
Back

Rahul Agarwal
Founder | Agentic AI... • 4h
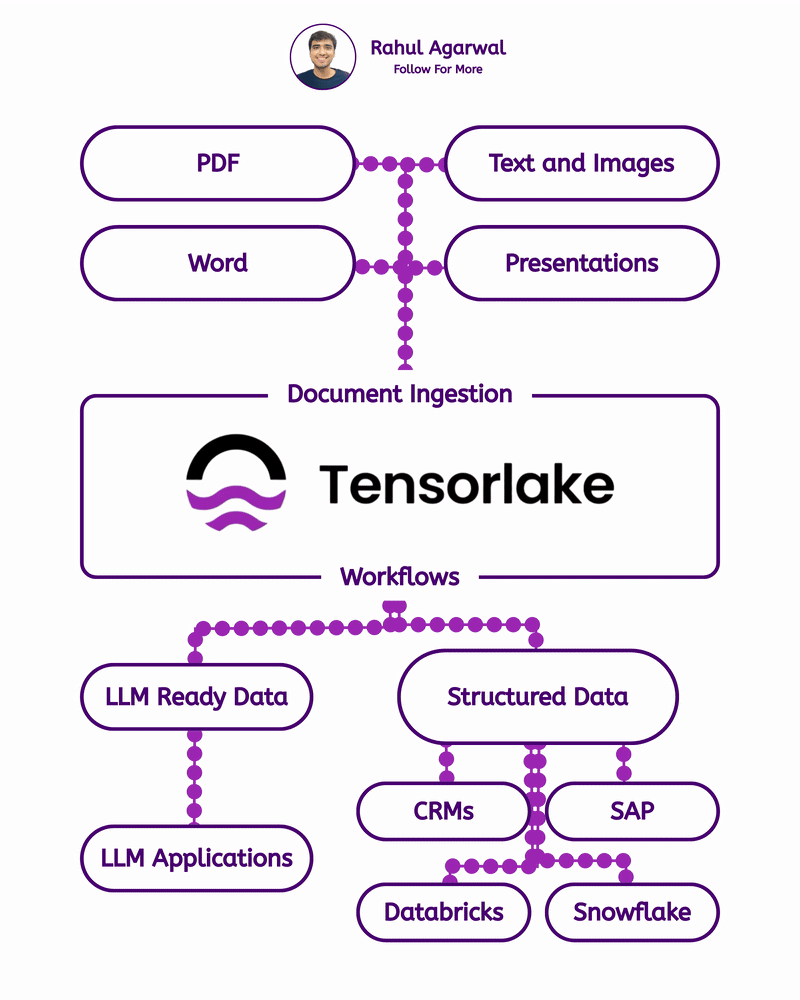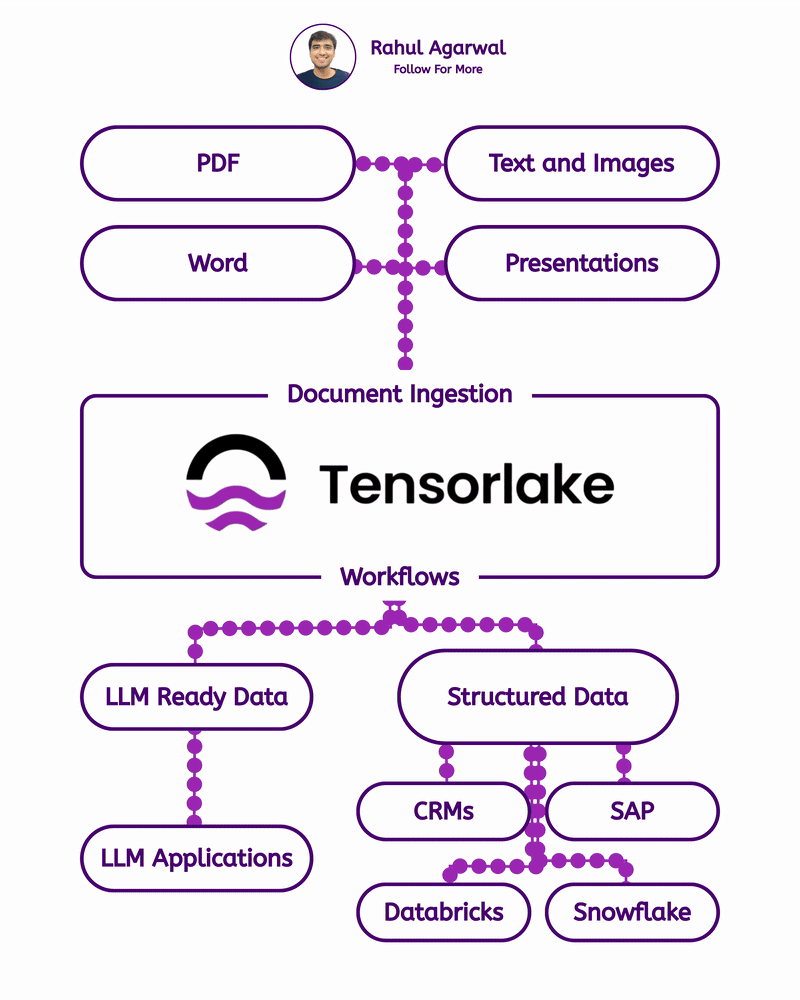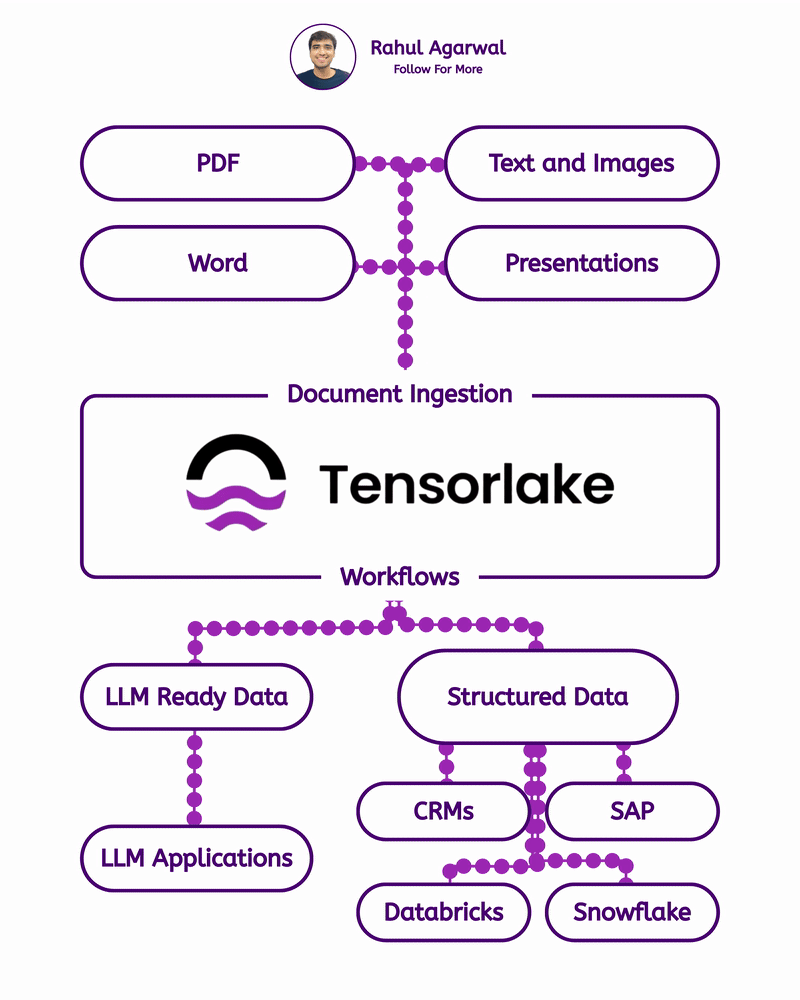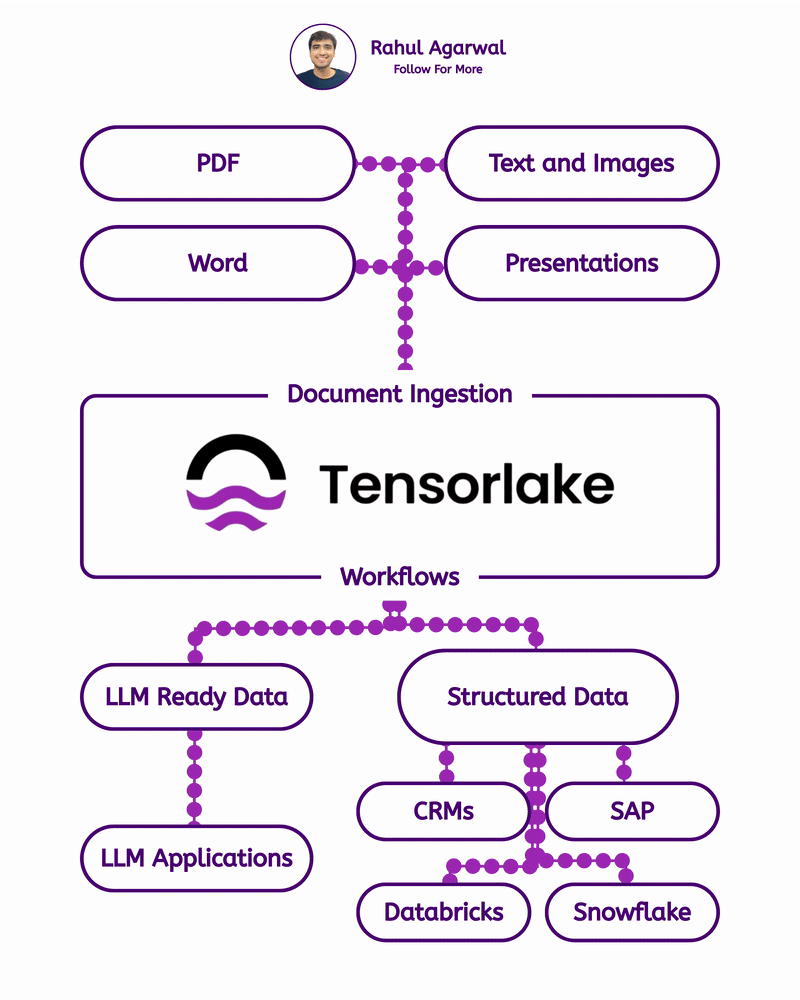
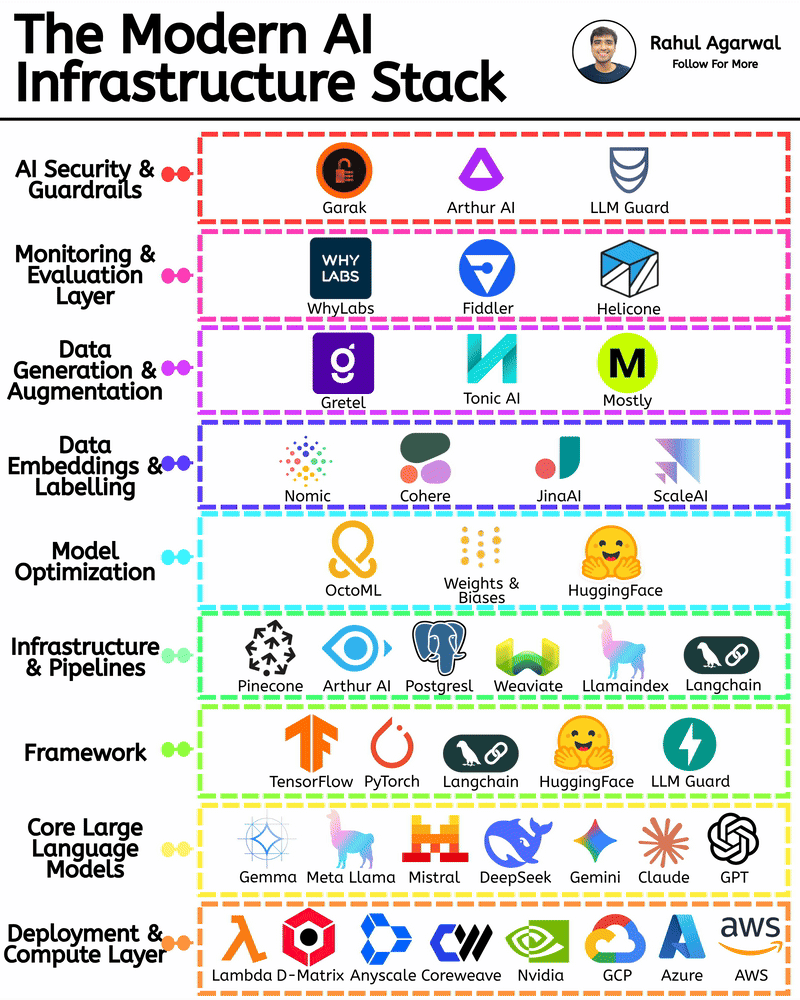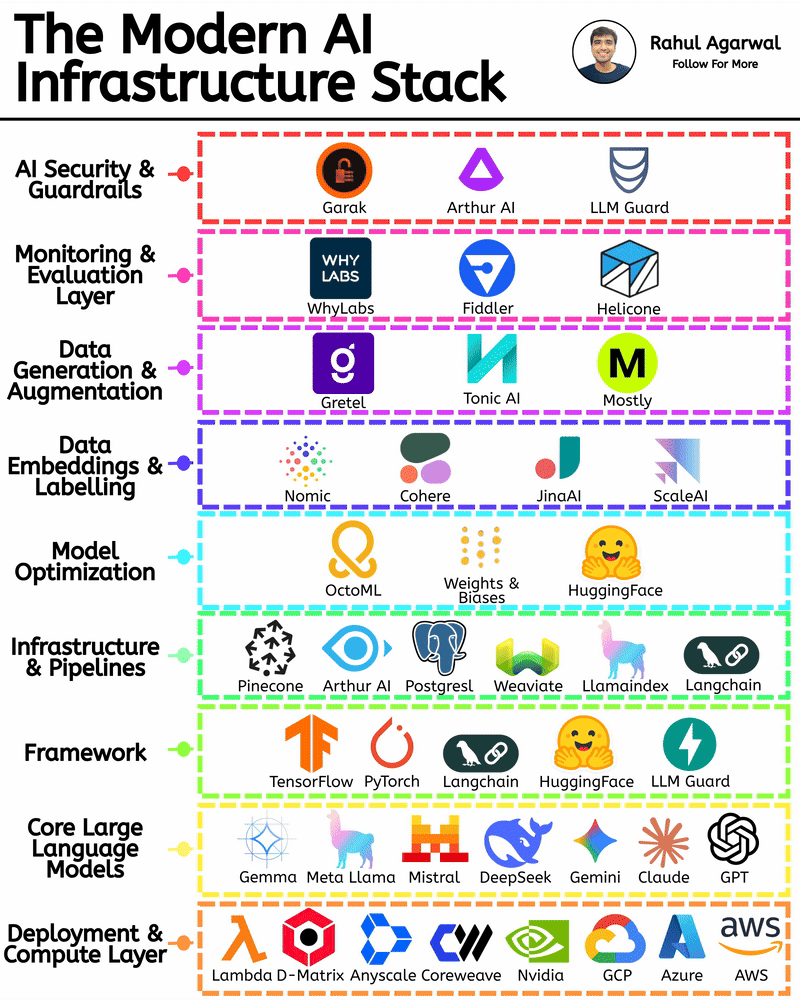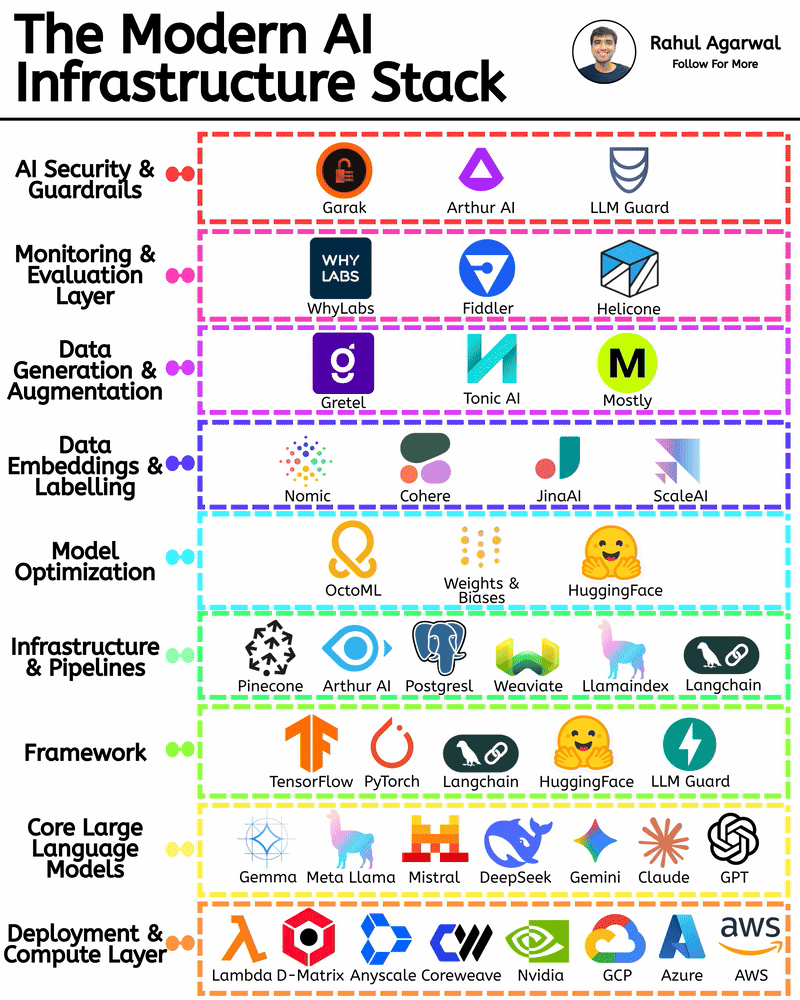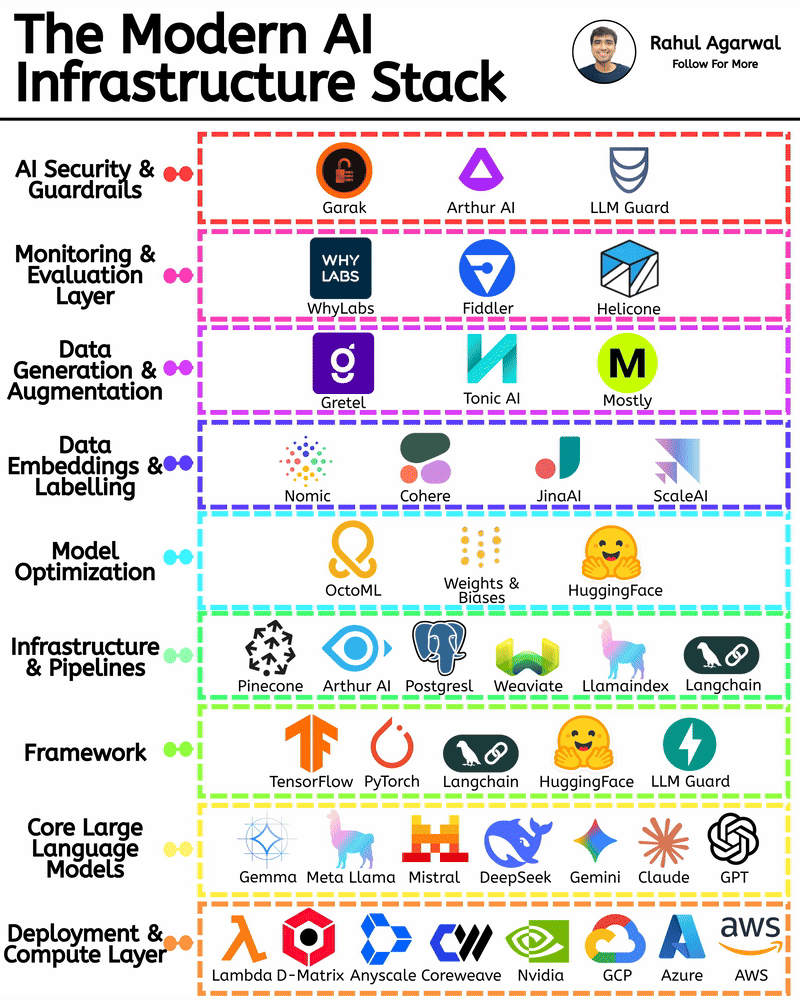
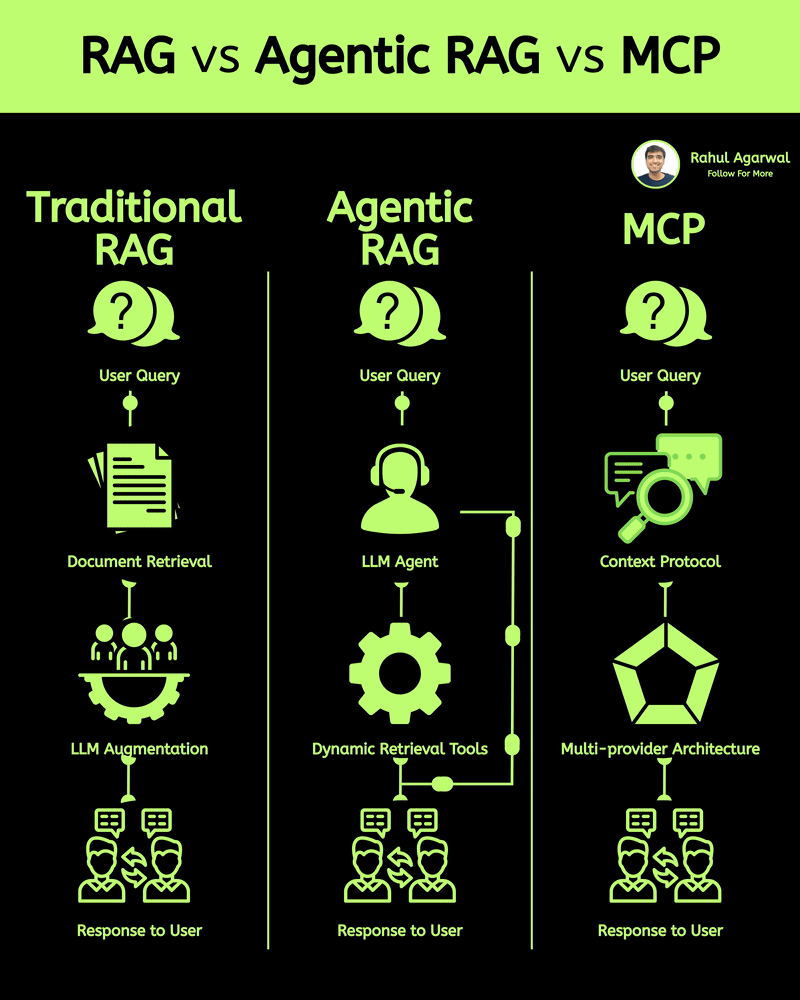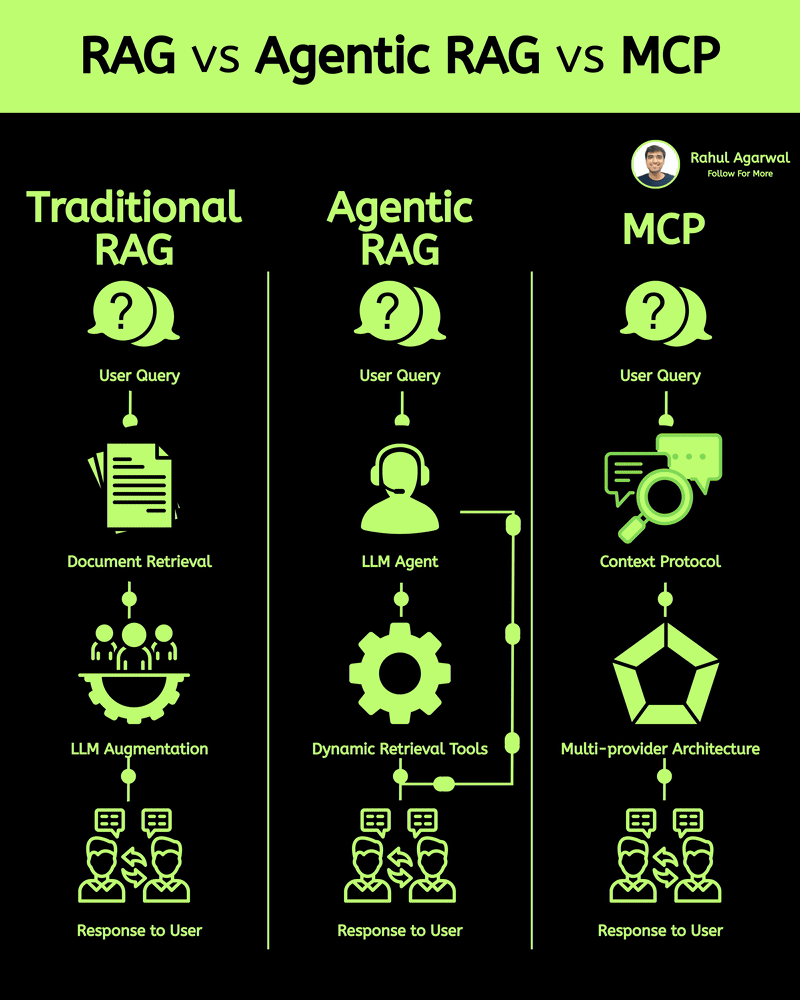