
Back

Subhajit Mandal
Software Developer • 20d
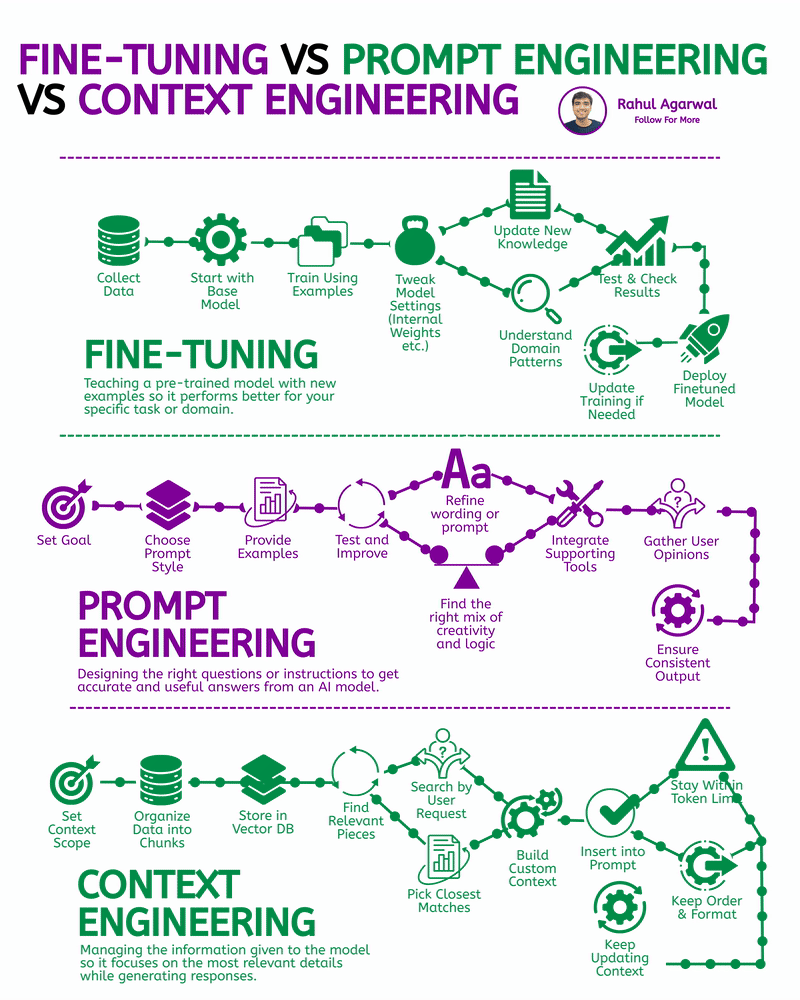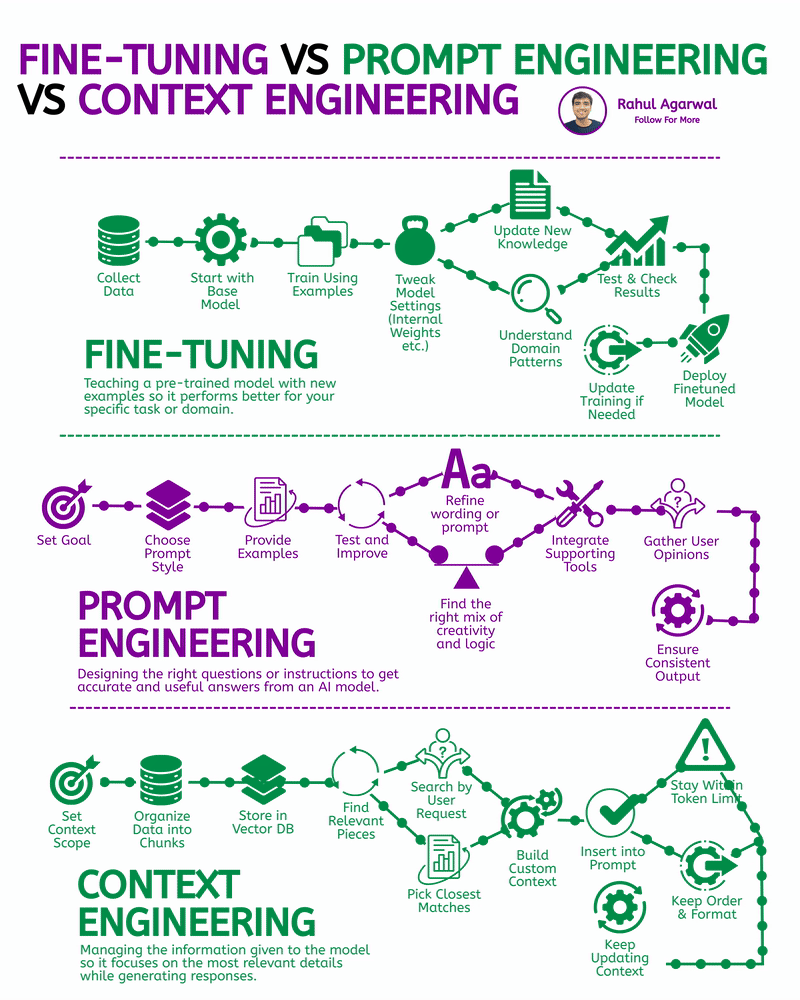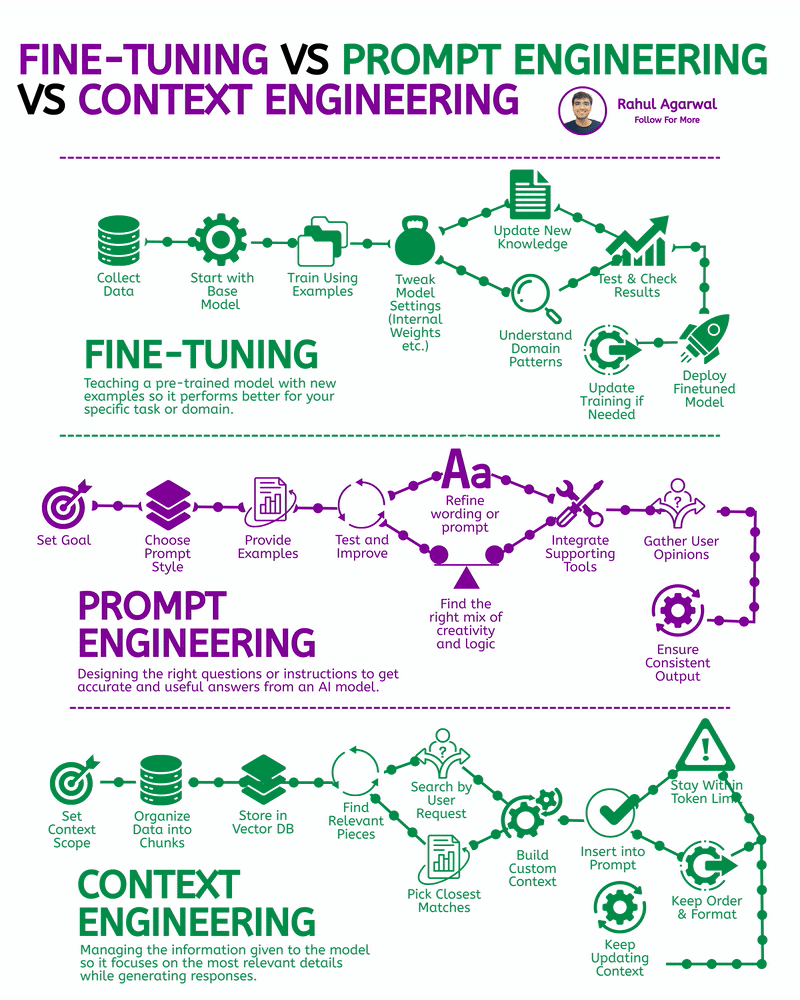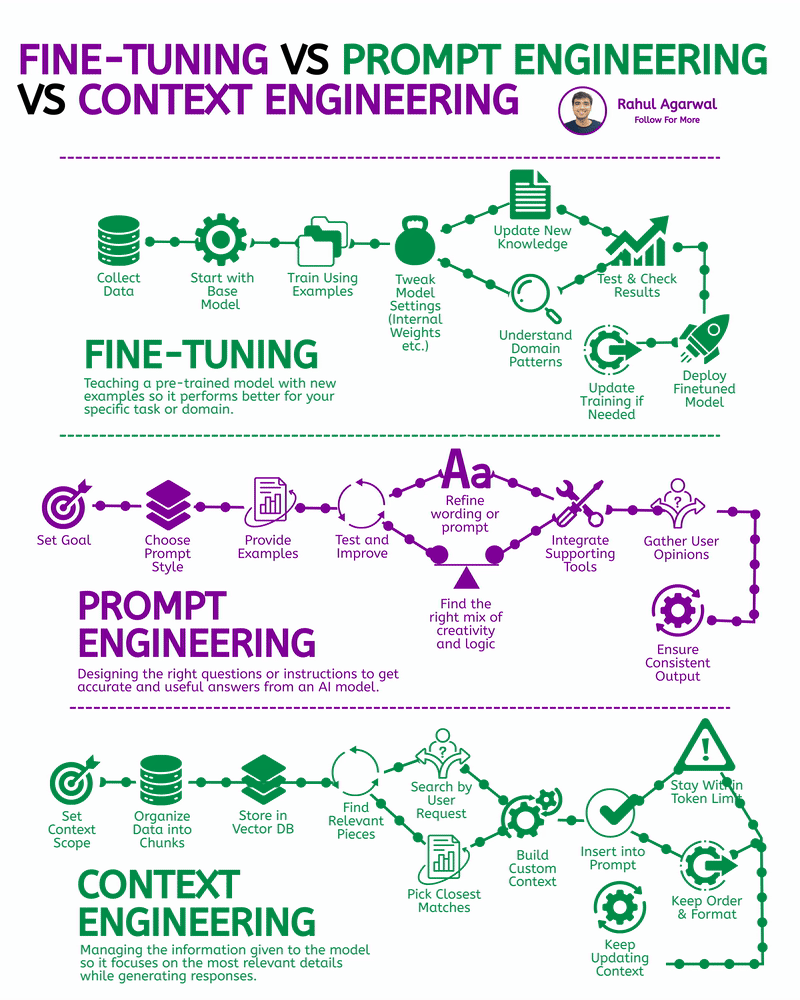
1. LoRA on a reasonably small open model (best balance for small compute): apply low-rank adapters (PEFT/LoRA). Requires less GPU memory and works well for 700–3000 rows. 2. Full fine-tune (costly / heavy): only if you have >A100 GPU or cloud paid GPU. Not recommended for early MVP. 3. No-fine-tune alternative (fast & free): use retrieval + prompting (RAG) — keep base LLM and add context from your 3k+ rows. Great when compute is limited.
More like this
Recommendations from Medial






