
Back


asad Ullah
Ambitious • 9m
firstly thanks for giving your valuable time , the includes an amplitude test which focuses on problem-solving, logical reasoning, and critical thinking rather than advanced math. Emphasis is on basic math like percentages, ratios, and algebra. Also, prepare for reading comprehension, data analysis, and puzzles and also the hard part is interview
More like this
Recommendations from Medial

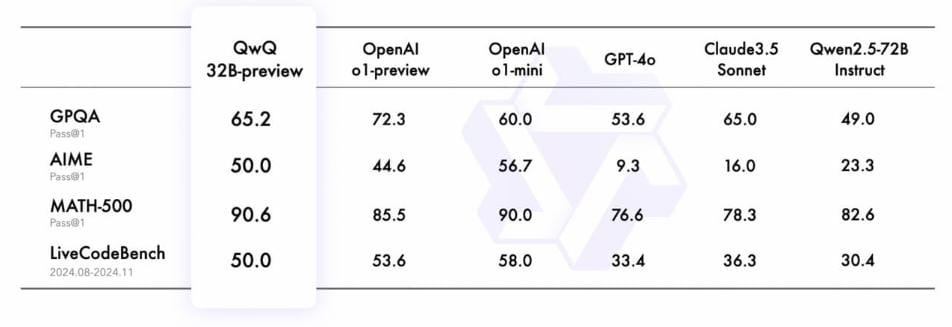




Aakash kashyap
Building JalSeva and... • 1y
AI Model Performance Benchmarks: 🚀 Comparing Claude, GPT-4o, and Gemini Across Key Tasks with Claude 3.5 Sonnet performing best overall, especially in code (93.7%) and reasoning (65.0%). Gemini 1.5 Pro excels in math (86.5% with 4-shot CoT). GPT-
See More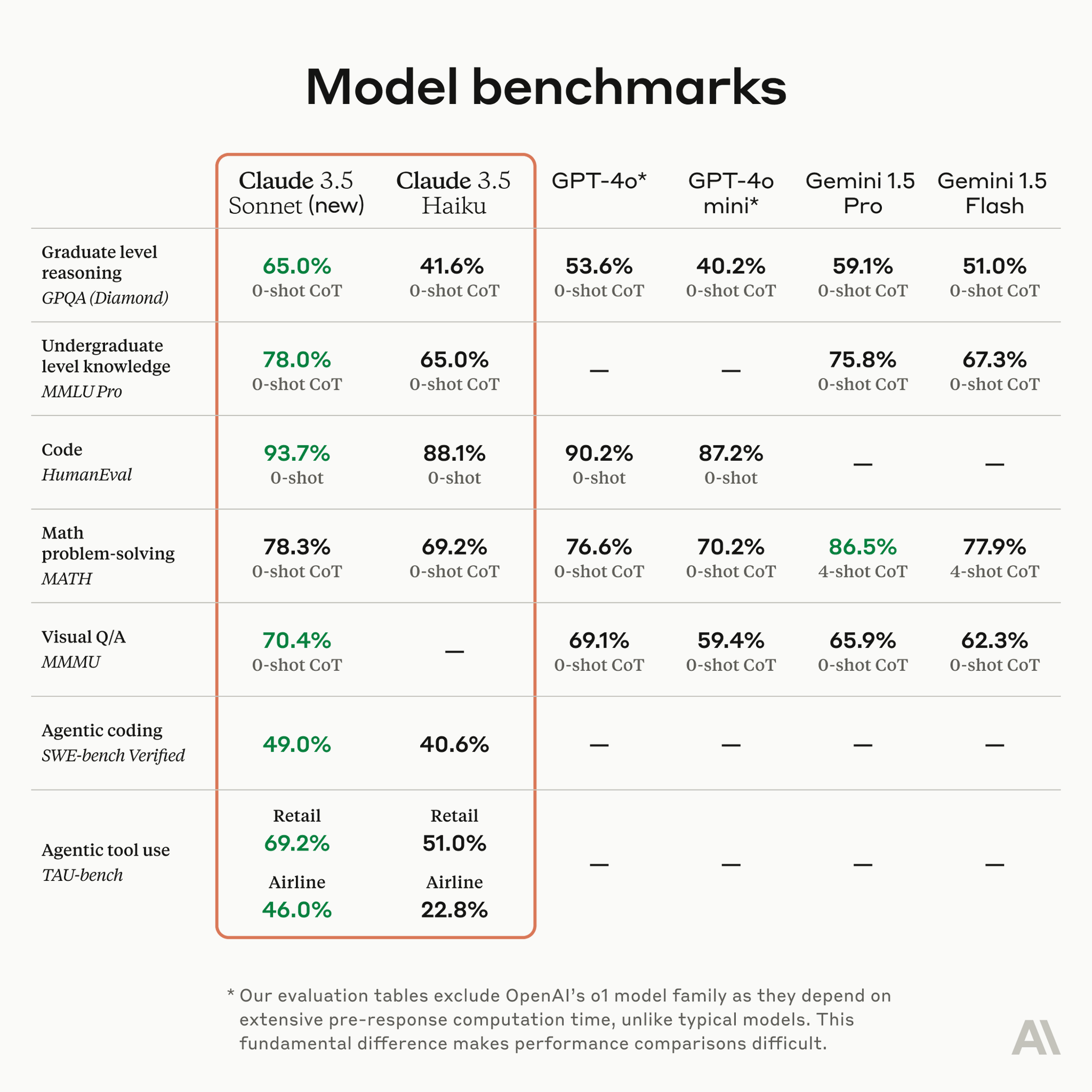




Vivek patel B
•
ONE STOP BUSINESS SOLUTIONS • 3m
GPT-5.1 Instant This default model for everyday ChatGPT use is warmer, more conversational, and playful while staying clear and useful. It excels at instruction following, reliably responding in specified formats like six-word answers, and uses adapt
See More


Siddharth K Nair
Thatmoonemojiguy 🌝 • 8m
🧠🍏 Apple Just Dropped a Bomb on AI Reasoning, “The Illusion of Thinking” Apple’s latest research paper is making waves and not the usual “faster chip, better cam” kind. In The Illusion of Thinking, Apple’s AI team basically said: “Yeah… large la
See More

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.