
Back

Bhoop Singh Gurjar
AI Deep Explorer | f... • 1y
A (Long) Peek into Reinforcement Learning How do AI agents master games like Go, control robots, or optimize trading strategies? The answer lies in Reinforcement Learning (RL)—where agents learn by interacting with environments to maximize rewards. Key Concepts: ✓Agent & Environment: The agent takes actions; the environment responds. ✓States & Actions: The agent moves between states by choosing actions. ✓Rewards & Policy: Rewards guide learning; a policy defines the best action strategy. ✓Value Function & Q-Value: Measures how good a state/action is in terms of future rewards. ✓MDPs & Bellman Equations: Most RL problems follow Markov Decision Processes (MDPs), solved using Bellman equations. Solving RL Problems: ✓Dynamic Programming: Requires a known model, iteratively improves policies. ✓Monte-Carlo Methods: Learn from complete episodes. ✓TD Learning (SARSA, Q-Learning, DQN): Learns from incomplete episodes, bootstraps value estimates. ✓Policy Gradient (REINFORCE, A3C): Directly optimizes policies using gradient ascent. ✓Evolution Strategies: Model-agnostic, inspired by natural selection. Challenges: ✓Exploration-Exploitation Tradeoff: Balancing new knowledge vs. maximizing rewards. ✓Deadly Triad: Instability when combining off-policy learning, function approximation, and bootstrapping. Case Study: AlphaGo Zero ✓DeepMind’s AlphaGo Zero achieved superhuman Go-playing skills using self-play and Monte Carlo Tree Search (MCTS), without human supervision. link :https://lilianweng.github.io/posts/2018-02-19-rl-overview/
More like this
Recommendations from Medial