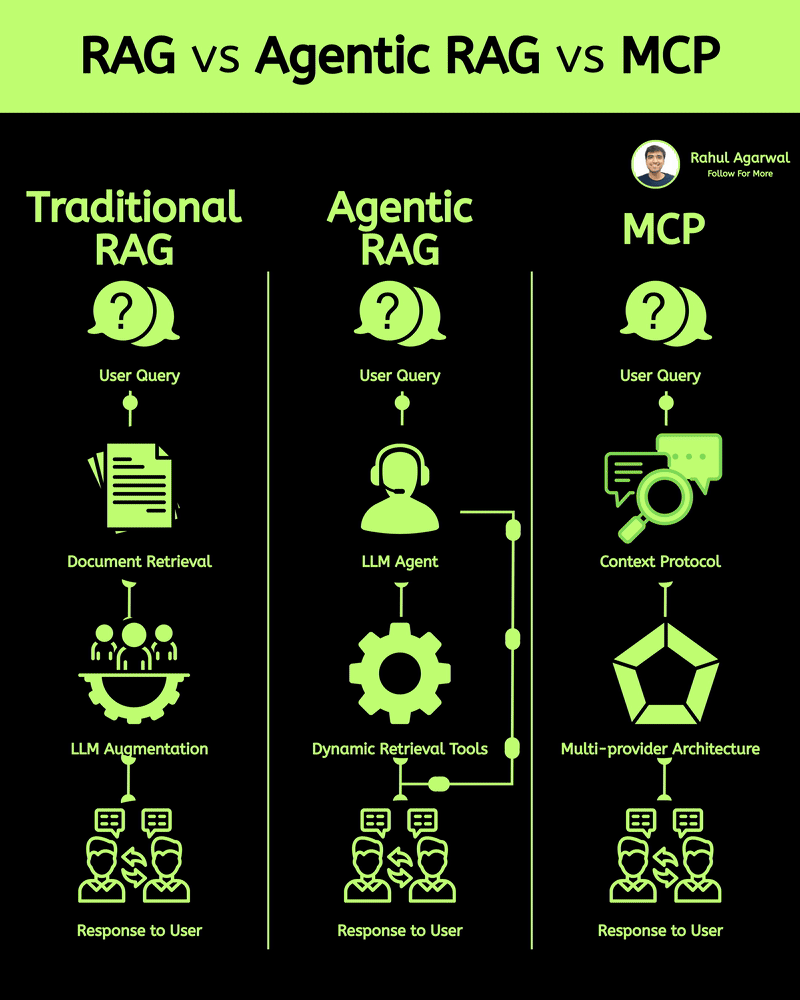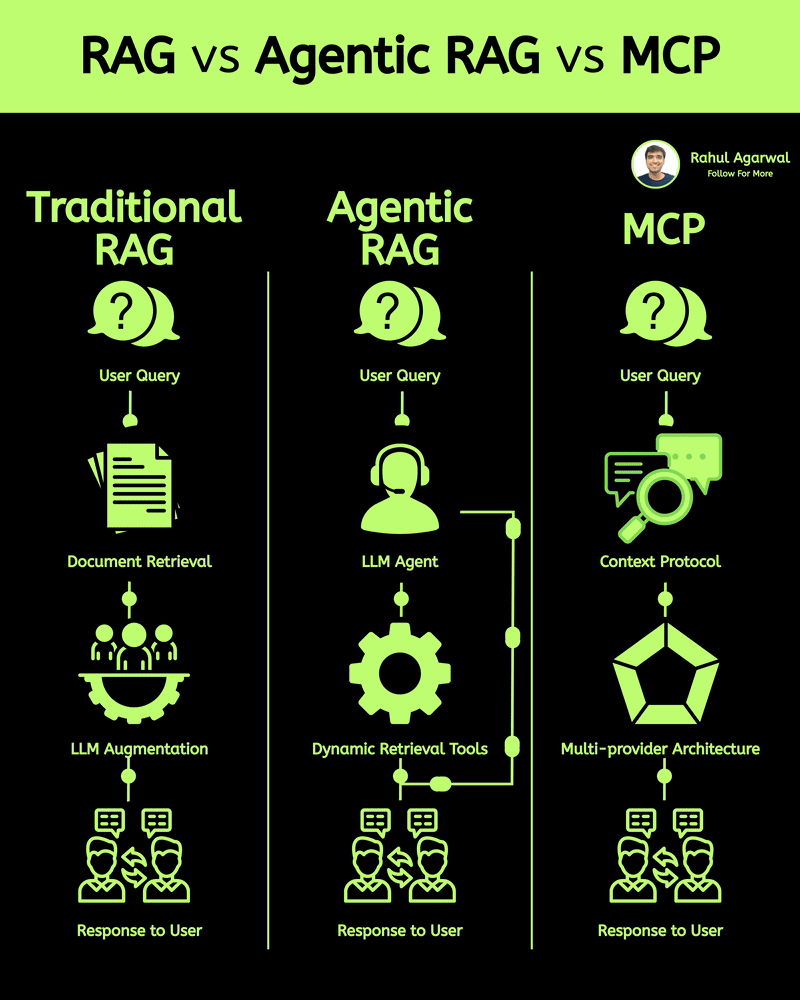
Get RAG-ready data from any unstructured document. This is crazy for AI companies. I've explained below. 𝗦𝘁𝗲𝗽 1 – 𝗨𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱 𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁𝘀 (𝗧𝗵𝗲 𝗦𝗼𝘂𝗿𝗰𝗲) • Real-world PDFs and documents are messy. Tables, images, signatures, headings, random layouts. • You can’t directly use them for LLMs or RAG