AI Engineer
AI Deep Explorer | f... • 5m
LLM Post-Training: A Deep Dive into Reasoning LLMs This survey paper provides an in-depth examination of post-training methodologies in Large Language Models (LLMs) focusing on improving reasoning capabilities. While LLMs achieve strong performance
See MoreAI Engineer
AI Deep Explorer | f... • 6m
"A Survey on Post-Training of Large Language Models" This paper systematically categorizes post-training into five major paradigms: 1. Fine-Tuning 2. Alignment 3. Reasoning Enhancement 4. Efficiency Optimization 5. Integration & Adaptation 1️⃣ Fin
See More


Animesh Kumar Singh
Hey I am on Medial • 2m
The "AI Personality Forge: Product :"Cognate" Cognate is not an AI assistant. It's a platform on your phone or computer that lets you forge, train, and deploy dozens of tiny, specialized AI "personalities" for specific tasks in seconds. How it wo
See More

Venkatesh
Bussiness Developmen... • 10m
Winning Against the Odds: How One Small Business Secured a Tender A Dream Worth Pursuing Ravi Kumar, the founder of BuildRight Constructions, had always dreamed of taking on larger projects. However, competing against industry giants felt impossible
See More

Tarun Suthar
CA Inter | CS Execut... • 1m
🚀 "Artificial Intelligence Trends Report" by "Mary Meeker" 🚀 The AI Window Is Now: Where Founders Should Build in 2025-2030.. The BOND AI Trends 2025 report is one of the most data-rich looks at how Artificial Intelligence is reshaping the global
See More
























Download the medial app to read full posts, comements and news.