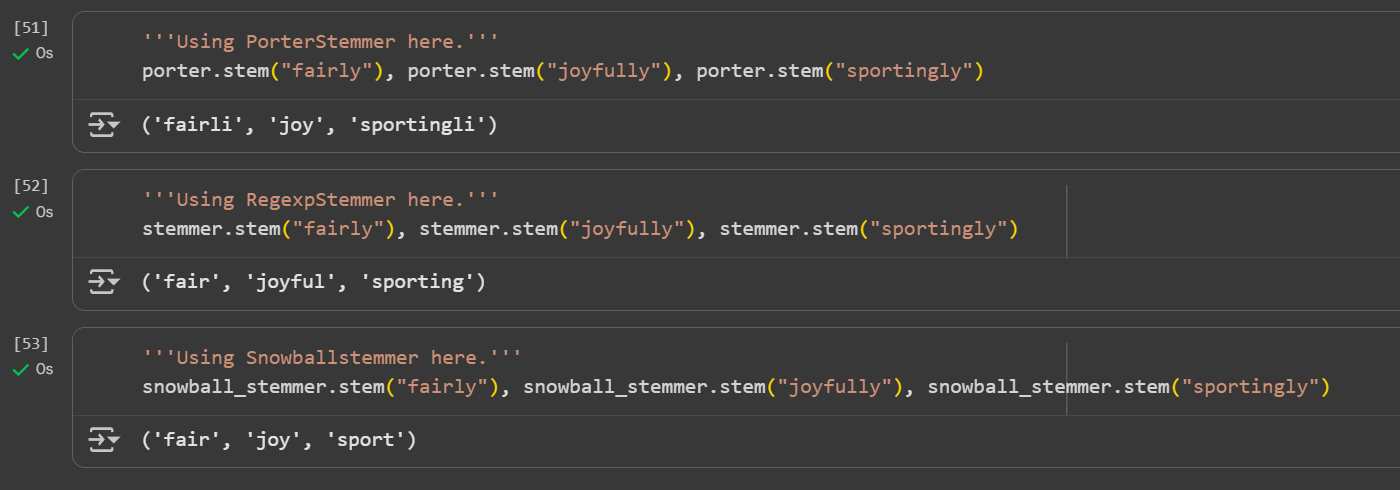
Keen Learner and Exp... • 6m
Day 4 of learning AI/ML as a beginner. Topic: text preprocessing stemming using NLTK. I have learned about tokenization and now I am learning about text preprocessing in ML. Text preprocessing is cleaning up of raw text (raw text is the one entered
See More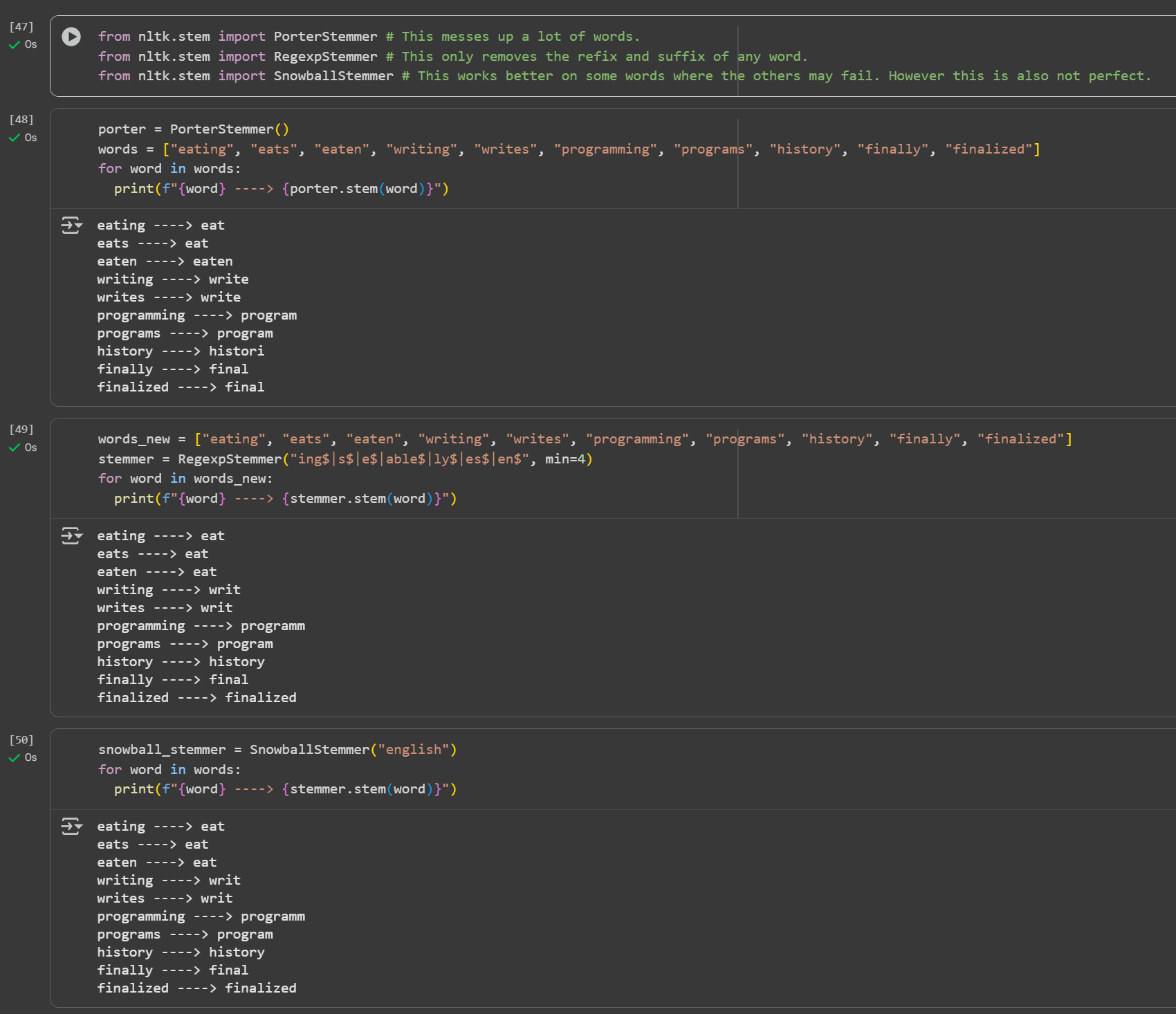

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.