Building JalSeva and... • 1y
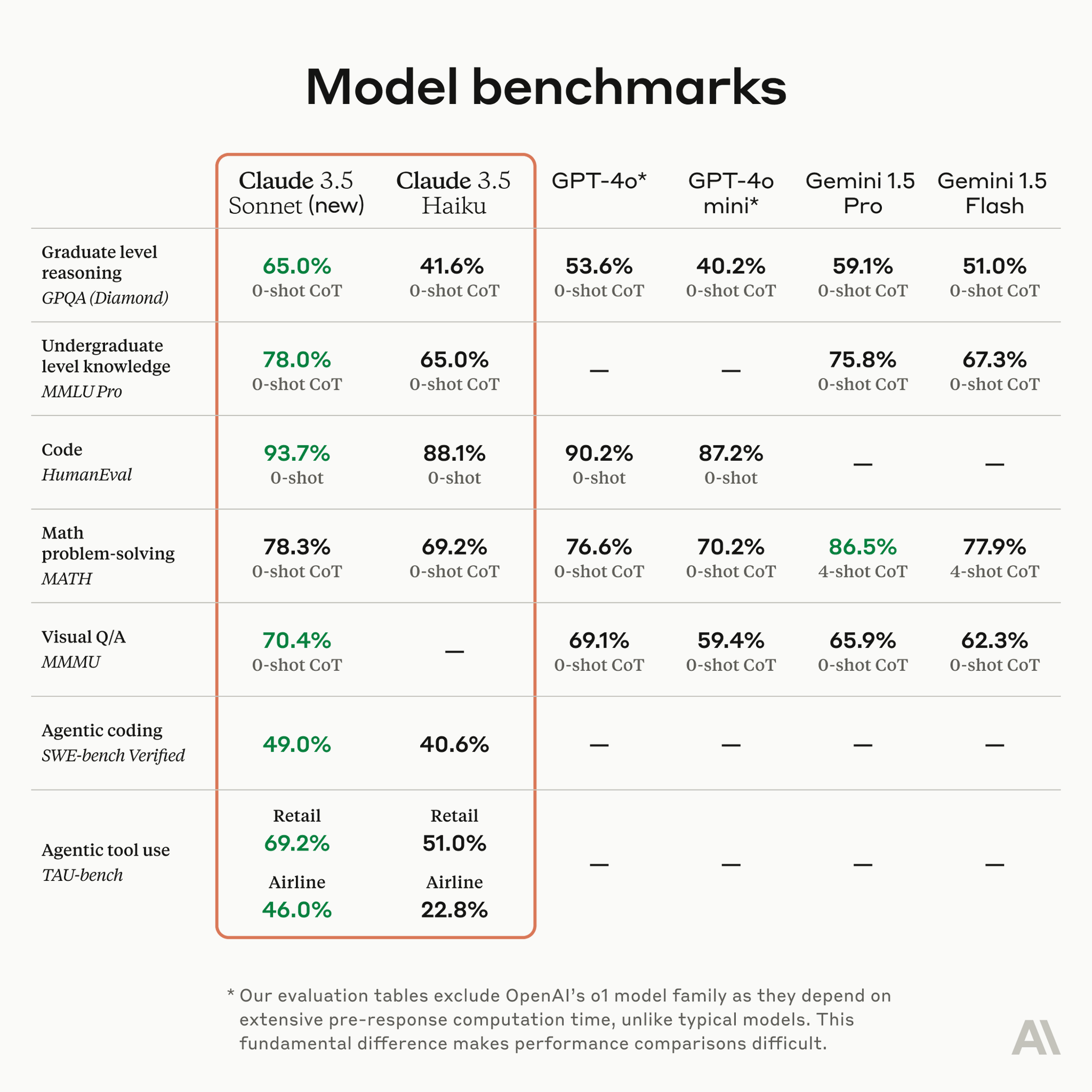
AI Model Performance Benchmarks: 🚀 Comparing Claude, GPT-4o, and Gemini Across Key Tasks with Claude 3.5 Sonnet performing best overall, especially in code (93.7%) and reasoning (65.0%). Gemini 1.5 Pro excels in math (86.5% with 4-shot CoT). GPT-
Figuring Out • 1y
now compare that with O1
•
Medial • 1y
O1 is way too good
💯💯
Hey I am on Medial • 1y
fact 💯 Rahul malodia 🔥🔥🔥 must watch 💯
💯
Just looking around ... • 1y
Hi everyone,A 18 yea... • 8m
Great 💯
☝️💯
Hakuna matata • 1y
😂 💯
19 | Founder & CEO @... • 1y
century 💯
Introvert! • 11m
Totally 💯
Follow the dream.✨ • 8m
yep....💯
Navi AI Bags $6 Million in Fundin ...
Unicorn India Ventures leads Rs 1 ...
CurrentClient Raises $1.25 Millio ...
Download the medial app to read full posts, comements and news.




















/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)





