systems. • Tensorlake starts by taking in any complex document (reports, invoices, forms, etc.). 𝗦𝘁𝗲𝗽 2 – 𝗦𝗰𝗵𝗲𝗺𝗮 𝗗𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻 (𝗪𝗵𝗮𝘁 𝗗𝗮𝘁𝗮 𝗬𝗼𝘂 𝗪𝗮𝗻𝘁) • You simply tell Tensorlake 𝗲𝘅𝗮𝗰𝘁𝗹𝘆 𝘄𝗵𝗶𝗰𝗵 𝗳𝗶𝗲𝗹𝗱𝘀 𝘆𝗼𝘂 𝘄𝗮𝗻𝘁 𝗲𝘅𝘁𝗿𝗮𝗰𝘁𝗲𝗱. • Example: “invoice_number”, “total_amount”, “date”, “address”, etc. • This prevents irrelevant data from being processed and keeps everything clean. 𝗦𝘁𝗲𝗽 3 – 𝗦𝗺𝗮𝗿𝘁 𝗣𝗮𝗴𝗲 𝗖𝗹𝗮𝘀𝘀𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻 (𝗙𝗶𝗻𝗱𝗶𝗻𝗴 𝗧𝗵𝗲 𝗥𝗶𝗴𝗵𝘁 𝗣𝗮𝗴𝗲𝘀) • Extracting across the 𝗲𝗻𝘁𝗶𝗿𝗲 𝗱𝗼𝗰𝘂𝗺𝗲𝗻𝘁 is slow and inaccurate. • Tensorlake automatically 𝗶𝗱𝗲𝗻𝘁𝗶𝗳𝗶𝗲𝘀 𝘄𝗵𝗶𝗰𝗵 𝗽𝗮𝗴𝗲 𝗰𝗼𝗻𝘁𝗮𝗶𝗻𝘀 𝘁𝗵𝗲 𝗱𝗮𝘁𝗮 𝘆𝗼𝘂 𝗻𝗲𝗲𝗱. • This increases speed, accuracy, and reduces hallucinations. 𝗦𝘁𝗲𝗽 4 – 𝗔𝗱𝘃𝗮𝗻𝗰𝗲𝗱 𝗟𝗮𝘆𝗼𝘂𝘁 𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱𝗶𝗻𝗴 (𝗟𝗶𝗸𝗲 𝗛𝘂𝗺𝗮𝗻 𝗣𝗮𝗿𝘀𝗶𝗻𝗴) • Traditional OCR treats documents as flat text. • Tensorlake reads documents 𝗹𝗶𝗸𝗲 𝗵𝘂𝗺𝗮𝗻𝘀 by