Bhoop Singh Gurjar
AI Deep Explorer | f... • 11m
Having worked on Reinforcement Learning, it’s always fascinating to see how it’s being applied in the world of LLMs. If you’re curious about how RL powers modern LLM agents, especially in areas like reward modeling, and policy gradients here are a f
See More
Bhoop Singh Gurjar
AI Deep Explorer | f... • 11m
Give me 2 minutes, I will tell you How to Learn Reinforcement Learning for LLMs A humorous analogy for reinforcement learning uses cake as an example. Reinforcement learning, much like baking a cake, involves trial and error to achieve a desired ou
See MoreBhoop Singh Gurjar
AI Deep Explorer | f... • 11m
LLM Post-Training: A Deep Dive into Reasoning LLMs This survey paper provides an in-depth examination of post-training methodologies in Large Language Models (LLMs) focusing on improving reasoning capabilities. While LLMs achieve strong performance
See More

Rahul Agarwal
Founder | Agentic AI... • 4m
If AI’s rapid pace feels overwhelming, trust me-everyone feels it. New models, new papers, new frameworks… it’s impossible to keep up with everything. And the good news is-you don’t have to. What actually helps is a clear path, not more noise. So I
See MoreRahul Agarwal
Founder | Agentic AI... • 2m
Most people miss these principles while building AI agents. I’ve explained everything that you should keep in mind. 1. Never run an agent without clear context. 2. Define who the agent is and what it is responsible for. 3. Always log inputs, action
See More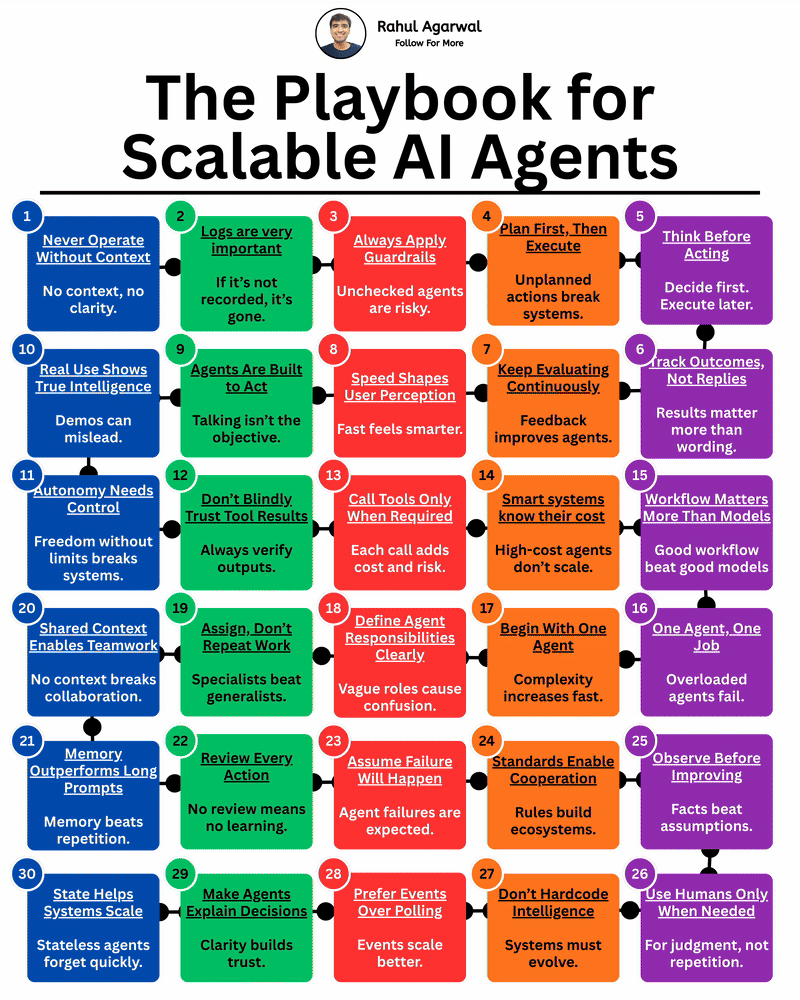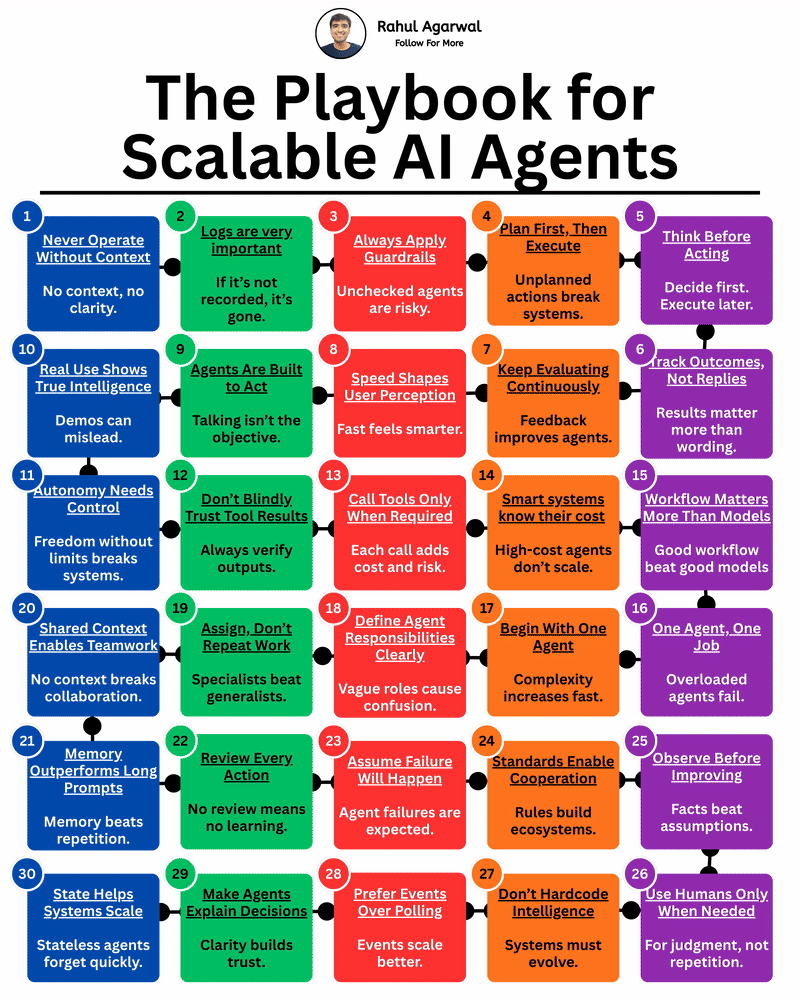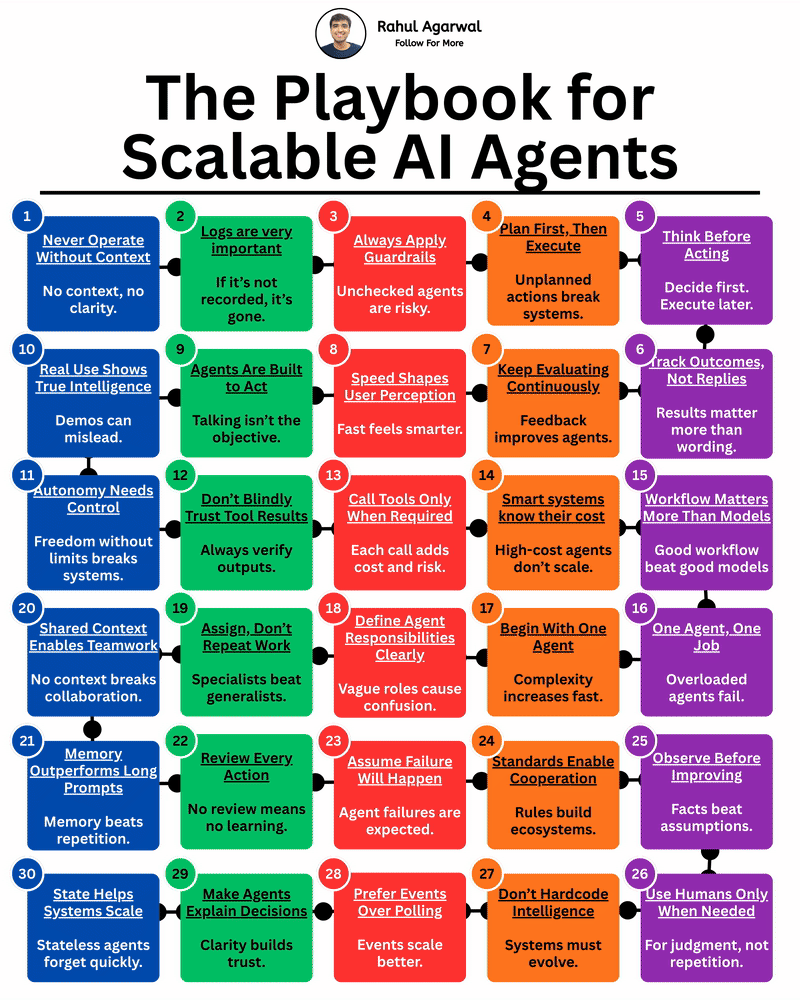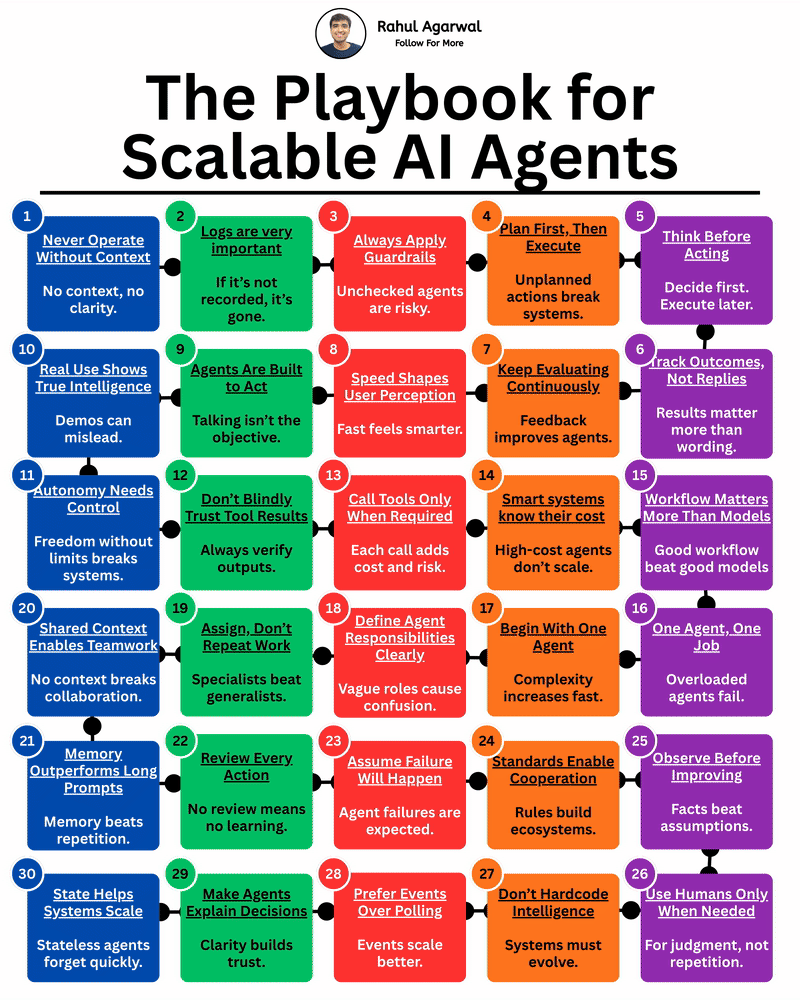
