
Back

Shuvodip Ray
•
YouTube • 1y
Researchers at Google DeepMind introduced Semantica, an image-conditioned diffusion model capable of generating images based on the semantics of a conditioning image. The paper explores adapting image generative models to different datasets. Instead of finetuning each model, which is impractical for large-scale models, Semantica uses in-context learning. It is trained on web-scale image pairs, where one random image from a webpage is used to condition the generation of another image from the same page, assuming these images share semantic traits
Replies (2)

More like this
Recommendations from Medial






Arpan Dholakiya
Hey I am on Medial • 1y
🚀 Hiring for Generative AI Engineer (Remote) 🚀 AI-based SaaS company in the health sector seeks Generative AI Engineer. Requirements: - 1-3 years of experience in Generative AI - Expertise in LLMs and Diffusion Models - Strong foundation in compu
See More


Divyam Gupta
Building products, l... • 10m
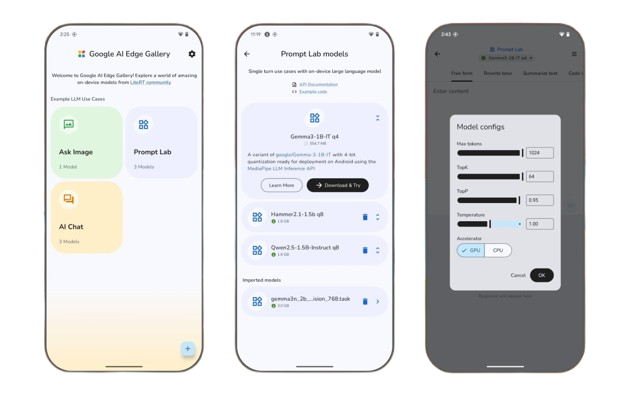
Google Unveils AI Edge Gallery: On-Device Generative AI Without Internet Google has launched the AI Edge Gallery, an experimental app that brings cutting-edge Generative AI models directly to your Android device. Once a model is downloaded, all proc
See More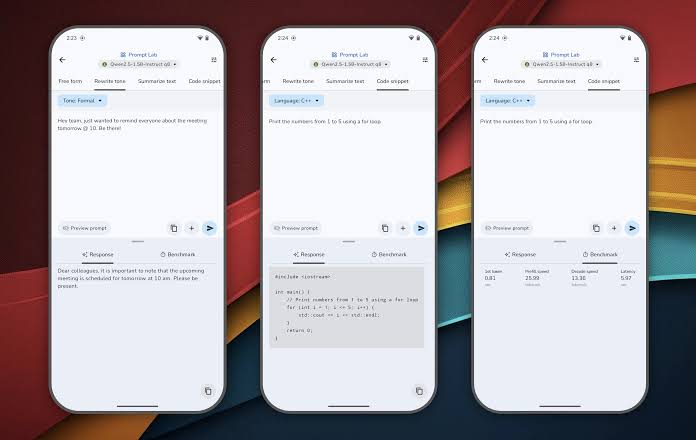

Rahul Agarwal
Founder | Agentic AI... • 3m
8 common LLM types used in modern agent systems. 1) GPT (Generative Pretrained Transformer) Core model for many agents, strong in language understanding, generation, and instruction following. 2) MoE (Mixture of Experts) Routes tasks to specialized
See More


Bhoop Singh Gurjar
AI Deep Explorer | f... • 11m
Top 10 AI Research Papers Since 2015 🧠 1. Attention Is All You Need (Vaswani et al., 2017) Impact: Introduced the Transformer architecture, revolutionizing natural language processing (NLP). Key contribution: Attention mechanism, enabling models
See More


Three Commas Gang
Building Bharat • 1y
AI solution for marketers and product sellers! Building a webapp for you to just upload product image, and input a prompt and voila!!! You can get studio quality images instantly in any orientation and style possible. Will this work better in subsc
See More







/entrackr/media/post_attachments/wp-content/uploads/2021/08/Accel-1.jpg)
























Download the medial app to read full posts, comements and news.