
Back

Comet
#freelancer • 11m
Difference between previous llms(gpt4o/claude 3.5 sonnet/meta llama) and recent thinking/reasoning llms(o1/o3) Think of older LLMs (like early GPT models) as GPS navigation systems that could only predict the next turn. They were like saying "Based on this road, the next turn is probably right" without understanding the full journey. The problem with RLHF (Reinforcement Learning from Human Feedback) was like trying to teach a driver using only a simple "good/bad" rating system. Imagine rating a driver only on whether they arrived at the destination, without considering their route choices, safety, or efficiency. This limited feedback system couldn't scale well for teaching more complex driving skills. Now, let's understand O1/O3 models: 1. The Tree of Possibilities Analogy: Imagine you're solving a maze, but instead of just going step by step, you: - Can see multiple possible paths ahead - Have a "gut feeling" about which paths are dead ends - Can quickly backtrack when you realize a path isn't promising - Develop an instinct for which turns usually lead to the exit O1/O3 models are trained similarly - they don't just predict the next step, they develop an "instinct" for exploring multiple solution paths simultaneously and choosing the most promising ones. 2. The Master Chess Player Analogy: - A novice chess player thinks about one move at a time - A master chess player develops intuition about good moves by: * Seeing multiple possible move sequences * Having an instinct for which positions are advantageous * Quickly discarding bad lines of play * Efficiently focusing on the most promising strategies O1/O3 models are like these master players - they've developed intuition through exploring countless solution paths during training. 3. The Restaurant Kitchen Analogy: - Old LLMs were like a cook following a recipe step by step - O1/O3 models are like experienced chefs who: * Know multiple ways to make a dish * Can adapt when ingredients are missing * Have instincts about which techniques will work best * Can efficiently switch between different cooking methods if one isn't working The "parallel processing" mentioned (like O1-pro) is like having