understanding: -> Tables -> Figures -> Paragraphs -> Sections -> Signatures -> Bounding boxes This ensures highly accurate extraction even from messy PDFs. 𝗦𝘁𝗲𝗽 5 – 𝗘𝗻𝗮𝗯𝗹𝗲 𝗖𝗶𝘁𝗮𝘁𝗶𝗼𝗻𝘀 (𝗣𝗿𝗼𝗼𝗳 𝗼𝗳 𝗪𝗵𝗲𝗿𝗲 𝗗𝗮𝘁𝗮 𝗖𝗮𝗺𝗲 𝗙𝗿𝗼𝗺) • Tensorlake gives 𝗲𝘅𝗮𝗰𝘁 𝗰𝗶𝘁𝗮𝘁𝗶𝗼𝗻𝘀 + 𝗯𝗼𝘂𝗻𝗱𝗶𝗻𝗴 𝗯𝗼𝘅𝗲𝘀 for every extracted field. • This means your LLM can 𝘀𝗵𝗼𝘄 𝘁𝗵𝗲 𝗲𝘅𝗮𝗰𝘁 𝘀𝗼𝘂𝗿𝗰𝗲 for every answer. • Greatly reduces hallucination and makes your system audit-ready. 𝗦𝘁𝗲𝗽 6 – 𝗘𝘅𝘁𝗿𝗮𝗰𝘁 & 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 (𝗖𝗹𝗲𝗮𝗻 𝗟𝗟𝗠-𝗥𝗲𝗮𝗱𝘆 𝗗𝗮𝘁𝗮) With API calls, Tensorlake gives you: • Clean structured data • Markdown of the full doc • Relevant pages • Citations + bounding boxes • This output is 𝗱𝗶𝗿𝗲𝗰𝘁𝗹𝘆 𝗥𝗔𝗚-𝗿𝗲𝗮𝗱𝘆, no cleanup needed. 𝗦𝘁𝗲𝗽 7 – 𝗙𝗲𝗲𝗱 𝗶𝘁 𝘁𝗼 𝗬𝗼𝘂𝗿 𝗟𝗟𝗠 (𝗣𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻-𝗚𝗿𝗮𝗱𝗲 𝗤𝘂𝗲𝗿𝗶𝗲𝘀) With accurate, structured, citation-backed data, your LLM now: • Gives reliable answers • Shows exactly where info came from • Can be deployed in real workflows • This is the difference between a 𝗱𝗲𝗺𝗼 and a 𝗿𝗲𝗮𝗹 𝘀𝘆𝘀𝘁𝗲𝗺. ✅ 𝗙𝗶𝗻𝗮𝗹 𝗙𝗹𝗼𝘄 1. Upload messy documents 2. Define what data you want 3. Tensorlake identifies relevant pages 4. It deeply understands layout (like a human) 5. Extracts structured data with citations 6. Outputs RAG-ready content 7. Feed to your LLM for trustworthy answers ✅ Repost for others in your network who want to build 𝗥𝗔𝗚-𝗱𝗿𝗶𝘃𝗲𝗻 𝗔𝗜 𝘀𝘆𝘀𝘁𝗲𝗺𝘀.