Rahul Agarwal
Founder | Agentic AI... • 2m
Real Agentic AI is a multi-layered system, where each layer solves a specific challenge from reasoning to compliance: 1. LLM (Core Reasoning) – Handles language understanding and generation. Alone, not enterprise-ready. 2. RAG (Retrieval Layer) – G
See MoreRahul Agarwal
Founder | Agentic AI... • 3m
Deconstructing How Agentic AI Actually Works We’ve all experienced what Large Language Models can do — but Agentic AI is the real leap forward. Instead of just generating responses, it can understand goals, make decisions, and take action on its own
See More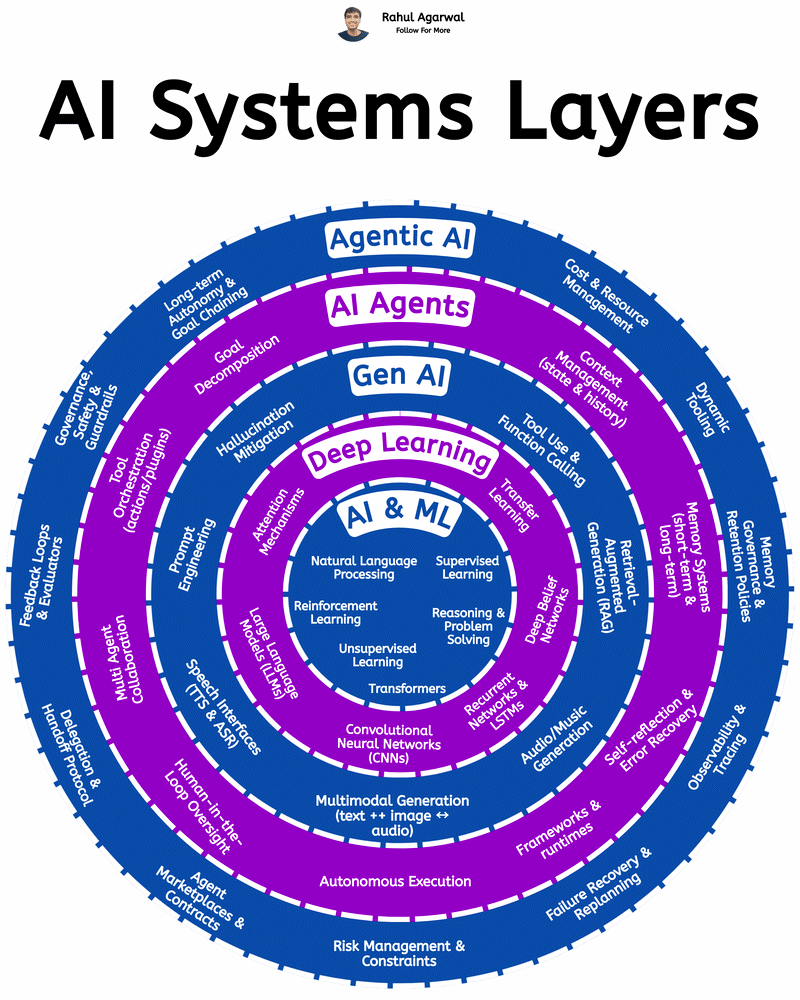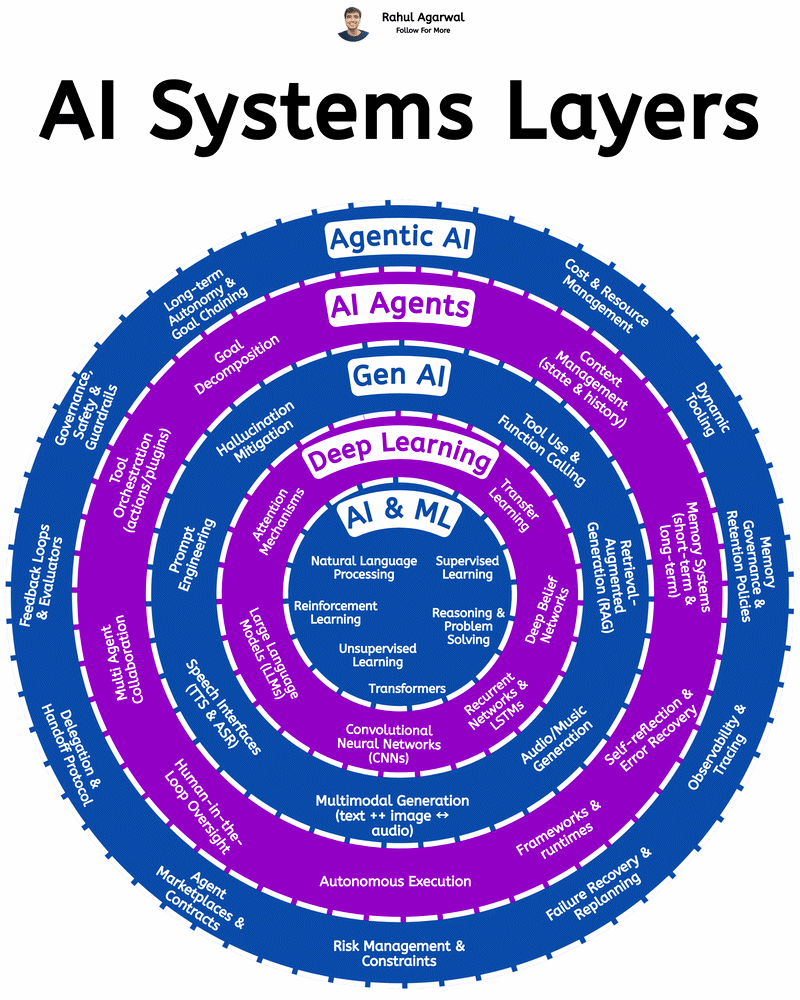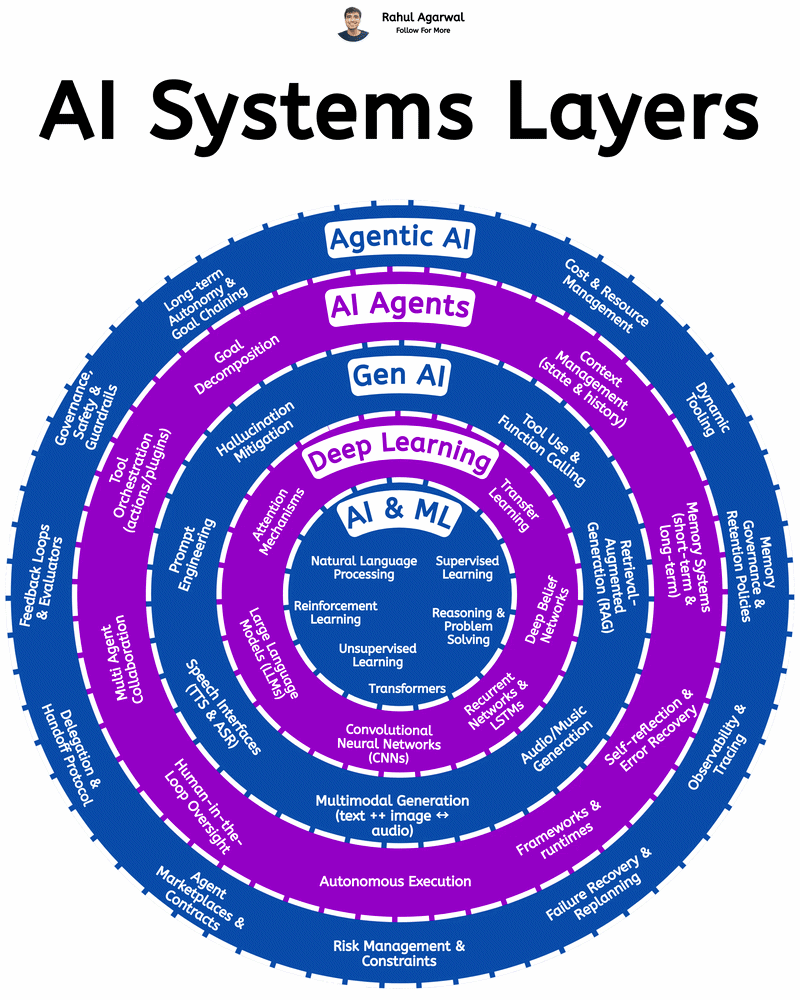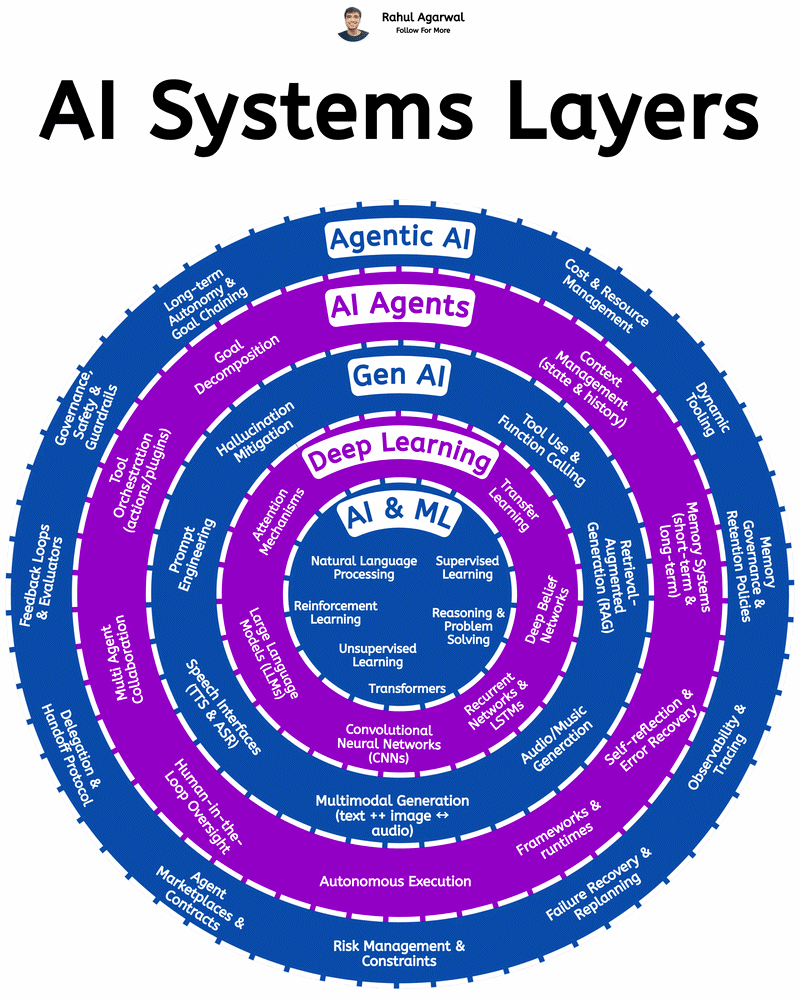

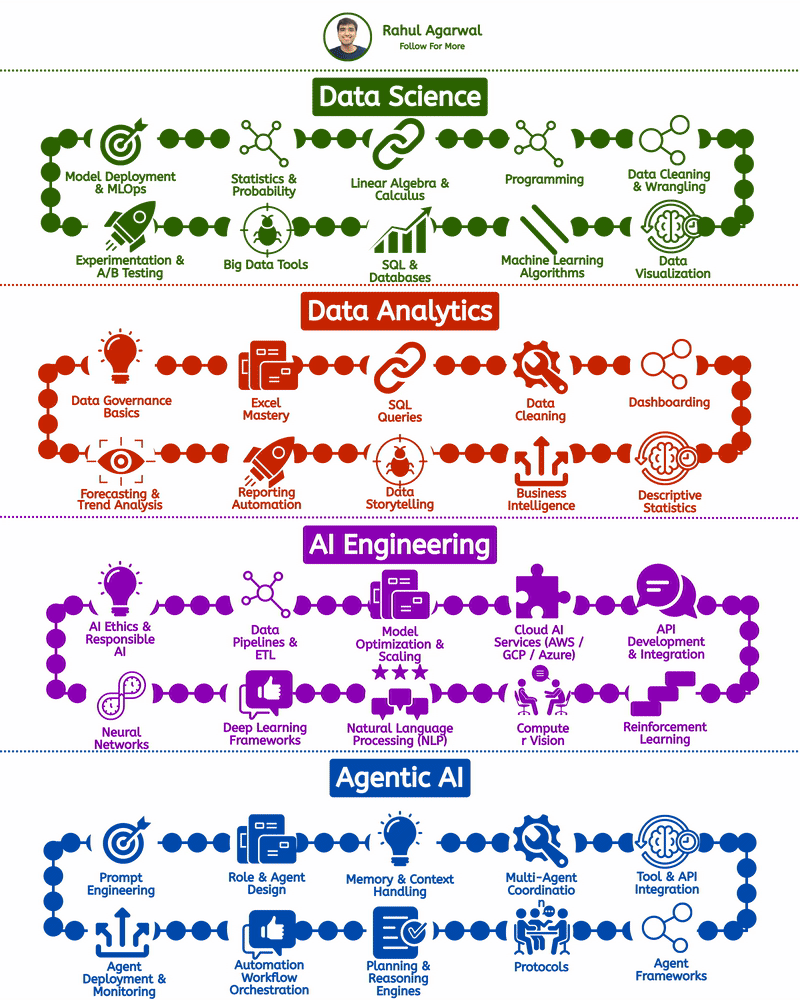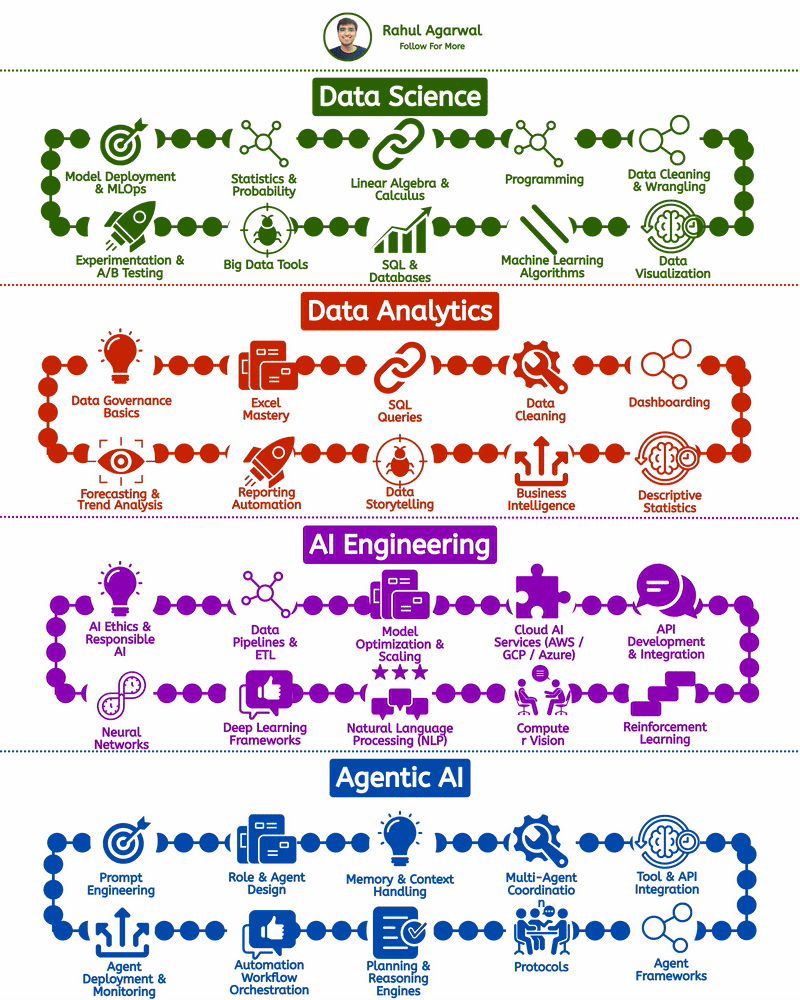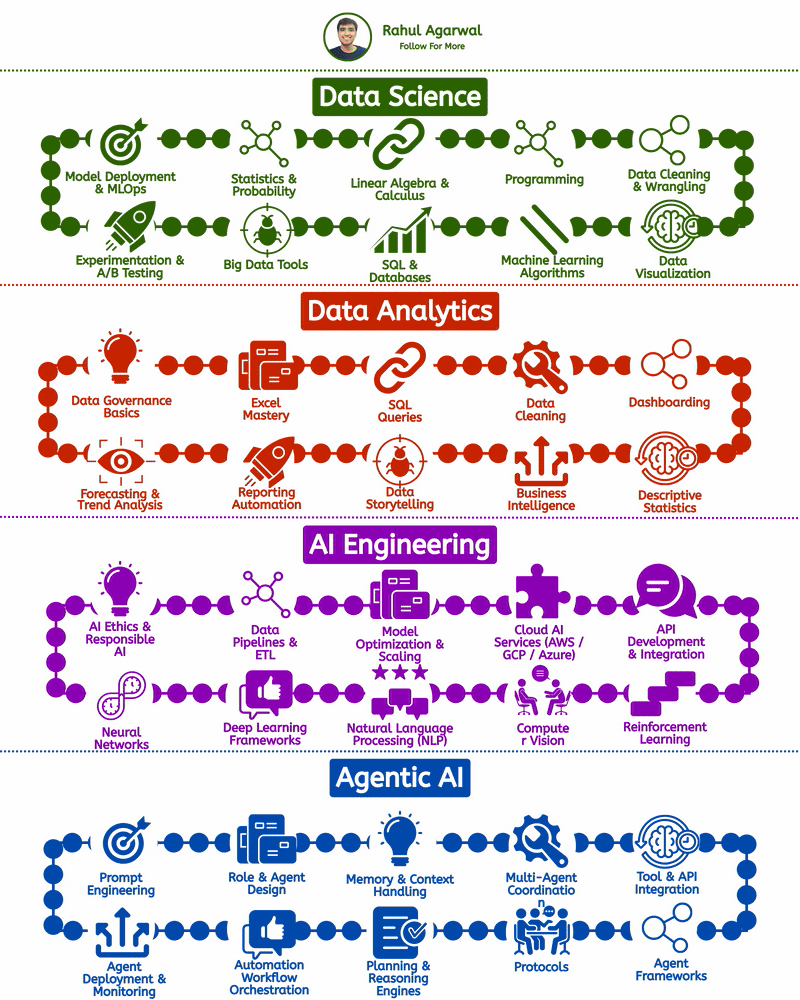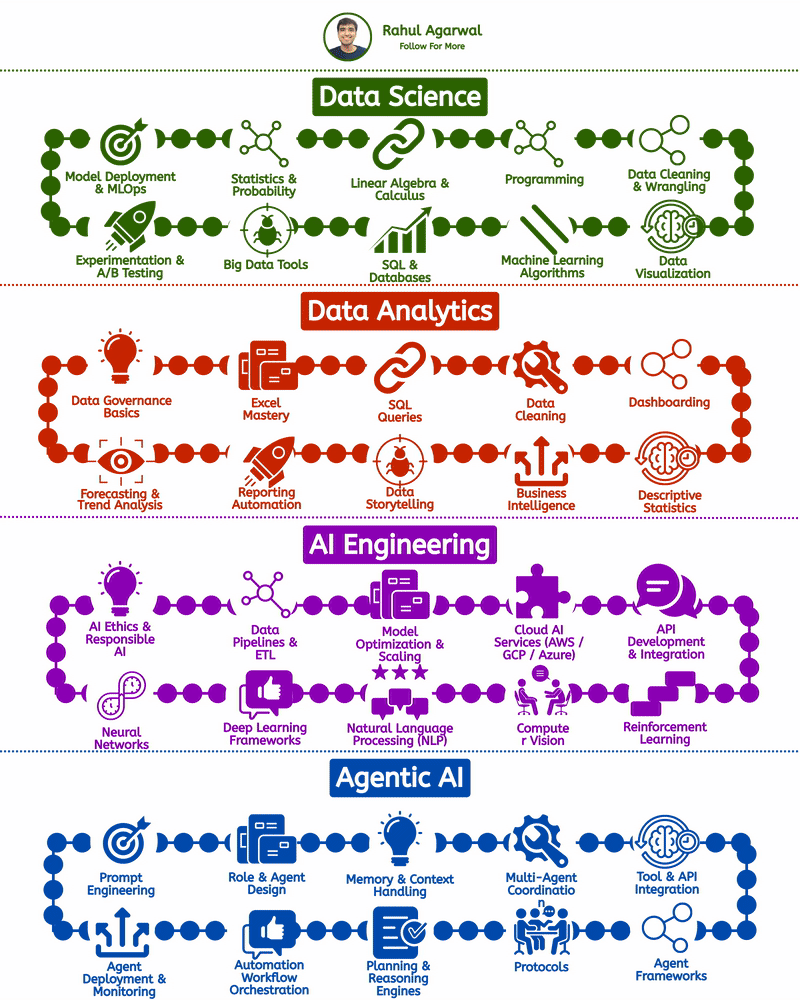

/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)

























Download the medial app to read full posts, comements and news.