multiple expert chefs working independently on different aspects of a meal, each using their expertise to solve their part of the problem. To sum up: O1/O3 models are revolutionary because they're not just learning to follow steps (like older models) or respond to simple feedback (like RLHF models). Instead, they're developing sophisticated instincts for problem-solving by exploring and evaluating many possible solution paths during their training. This makes them more flexible and efficient at finding solutions, similar to how human experts develop intuition in their fields.
More like this
Recommendations from Medial










Baqer Ali
AI agent developer |... • 9m
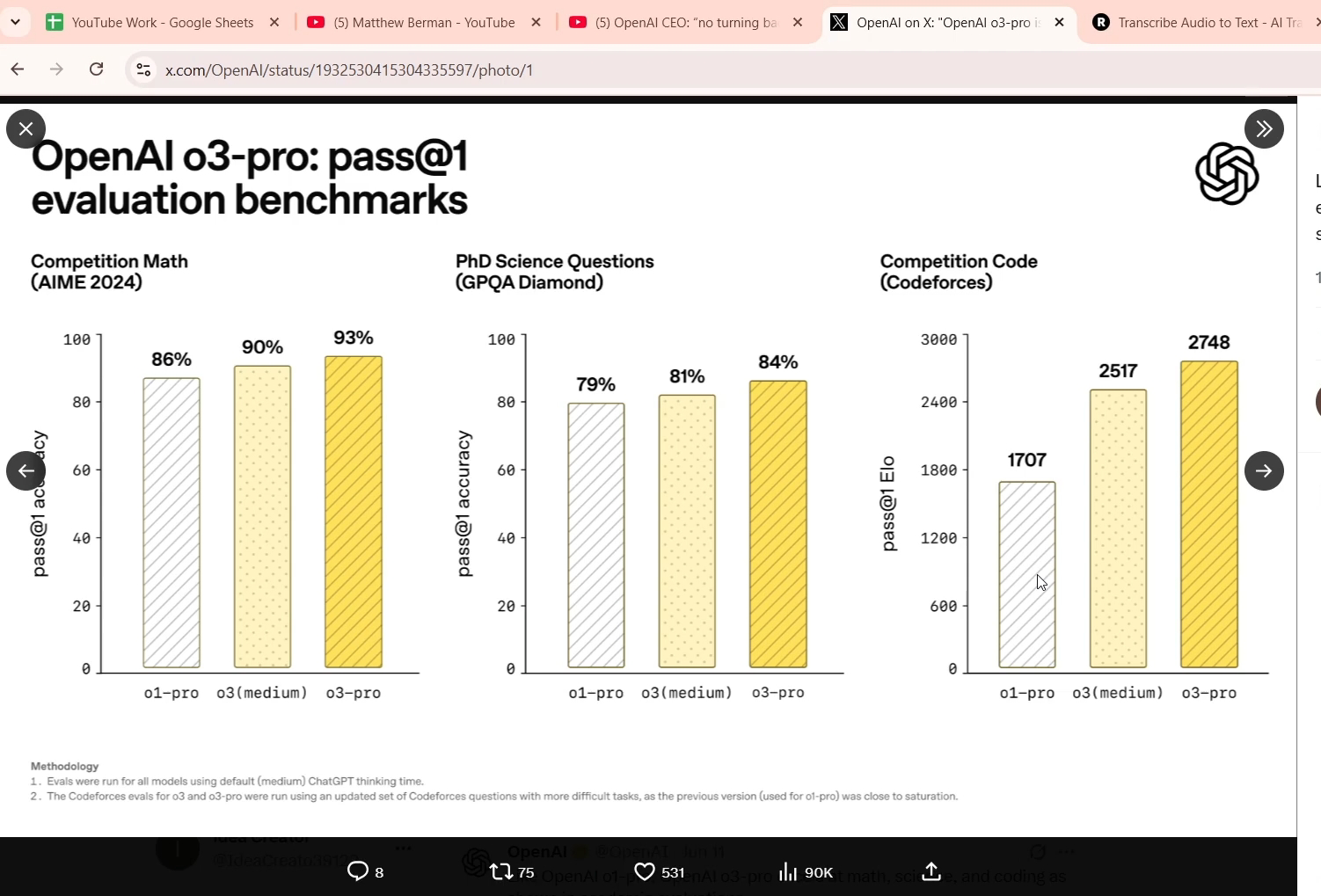
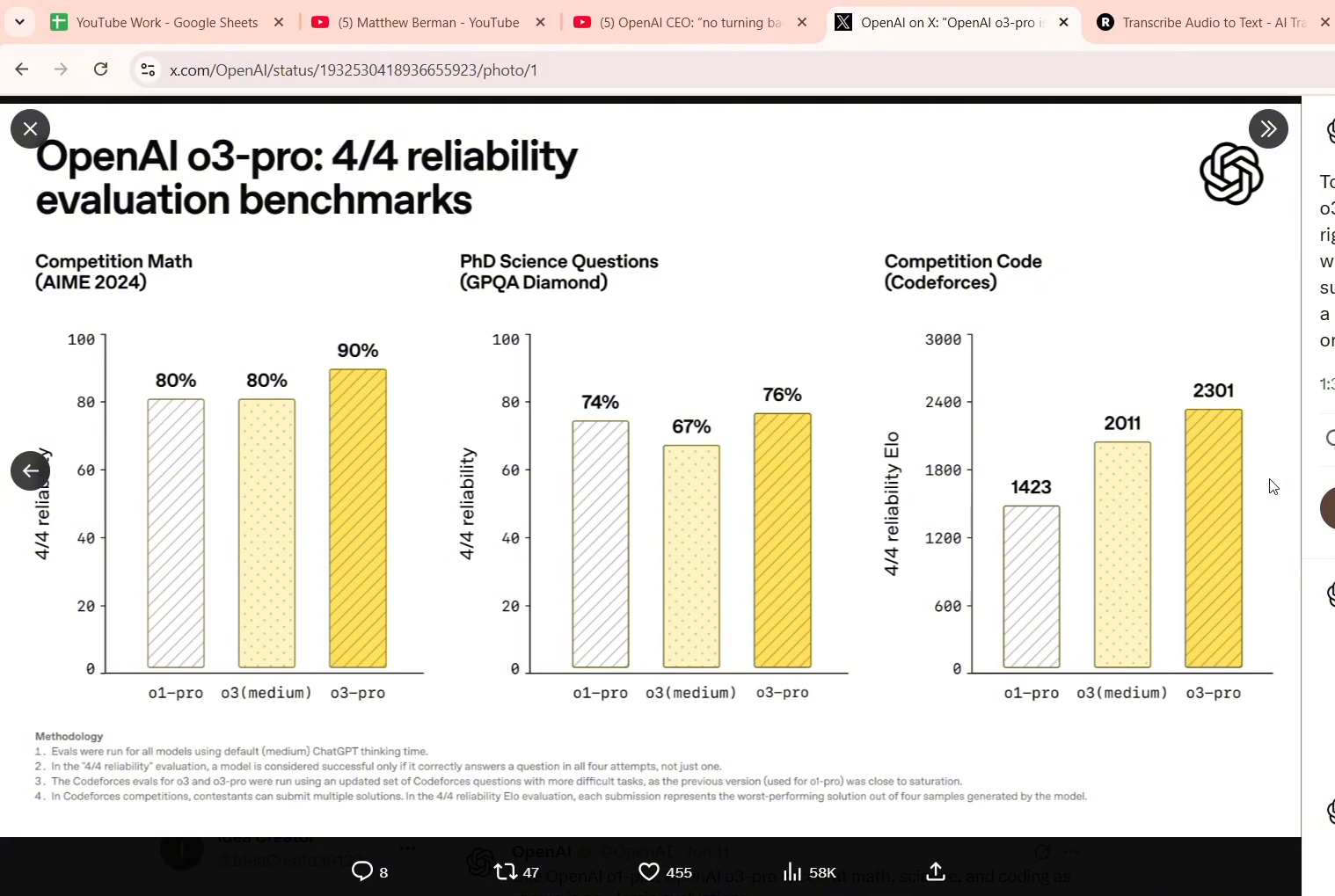
Open ai has released the o3 pro model which is well enough to replace a senior software developer To make things worse it can be the foundational steps towards AGI by open ai First for the newbies we have two types of models Two types of models
See More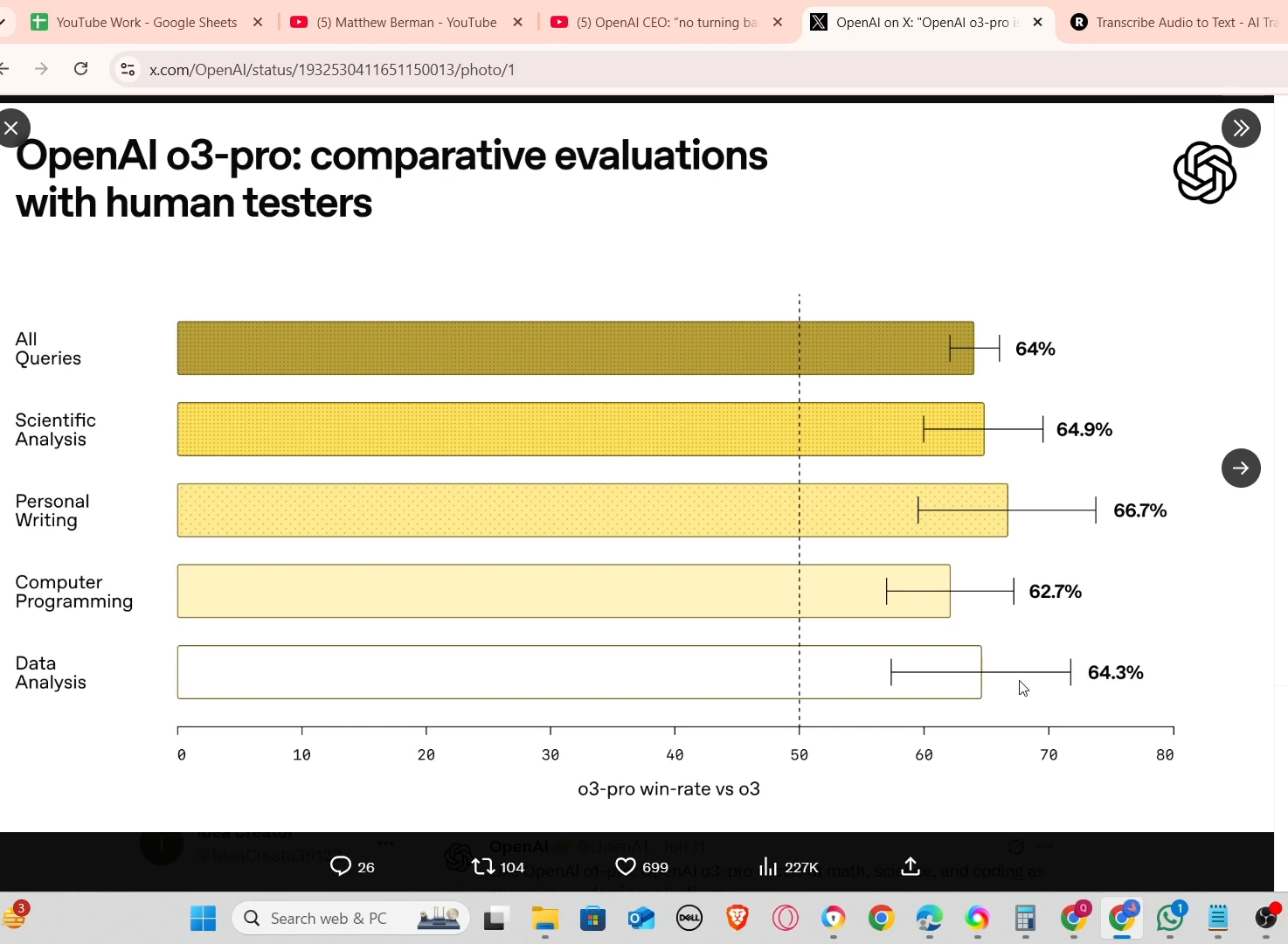

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.