More like this
Recommendations from Medial








Nikhil Raj Singh
Entrepreneur | Build... • 8m
Founders, don’t overlook this! If you're raising funds, having a well-structured Data Room is a game-changer. It shows investors you're professional, transparent, and ready to scale, making the due diligence process smoother and faster. Here’s what
See More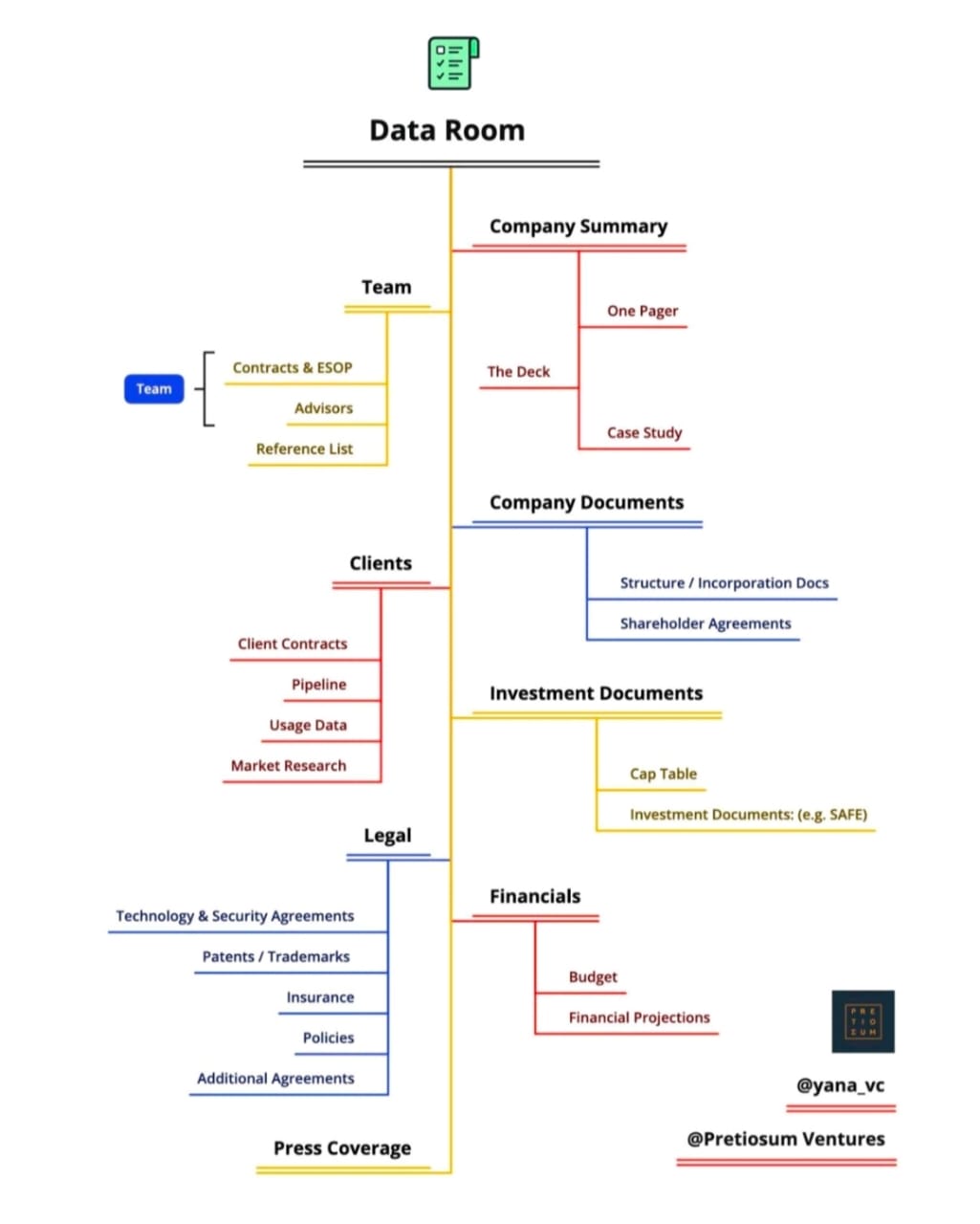

Abdul Shaikh
Every Dream is Worth... • 8m
🚫 Al Agents Are Coming-90% Will Fail Without This Key Factor Al agents promise seamless automation and intelligent decision-making, but their effectiveness hinges on one crucial factor: high-quality data. Without clean, structured, and accessible
See More
HEMANT GHUGE
Problem Zeroth, Tech... • 4m
Most people think of RAG (Retrieval-Augmented Generation) as a text-only thing. But when we apply it to images, it unlocks serious potential — especially in safety, retail, and surveillance. I recently explored Vision-RAG using Weaviate + LangChain
See More



























Download the medial app to read full posts, comements and news.